Небольшой релиз 11.50.35
Dmitry VorontsovКомпрессия трафика
Добавил работу со сжатием запросов онлайн-обработчиков (тех самых, котрые set_input_direct). Входящие запросы она автоматом распаковывает по заголовку Accept-encoding: gzip , а чтобы она упаковывала исходящие json нужно где ни будь в инициализации добавить переменную _GZIP . Это именно компрессия/декомпрессия JSON, рассчитанная на слабые каналы (3G, плохой WiFi). Стек переменных может быть большим особенно если карточки, таблицы, списки ActiveCV и что то подобное.
При приеме такого запроса на стороне сервера надо соотвественно траффик распаковывать. Например в Python:
inputdata = gzip.decompress(request.data)
Определение метода внутри hashMap в онлайн-запросах
Мне нравится определять методы как в обработчиках pythonargs т.е. например some_function(a,1,?) вот только при передача через set_input_direct могут быть накладки (это же все таки HTTP-запрос). Поэтому логично что название функции надо прятать в тело запроса. Чтобы все вручную не переделывать, сделал флаг _ENCODE_ONLINE который переделывает запросы онлайн-обработчиков. Запрос отправляется set_input_direct/hashMap (вместо имени метода всегда hashMap), имя метода внутри hashMap в переменной online_method
Теперь можно в обработчиках типа онлайн пистаь не просто имя функции а задавать параметры.
Распознавание текста (OCR) через камеру для экранов: новое
Теперь прикрутить OCR распознавалку к экранам стало неприлично просто.
Это касается исключительно экранов (элемент "Распознавание текста"). В ActiveCV более интенсивная нагрузка чем как на экране "открыть распознавалку-распознать объект-вернуть значение" , поэтому там все остается пока по прежнему. В чем суть вопроса? Опытным путем было обнаружено что распознавалка текста должна опираться на какой то заранее подготовленный список (если объектов мало) либо SQL-запрос (если ищем товар из миллионов артикулов) и это так. Для онлайн-решений предлагалось закешировать таблицу объектов в виде SQL таблицы и к ней обращаться. Это конечно гарантирует что все будет максимально быстро и четко. Но! Как говорил персонаж из Игры Престолов everything before the word but is horseshit... Короче если решение и так на SQL то подсунуть поиск по товарам - проще простого, а вот если нет, то возиться с синхронизацией таблицы ради того чтобы распознавать объекты, к которым поленились приклеить штрихкоды...
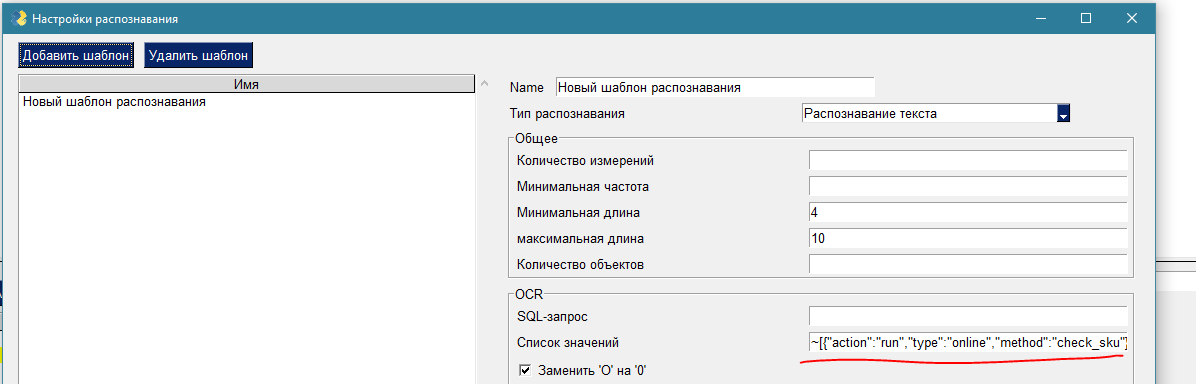
В общем в настройке распознавания через ~ вставляем какой обработчик должен выполниться при поступлении текста от OCR и... это все.
Например так: ~[{"action":"run","type":"online","method":"check_sku"}]
Надо понимать, что это НЕ хороший, обработанный артикул вашего товара, а все текстовое, что залезло в объектив камеры (рядом стоящие надписи и т.д.)
Т.е. за обработку этого текста, отвечает как раз ваш обработчик и вам нужно отбрасывать все лишнее, проверять по базе и принимать решение
После того как решение принято вы должны поместить переменную ocr_result чтобы платформа поняла, что объект нашелся (если количество измерений=1 или не заполнено, на этом поиск заканчивается)
Например так:
def check_sku(db,hashMap,*args):
res = db['goods'].find_one({"product_number":hashMap.get("ocr_text")})
if res!=None:
hashMap.put("ocr_result",str(res))
hashMap.put("selected_card_key",str(res.get("_id")))
return hashMap
Плюс также для экранов появилась возможность поиска по списку как в ActiveCV. Т.е. если без ~ то можно передать туда список с разделителем и он будет опорным для OCR
Возврат содержимого кастомной карточки/строки кастомной таблицы
Все просто. Когда вы делаете список кастомных карточек/таблицу в данные каждой карточки вы кладете данные отображаемые и неотображаемые. Для ускорения работы можно установить переменную return_selected_data и тогда при клике на элмент в selected_card_data будет выгружаться весь объект