.NET Internals 6 - Generational garbage collection
В этой части серии статей мы увидим, что такое поколения в сборке мусора. Мы также узнаем, что такое карточная структура и для чего она используется.
Содержание:
- Поколения в куче
- Сборка выживших ??? (Collection survivors)
- Пороговые значения и поколения при сборке
- Структура поколений кучи
- Цикл поколений GC
- Почему статические данные вредны для GC?
- Cross-generation references
- Карточная структура данных
- LOH
Поколения в куче
Как мы уже знаем, кучи, используемые процессом .NET для выделения ссылочных объектов, имеют разные типы. В предыдущей статье мы также узнали, что только куча небольших объектов (SOH) является предметом процесса уплотнения. Куча больших объектов (LOH) не уплотняется из-за соображений производительности.
Однако это не единственная оптимизация, введенная участниками GC в кучу небольших объектов. SOH в .NET также делится на 3 поколения:
- Поколение 0 – содержит вновь созданные объекты, над которыми до сих пор не выполнялась никакая сборка,
- Поколение 1 – хранение объектов, которые пережили одну сборку мусора (не были утилизированы во время нее из – за того, что все еще использовались),
- Поколение 2-хранение долгоживущих объектов, которые пережили два или более циклов GC.
Благодаря такому разделению управляемой кучи фактический сбор выполняется не на всей куче, а только на одном из поколений, где:
для выполнения сборки в поколении X происходит сбор объектов в поколении X и всех его младших поколениях
Вот почему сборка второго поколения известна как полная сборка мусора. Во время этого процесса объекты, присутствующие во всех кучах (во всех поколениях: поколение 0, поколение 1 и поколение 2), исследуются и утилизируются. Очевидно, что эта сборка также является самой дорогостоящей.
Оставшийся в живых
В этом месте мы должны ввести термин "оставшийся в живых". Его можно определить как объект, который сохраняется в коллекции (не собирается во время цикла сбора GC, так как на него все еще что-то ссылается).
Зная это, можно определить следующие “правила продвижения” :
- объект переживает коллекцию поколения 0 => объект повышен до поколения 1,
- объект переживает коллекцию поколения 1 => объект повышен до поколения 2,
- объект переживает коллекцию поколения 2 => объект остается в поколении 2.
Пороговые значения сбора в поколениях
В 5-м посте серии было упомянуто, что одним из условий, при которых может быть запущена сборка мусора, является то, что “память, используемая объектами в управляемой куче, превышает некоторый определенный порог". На самом деле это не один порог, а несколько порогов. Точнее, на каждое поколение приходится отдельный. Как только размер всех объектов в определенном поколении превышает пороговое значение, запускается коллекция.
В начале значения пороговых значений для каждого поколения инициализируются следующими значениями:
- Поколение 0: ~256K,
- Поколение 1: ~2MBs,
- Поколени 2: ~10MBs.
Тем не менее, это только начальные значения, и они корректируются GC во время выполнения. Одним из условий увеличения значения определенного порога является то, что коэффициент выживаемости в поколении высок (больше объектов из определенного поколения либо переходят в следующее, либо остаются в поколении 2), что делает циклы GC менее частыми (условие превышения порога выполняется не так часто).
Такой подход кажется разумным, поскольку основная цель GC-собрать как можно больше объектов и восстановить их память, а не “тратить время” только на то, чтобы узнать, что большинство объектов все еще используются.
В целом, CLR пытается найти баланс между двумя факторами:\
- не позволять набору рабочей памяти приложения становиться слишком большим
- не позволять GC занимать слишком много времени.
Структура кучи поколений
На приведенной ниже диаграмме показано, как на самом деле выглядит SOH, разделенная на описанные выше 3 поколения:
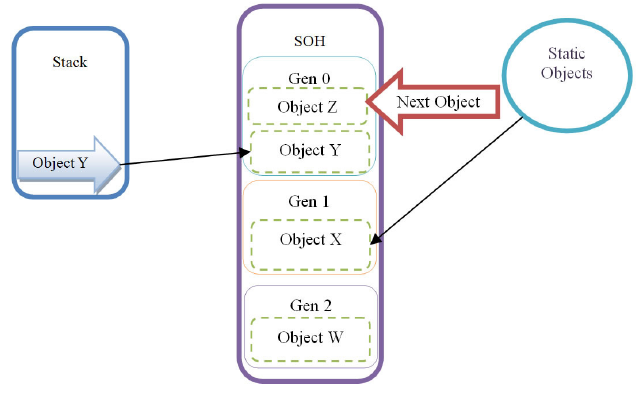
Как можно заметить, указатель на следующий объект (вы можете прочитать об этом подробнее в этом посте) указывает на место после последнего объекта в поколении 0. Вновь созданные объекты всегда выделяются в поколении 0.
Цикл поколений GC
Следующая схема очень четко представляет, как выглядит цикл поколений сборки мусора:
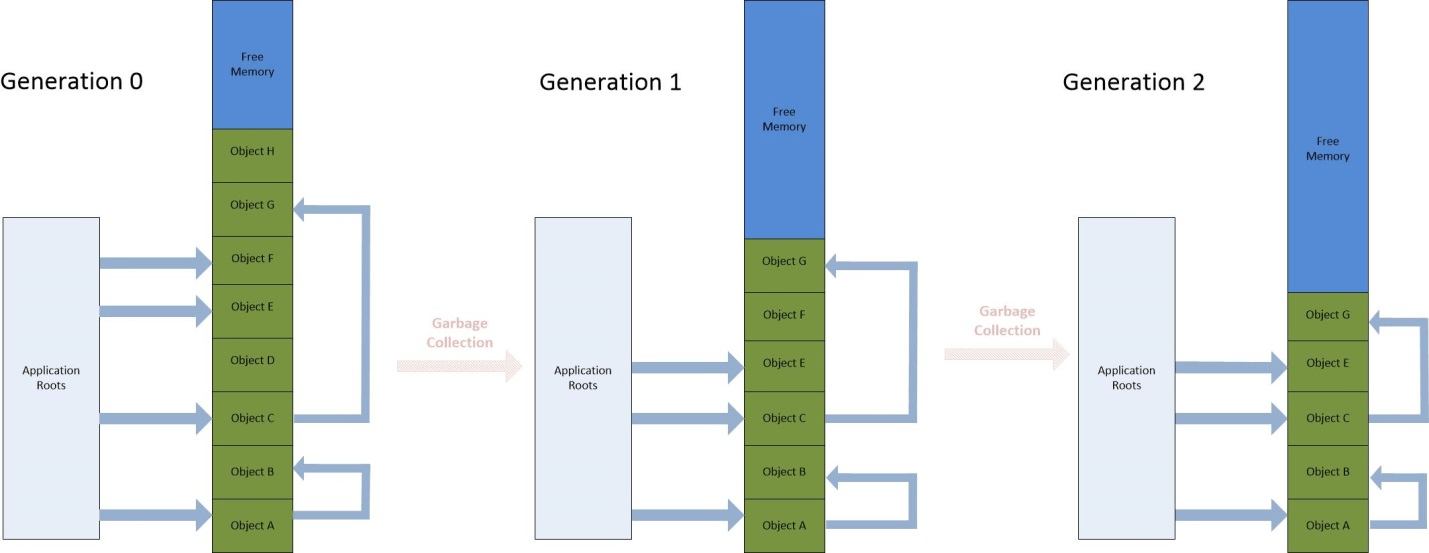
Первый шаг - это сборка поколения 0. Вы можете заметить, что на объекты H и D ничто не ссылается, поэтому после выполнения первого цикла в поколении 0 эти объекты утилизируются и не переводятся в поколение 1. То же самое происходит с объектом F, на который больше не ссылаются при выполнении сбора в поколении 1 – вот почему он утилизируется на этом этапе и не переходит в поколение 2. В конце полного цикла GC - только объекты, на которые все еще есть ссылки, остаются в поколении 2.
Что также важно отметить, так это то, что после каждого поколения сборки нулевое поколение становится пустым (не содержит объектов). Поколение 1 все еще может содержать объекты, продвигаемые из поколения 0, а поколение 2 может содержать объекты с длительным сроком службы.
Почему статические данные вредны для GC?
Обладая знаниями, представленными в этом посте, мы можем сделать вывод, что чем больше объектов хранится в поколении, тем дольше длится процесс сборки. Мы также видим то, что поколение 2 содержит долгоживущие объекты, которые в основном являются статическими или глобальными объектами, которые выдерживают циклы сбора мусора (поскольку в приложении всегда есть “живая” ссылка на них).
Конечно, есть некоторые причины, по которым статические данные могут быть оправданы (например, приложения на стороне сервера, хранящие некоторый контекст), но обычно следует избегать использования статических данных, насколько это возможно и разумно. Я думаю, вы уже знаете, почему – это просто понижает производительность приложения, делая работу сборщика мусора сложнее и дольше.
Cross-generation references (Ссылки на перекрестное поколение)
Существует также одна очень интересная проблема, связанная с разделением управляемой кучи на поколения. Можете ли вы представить себе случай, когда объект уже переведен в поколение 2, но одно из его свойств ссылочного типа только что было инициализировано в поколении 0? Рассмотрим следующий код:
public class GuyFromGen2
{
private YoungObject _youngObject;
public void CreateYoungObject()
{
_youngObject = new YoungObject();
}
}
Давайте предположим, что экземпляр GuyFromGen2 уже давно создан и уже переведен в поколение 2. В этот момент кто-то вызывает метод CreateYoungObject(), который инициализирует переменную _youngObject. Это делает “родительский” экземпляр GuyFromGen2 содержащим ссылку на его объект экземпляра, расположенный в поколении 0.
Когда в этот самый момент запускается сборка поколения 0 (которая, как мы уже говорили, проверяет только объекты в поколении 0), он обнаружит _youngObject, выделенный в куче, не имеющий ссылок на него (поскольку он не проверяет ссылки поколения 2 во время коллекции поколения 0), поэтому он предположит, что объект не используется, и утилизирует объект.
К счастью, в .NET есть решение этой проблемы – структура данных карточной таблицы.
Структура данных карточной таблицы
Карточная таблица используется системой управления памятью .NET для хранения информации об объектах старшего поколения (в данном случае поколения 2), которые ссылаются на более молодые объекты (поколения 0 или поколения 1). Механизм выполнения добавляет запись в карточную таблицу, как только любая ссылка на объект поколения 0 или поколения 1 создается “внутри” объекта поколения 2.
По соображениям оптимизации производительности таблица карт хранит эту информацию на “бит”, который представляет 128 байт (или 256 байт в 64-разрядных архитектурах) управляемой памяти. Вот как можно представить себе карточный стол:
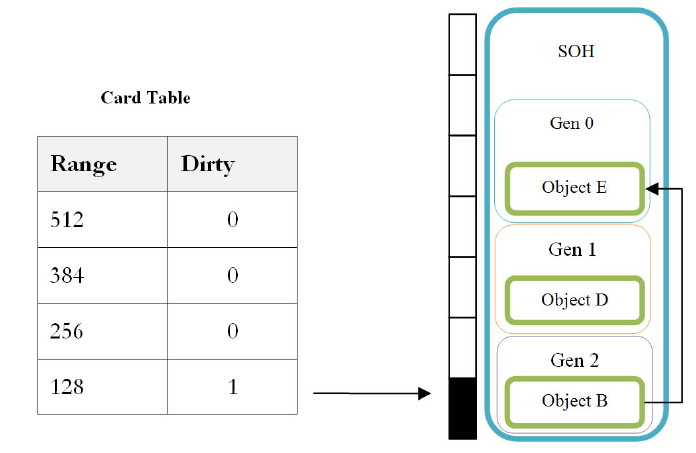
Затем, как только происходит сбор данных поколения 0 или поколения 1, помимо изучения ссылок только из корней конкретного поколения, GC также проверяет, в каких диапазонах памяти установлены биты 1, выясняет, какие объекты выделены в этих диапазонах памяти, и рассматривает их как потенциальные корни GC (анализируя, на что ссылаются эти объекты).
Более того, из-за оптимизации барьера записи целые байты (8-битные фрагменты, а не только отдельные биты, как показано на рисунке выше) помечены как потенциальные источники корней. Таким образом, на самом деле такая ссылка между поколениями может пометить до 2048 байт (для 64-разрядных архитектур: 256 байт x 8 = 2048 байт) памяти в качестве потенциального источника корней GC.
Каждый объект, на который есть ссылка, найденный таким образом, добавляется в список объектов, которые все еще используются (если вы все еще не знаете, что такое корни GC и список объектов, которые все еще используются, прочитайте предыдущий пост сейчас).
LOH
Если вас интересуеторганизация памяти в куче больших объектов (LOH), я рекомендую вам прочитать эту статью Маони Стивенс. Я могу просто упомянуть, что LOH имеет свой собственный порог памяти, который может быть превышен, и он также запускает сбор данных 2 – го поколения - с точки зрения GC, сбор объектов, выделенных в LOH, происходит только во время сбора данных 2-го поколения.