Нейронные сети на графах
@tany_savelieva @tldr_arxivВ чем суть?
Cети на графах становятся все популярнее как в науке, так и в индустрии. Краткий обзор по методам и конкретным примерам применения графовых нейронок для тех, кто давно хотел разобраться, но стеснялся загуглить. Графовые нейросети используются не только при обработке соцсетей, молекул и в физических задачах, но и в более неочевидных ситуациях - например, при zero-shot learning на картинках. Большая часть информации взята из недавнего обзора, ссылки на другие статьи можно найти ниже.
Как понять, что мне нужна сетка на графах?
- Структурированный случай
Самый естественный случай - данные имеют структуру графа. Например, нужно классифицировать графы - молекулы лекарств, чтобы понять, помогут ли они воздействовать на нужный рецептор, связанный с заболеванием. Вершины графа - молекулы с их физико-химическими признаками, ребра обозначают, что между двумя молекулами есть связь + в весах ребер можно отразить силу связи.
В случае соцсетей мы обычно хотим давать предсказание не для всего графа, а для конкретных вершин - например, предсказать, купит ли конкретный пользователь определенный товар, если показать ему рекламу, или нет. Кроме задачи классификации - когда из набора кандидатов-лекарств нужно выбрать самое эффективное, можно решать задачу генерации - подобрать подходящее лекарство в отсутствие кандидатов. Также можно решать задачу кластеризации - выделять из соцсетей сообщества, для того, чтобы планировать рекламную кампанию.
2. Более сложный случай
Сырые данные не имеют графовой структуры, но их можно превратить в граф и улучшить качество на некоторых задачах.
Пример - классификация картинок в задаче zero-shot learning (построить классификатор по категории без примеров картинок этой категории). В статье строят граф того, как категории соотносятся друг с другом. Например, кошка - это млекопитающее, значит вершина "кошка" будет соединена с вершиной . "млекопитающие". Затем, как представление вершины берут w2vec каждой категории, в качестве выхода берут веса классификаторов для тех вершин, для которых есть обучающая выборка), фитят на этом GNN и получают 18% улучшения к текущей SOTA. Плюс это очень красивый пример интеграции текстовой и визуальной информации <3 - когда человек учится распознавать картинки, у него есть много текстовой информации об обьектах и наоборот, сетку мы лишаем какого-нибудь другого вида информации, кроме визуального. Это похоже на попытку научить безграмотного человека распознавать сложные визуальные концепты - получается, но неидеально - в статье приводят пример о том, что сетке нужно распознать категорию "окапи" - смесь зебры и оленя, без онтологии даже человек не справился бы с этой задачей (Рисунок 1). Почитать интересную аналитику на схожую тему (недостаток визуальной информации при классификации текстов) можно тут.

При обработке текстов GNN также оказываются весьма полезны. Например, классифицировать текст можно, представив его в виде графа связанных слов - этот способ получить вектора для слов хорош в тех случаях, когда слова не находятся рядом в тексте, но их сходство можно уловить по общим соседям. Пример из статьи - слова "сэндвич" и "ресторан" редко оказываются в одном контексте, а вот "меню" и "сэндвич" и "меню" и "ресторан" - часто.
Подробней про модели
Задачу классификации на графах можно разбить на два этапа
- строим представление узлов-связей-графа(в зависимости от того, что хотим классифицировать), учитывая информацию об окружении
- подаем полученный вектор классификатору, который предсказывает таргет
Рассмотрим сначала то, как можно получать представления для вершин в графе
- Один из самых простых способов строить вектора для вершин графа - можно насэмплировать из графа последовательностей и обучить на них word2vec-подобную модель - полученные векторные представления и будут нашими вершинами в графе. Но такой способ крайне ресурсоемкий и плохо работает на больших графах.
- Можно учесть информацию более умно - задать ее как функцию от вектора вершины, информации о связи с другими вершинами и векторов других вершин.
В обзорной статье дана картинка с систематизацией видов таких функций на графах (Рисунок 2).
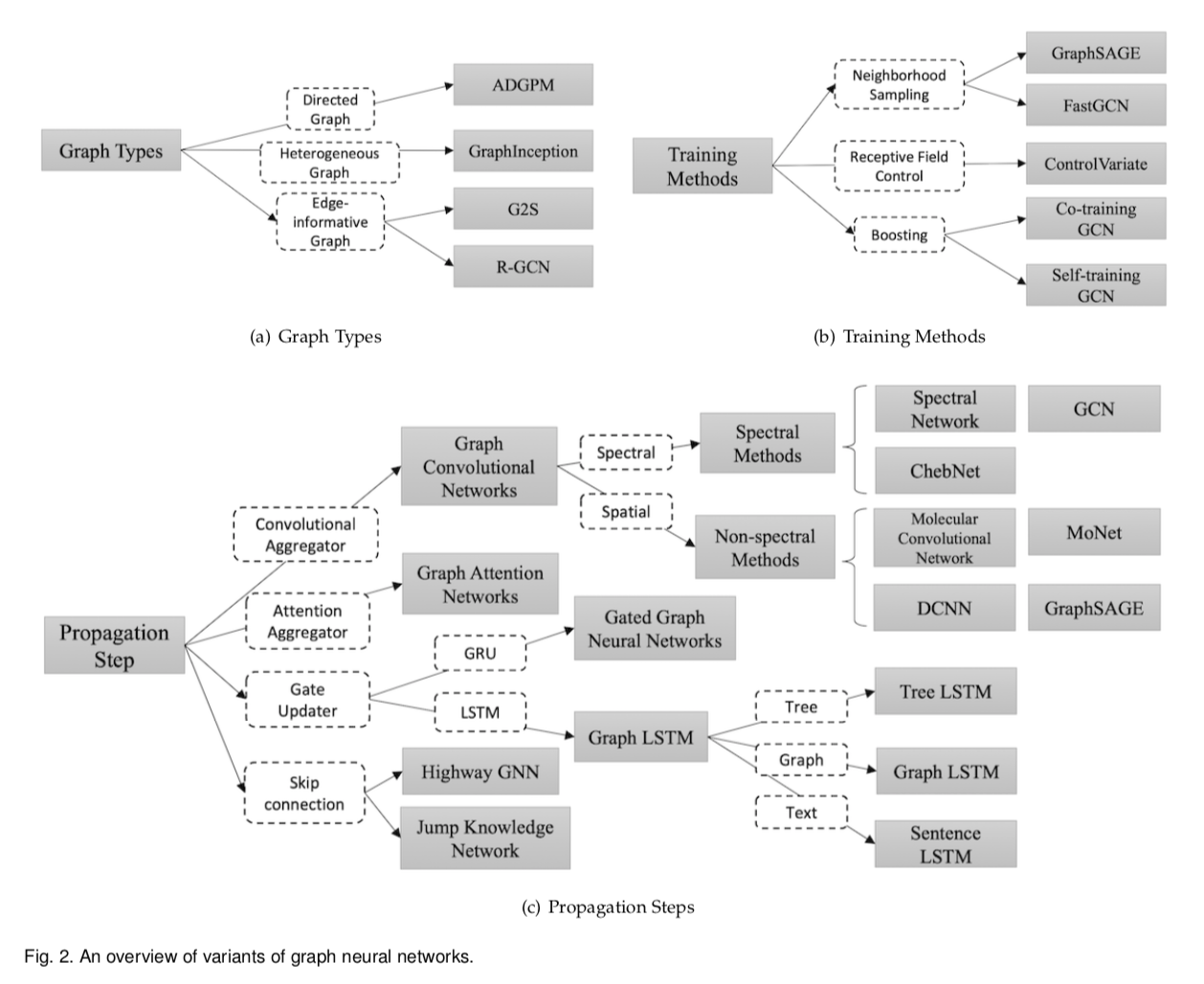
Все вопросы о моделях можно разбить на три группы:
- Типы графов. К графам разных типов нужно применять разные модели. Например, существуют гетерогенные графы, где вершины не равнозначны - например, в графе происхождения животных вершины обозначают вымерших или существующие виды. В таком случае контатенируют one-hot вектора признаков вершин вместе с вектором признака вершины и пускают в сеть. Есть графы, в которых у ребер тоже есть признаки, которые хочется учесть при обучении - например, в графе социальной сети - сколько по времени дружат люди, насколько часто они переписываются и тд. Эту информацию учитывают, представляя ребро в виде вершины с вектором признаков ребра и соединяя новую реберную вершину с вершинами, которые это ребро соединяло. Второй способ - тренировать для разных видов ребер различные весовые матрицы.
- Виды GNN. В качестве агрегатора состояний соседей можно использовать различные типы архитектур - сверточные, реккурентные, attention, skip connection, но принципы работы GNN остается похожим. Разберем работу GNN на примере одной из самых популярных моделей GraphSAGE. Сначала нам даны вектора для всех вершин графа и информация о том, как они связаны(лапласиан). Наша цель - обновлять эти вектора вершин сетью, то есть получить эмбеддинги, чтобы решить задачу классификации(Рисунок 3). Мы сэмплируем вершины из окрестности вершины(вершины, которые лежат рядом), для которой мы обновляем вектор. Агрегируем эти вектора каким-либо способом (в самом простом случае - усредняем, в более сложном - пропускаем через реккурентную сеть и тд). Затем полученный агрегат конкатенируем с текущим вектором вершины, пропускаем через полносвязный слой сети, получаем обновленный вектор для нашей вершины, который можно отдавать на вход классификатору. Повторяем для различных вершин до получения положительного результата.
- Виды тренировки GNN. Классический способ тренировки - при заданном лапласиане(знаем какие вершины связаны с какими, знаем степень вершин), применить одну из моделей пункта 2 (виды сети). Но поскольку лапласиан графа считать достаточно затратно, и если мы построили GNN при одном лапласиане, обобщить на другой будет нереально, нужны более умные способы. Один из способов - выучить функции, аггрегирующие окрестность заданной вершины вместо Лапласиана, и конкатенировать их с эмбеддингом вершины(neiborhood sampling).
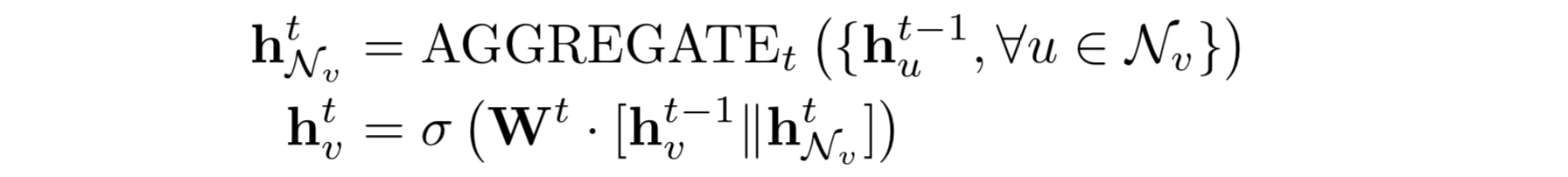
Какие проблемы остались?
1) Все графовые сети неглубокие(в районе 3 слоев), при увеличении числа слоев сеть перестает адекватно работать
2) Мы не умеем работать с динамическими графами
3) Графовые нейронки очень долго и тяжело учатся по ресурсам, плохо обобщаются
4) Нет оптимальных методов генерить граф из сырых дынных
Что в итоге?
Есть такой вид сеток, как сетки на графах. Однозначна крутая и незаменимая штука при работе с графовыми данными. Кроме того, кажется крайне полезным способом учитывать различные признаки из на-первый взгляд неграфовых данных, например текстовую информацию в zero и one-shot learning на картинках