Миф о репрезентациях
В конце сегодняшнего обзора не будет таблиц с бенчмарками и описанием, что такая-то новая модель обошла в каких-то задачах какие-то старые модели и даже сам GPT. В этот раз авторы рассматривают вопрос почти философский, а в самой статье цитируют Платона и Толстого. Речь о майской статье The Platonic Representation Hypothesis от исследователей из MIT. Гипотеза заключается в следующем: нейронные сети разных архитектур, обученные на разных данных и для разных целей, сходятся. Причем сходятся к статистической модели реальности.
Звучит круто. Получается, что все модели, большие и маленькие, языковые, графические и мультимодальные, не просто показывают свою часть одной и той же модели реальности, но еще и в перспективе приведут к вообще одному отображению. Будет ли это AGI, будет ли та модель мира, о которой говорит Лекун — в явном виде авторы эти вопросы не упоминают, но вывод напрашивается сам.
Итак, допустим, у нас есть реальный мир. На картинке снизу реальный мир состоит из синего конуса и красного шара и обозначается Z. Его можно воспринимать или измерять с помощью разных сенсоров. Получатся некоторые модели (в попперианском смысле) реального мира. Например, камера Х снимает Z и получает картинку, а Y дает текстовое описание. Эти проекции, или отображения, или репрезентации хоть и совершенно разные по форме и содержанию, получаются из одной и той же реальности Z и в этом смысле разумно полагать, что они будут синхронизированы.
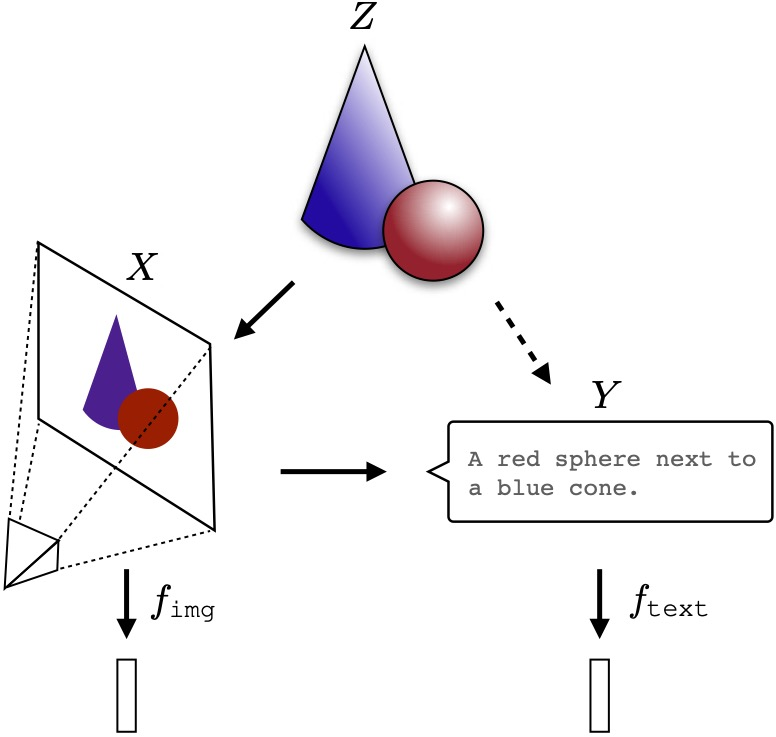
Теперь чуть ближе к статистическим моделям. Алгоритмы обучаются на этих отображениях и строят на них статистические модели, которые соответствуют нужной цели. Но чем больше модель, тем больше информации должны содержать в себе отображения, поэтому их стройное равнение на Z должно быть всё быстрее по мере масштабирования.
Авторы приводят три возможных, но не взаимоисключающих обоснования сходимости. Это пока не доказательства, а общие рассуждения, хотя и основанные на математическом подходе. Даже не так — это еще три гипотезы, которые объясняют принципы действия первой гипотезы.
Первый вариант — сходимость объясняется обобщением заданий. Каждая точка обучающих данных и каждое задание вносит свои дополнительные ограничения в модель. То есть по мере масштабирования тех и других количество отображений, которые будут удовлетворять ограничениям будет всё меньше.
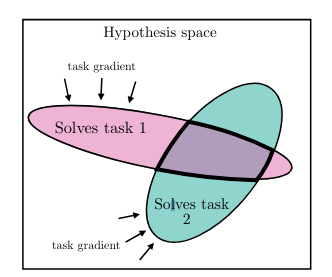
Другими словами, чем “общее” модель, тем меньше у неё будет возможных решений. Результаты последних лет доказывают, что чем больше данных, тем лучше результат. Отсюда вывод следующий: когда данных будет достаточно много (скажем, весь интернет и все живые физические параметры), то модель сойдется к очень маленькому набору решений. Можно было бы сказать, что к единственному решению, но это не позволяет сделать неустранимая неопределенность мира.
Второй вариант — сходимость объясняется емкостью модельного пространства. Здесь имеются в виду набор функций, среди которых модель с помощью обучения выбирает подходящую. Чем больше это пространство, то эффективнее будет поиск оптимума. Другими словами, большие модели (даже разной архитектуры) с большей вероятностью сойдутся к одному отображению, чем маленькие.
Третий вариант — стремление к простоте. Можно предполагать, что репрезентация собаки, которую построит модель с 1М параметров будет отличаться от той же собаки в представлении 1В модели. Что помешает большой модели обучиться слишком сложным и детализированным отображениям? Нейросети стремятся к более простым решениям, которые соответствуют задаче. И чем больше модель, тем сильнее это стремление. Оно может исходить из заданной в явном виде функции регуляризации, но и без неё предпочтения будут отдаваться самому простому решению из подходящих.
Хорошо, модели ИИ будут умнеть и сходится к чему-то одному. Теперь, главный вопрос — к чему. Под статистической моделью реальности, о которой мы уже упомянули в начале, авторы предполагают набор дискретных событий из некоторого (неизвестного) распределения P(Z). Каждое событие можно наблюдать по-разному. “Наблюдение” — это биекция с определенной (известной) функцией. Функция распределения P(Z), если её каким-то образом узнать, и будет содержать модель мира. Возьмем модель, которая будет учиться определять события, происходящие вместе, то есть определять PMI, pointwise mutual information, поточечную взаимную информацию.
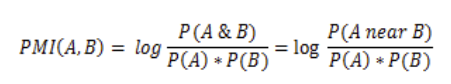
Модель мира состоит из биекций, а они сохраняют вероятности. Выходит, что какой бы модальности ни была модель, ядро отображения будет то же, которое определяет заданную в P(Z) статистику.
Авторы привели несколько примеров, когда согласованные репрезентации выходят у моделей разной архитектуры, причем это действительно становится заметнее по мере увеличения размеров и перфоманса. Тут и пригодился Толстой, которого перефразировали так: “все сильные модели сильны одинаково, а каждая слабая модель слаба по-своему”
Какие последствия у этой, пока теоретической, но претендующей на фундаментальную истину сходимости? Во-первых, получается, что масштабирование моделей, может, конечно, и достаточный, но вовсе не самый эффективный способ. Если совершенно разные модели сходятся к одному, то означает ли это, что “scale is all you need” ? Авторы уверены, что нет.
Во-вторых, обучающие данные могут (и даже наверное должны) быть мультимодальными. Допустим, у вас есть набор изображений и предложений. Если озвученные гипотезы верны, тогда и языковые и графические данные должны помочь найти лучшее отображение. То есть, чтобы обучить лучшую языковую модель, нужно обучать её и на картинках тоже. Впрочем, эта практика уже действительно набрала обороты.
Причём здесь Платон? Тут авторы имеют в виду платоновскую пещеру, её узники видят лишь тени на стенах, которые отбрасывает реальный мир. В нашем случае тени — это обучающие данные, то, что доступно нам, узникам пещеры. Платон использовал эту аллегорию, чтобы показать, что люди горько ошибаются, полагая, что могут по этим теням судить о реальном мире за пределами пещеры. Но если продолжать аналогию, то авторы как раз и пытаются доказать, что разные тени сходятся к реальному миру. Платон бы, наверное, поспорил, что это иллюзия. Но это уже совсем другая история )