Mask R-CNN: When Object Detection Learned to Draw Precise Boundaries
Vansh AroraA submission-ready research blog on instance
segmentation
Paper: He et al., ICCV 2017
Recommended public code: Matterport Mask_RCNN / Detectron2
Prepared by: ____________________
Group Members / Roll Numbers: ____________________

1. The problem the paper
targets
Object detection tells us what is in an image and roughly where it
is. Semantic segmentation labels every pixel, but it does not separate
two objects of the same class from each other. Instance segmentation is
harder because it must do both jobs at once: detect each object and
predict its exact pixel mask. That makes it one of the most useful and
demanding tasks in computer vision, especially for autonomous systems,
robotics, medical imaging, retail analytics, and scene
understanding.
Mask R-CNN targets exactly this problem. Its key insight is that
instance segmentation does not need a wildly complex pipeline; it needs
a detector that preserves spatial alignment well enough to make
pixel-level predictions per object instance.
2. Why the problem is
important
The relevance of the problem becomes obvious when scenes get crowded.
A bounding box around a person, bicycle, or surgical tool is often not
enough for downstream decision-making. Systems need boundaries, overlap
handling, and separation between nearby objects. COCO was designed to
stress-test that ability in realistic scenes. The original COCO paper
introduced 328K images with 2.5 million labeled instances across 91
object types, explicitly pushing research toward recognition in context
rather than isolated, iconic images [2].

3. The approach in one picture
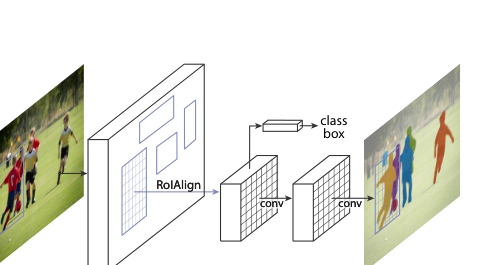
Figure 1. Simplified view of the Mask R-CNN pipeline. Source:
figure adapted from He et al. [1].
Mask R-CNN extends Faster R-CNN in a very clean way. The first stage
remains the Region Proposal Network (RPN), which proposes candidate
object regions. The second stage still classifies each region and
refines its bounding box. The new idea is to add a third, parallel
branch that predicts a binary object mask for each Region of Interest
(RoI) [1].
What made this extension work was not only the mask head itself, but
the replacement of RoIPool with RoIAlign. RoIPool performs coarse
quantization when extracting region features; that small misalignment
hurts a pixel-level task much more than it hurts box classification.
RoIAlign removes this quantization and preserves exact spatial
locations, making mask prediction much sharper and more reliable
[1].
4. Technical
contributions that made the paper strong
- Parallel multi-task design: class label, box
regression, and instance mask are predicted together from the same
object proposal. - RoIAlign: a quantization-free region feature
extraction layer that preserves spatial correspondence. - Decoupled mask prediction: the class branch
predicts the category, while the mask branch predicts an independent
binary mask per class. - Fully convolutional mask head: the model keeps
spatial structure instead of flattening it too early.
5. Results against previous
baselines
The headline result is simple: Mask R-CNN pushed instance
segmentation forward without relying on a fragile or overly specialized
design. On COCO test-dev, the ResNet-101-FPN version reached 35.7 mask
AP, beating FCIS+++ at 33.6. With a ResNeXt-101-FPN backbone, it reached
37.1 mask AP [1].
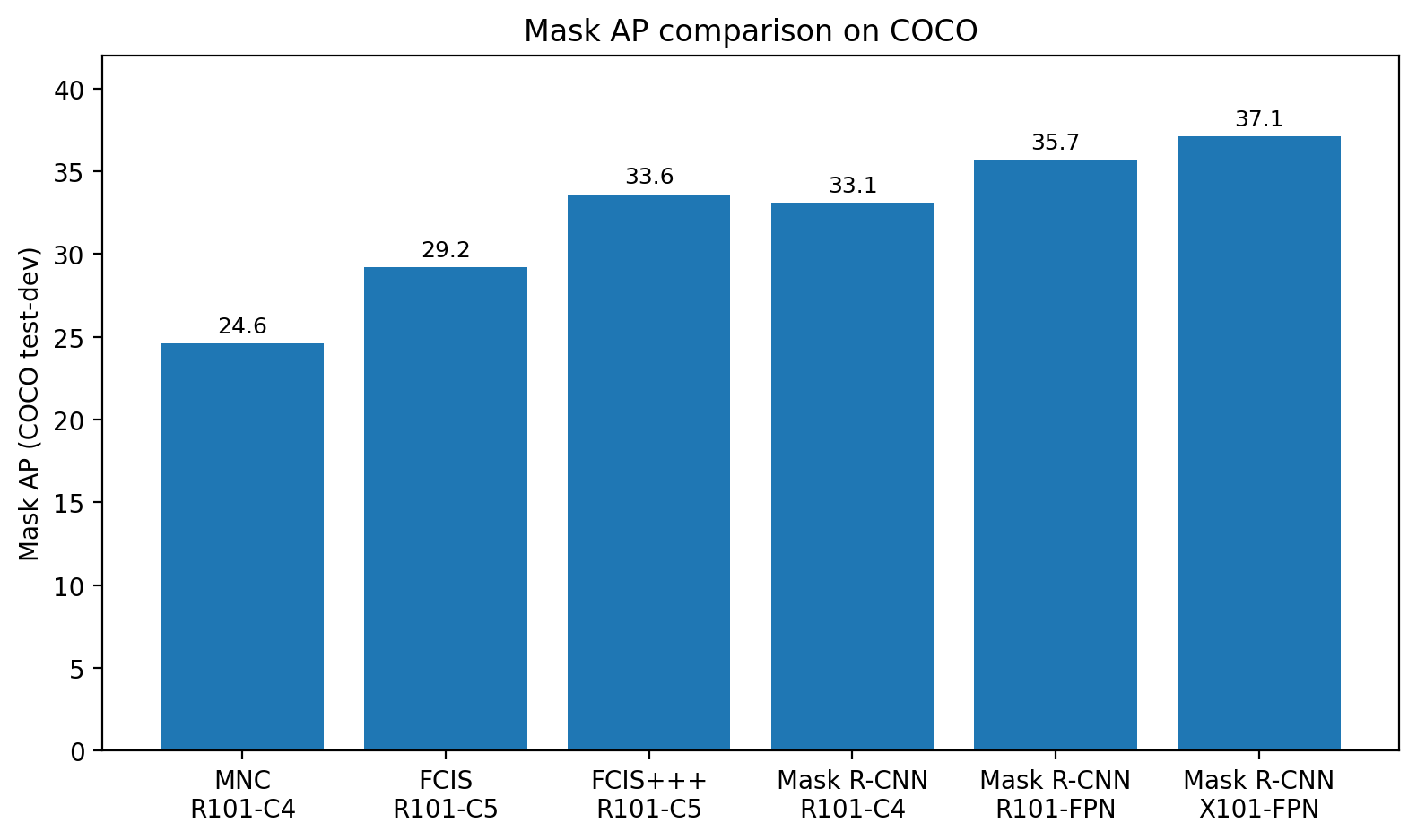
Figure 2. Mask AP comparison using values reported in Table 1 of
the Mask R-CNN paper [1].
The gains were not limited to masks. For bounding-box detection on
COCO test-dev, Mask R-CNN with ResNet-101-FPN reached 38.2 box AP, while
the ResNeXt-101-FPN version reached 39.8. The paper also trained a
Faster R-CNN model with RoIAlign but without the mask branch and found
that the full multi-task Mask R-CNN model was still 0.9 AP better on box
detection, suggesting that mask prediction improves the shared
representation itself [1].
6.
Qualitative evidence: why the outputs were convincing

Figure 3. Example COCO outputs from the Mask R-CNN paper
[1].
The qualitative results are important because instance segmentation
can look deceptively good on clean scenes and then fail badly in
clutter. Mask R-CNNâs COCO examples show that it can separate multiple
nearby people, animals, vehicles, and indoor objects while preserving
recognizable boundaries. This matters because a model that wins only in
averaged metrics but collapses visually under overlap is not a reliable
baseline for further research.

Figure 4. FCIS+++ (top) versus Mask R-CNN (bottom) on overlapping
objects. Source: He et al. [1].
7. Why the method
worked: the ablation story
One of the strongest aspects of the paper is that it does not hide
behind a big final number. It explains where the gains come from.

From a research point of view, this is exactly what makes the paper
persuasive. The improvements are not accidental. The paper isolates a
real systems issue - spatial misalignment - fixes it, and then proves
with ablations that the fix is both measurable and portable.
8. Critical
analysis from a research perspective
Mask R-CNN deserves praise for clarity, modularity, and empirical
honesty. It improved the state of the art without becoming conceptually
messy. It also became a baseline paper: later work in instance
segmentation often starts from Mask R-CNN rather than arguing from
scratch.
However, the paper has limitations. First, it is still a two-stage
pipeline, so it is not the ideal answer when inference speed is the main
requirement. The authors report about 195 ms per image for a
ResNet-101-FPN model on a Tesla M40 GPU, roughly 5 fps, and explicitly
note that the design was not optimized for speed [1]. That left room for
later one-stage methods such as YOLACT, which reported 29.8 mAP at 33.5
fps on COCO [5].
Second, the model is much stronger on larger objects than on small
ones. The ResNet-101-FPN result in Table 1 reports APs = 15.5, APm =
38.1, and APl = 52.4 [1]. That gap is not unique to Mask R-CNN, but it
is important because real scenes often contain distant or partially
visible objects.
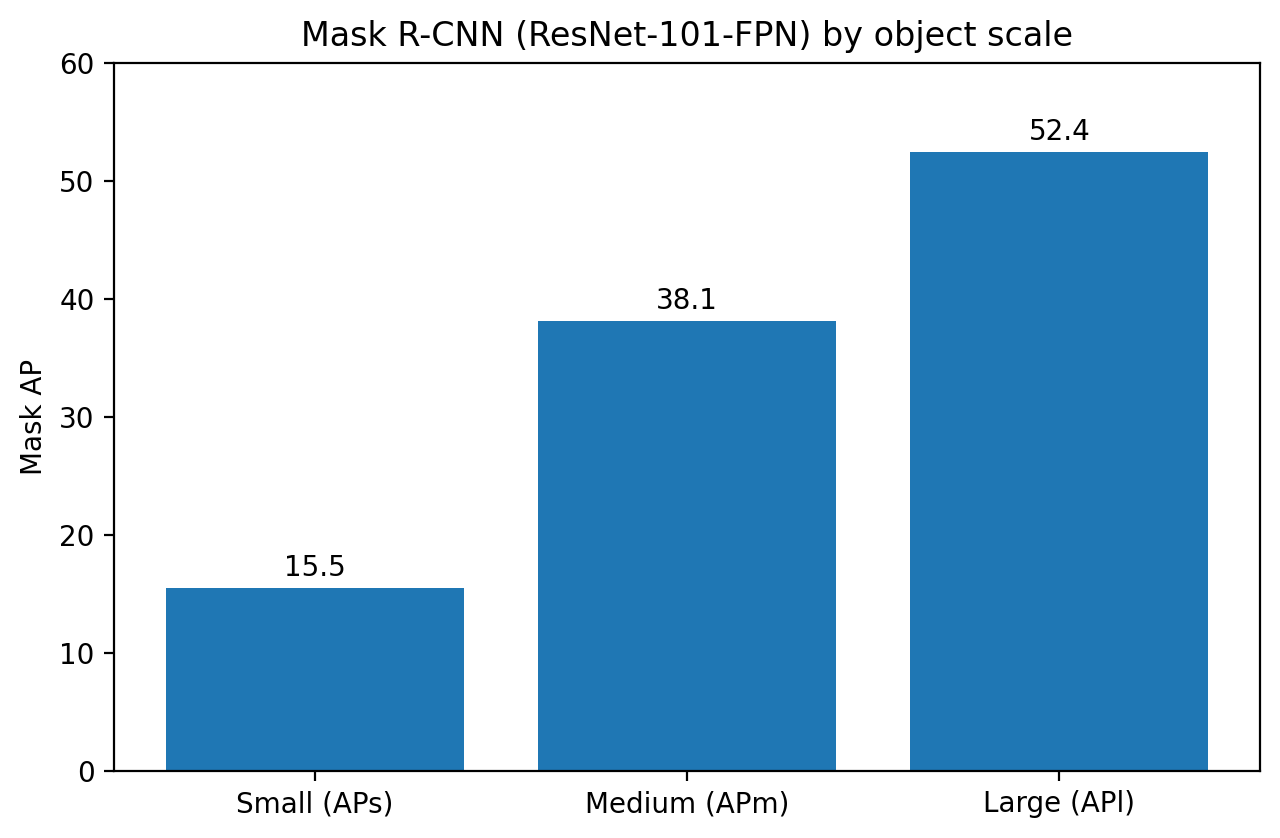
Figure 5. Small objects remain much harder than medium or large
ones in the paperâs own COCO breakdown [1].
Third, the paper does not fully solve the mismatch between
classification confidence and actual mask quality. Later work such as
Mask Scoring R-CNN argued that classification score is often poorly
correlated with mask IoU, and reported about a 1.5-point AP improvement
by learning to calibrate mask quality directly [4]. This is a meaningful
critique because it targets not the backbone of Mask R-CNN, but one of
its implicit evaluation assumptions.
9. Improvement suggestions
- Add a learned mask-quality head, following the direction of Mask
Scoring R-CNN, so that ranking better reflects actual segmentation
quality. - Improve the speed-accuracy trade-off for deployment-heavy settings
through lighter backbones or one-stage alternatives inspired by
YOLACT. - Target small-object performance specifically through
higher-resolution mask heads, stronger multi-scale fusion, or
task-specific data augmentation. - Study calibration and uncertainty, especially for safety-critical
applications where a good-looking mask may still be incomplete or
fragile.
10.
Reproducibility and public GitHub repositories
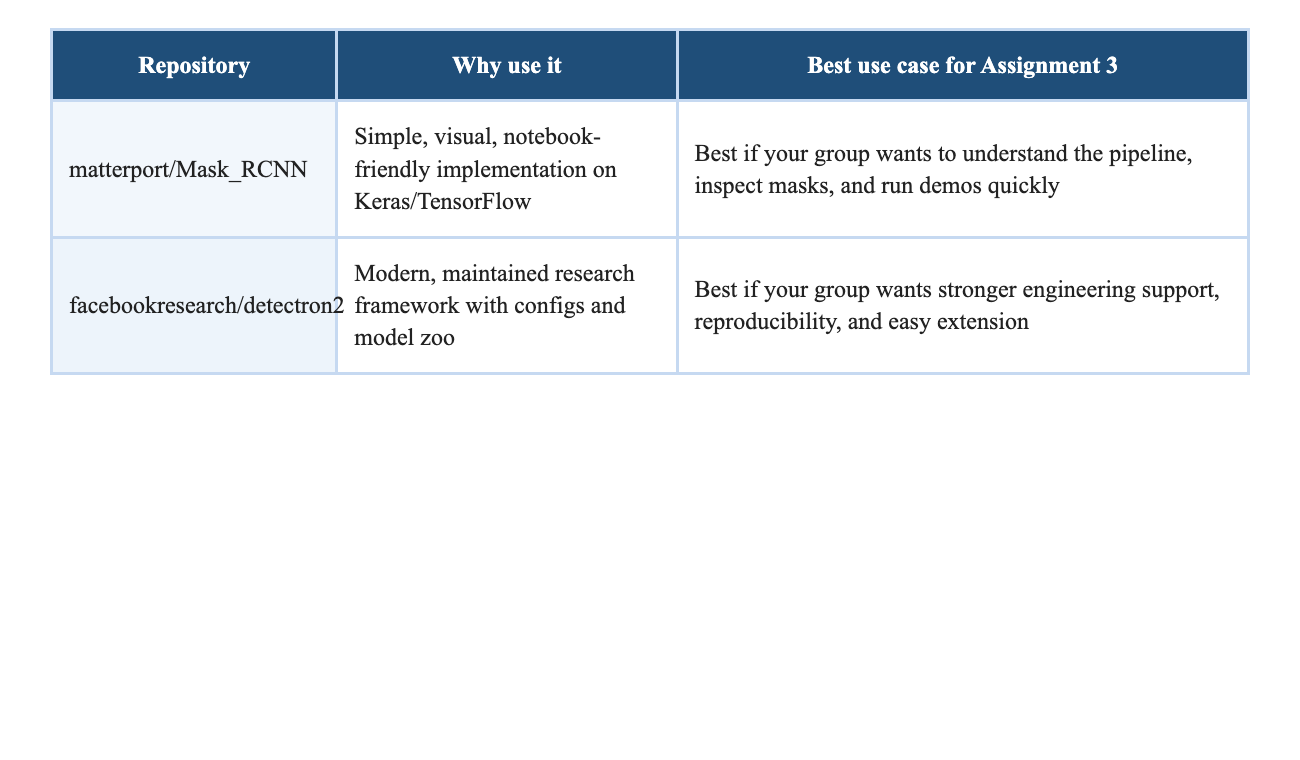
This paper is a strong assignment choice not only because it is
influential, but because it is runnable. The easiest repository for
understanding the pipeline is the Matterport implementation, which
includes training code for MS COCO, pre-trained weights, evaluation
utilities, and notebooks that visualize the detection pipeline step by
step [3]. For a more modern research stack, Detectron2 is the maintained
successor in the Facebook research ecosystem and includes
state-of-the-art detection and segmentation baselines, documentation,
and a model zoo [6].
11. Final verdict
Mask R-CNN is one of the clearest examples of how a relatively small
architectural correction can unlock a major performance jump. Its
long-term value comes from three things: it solves a meaningful problem,
it explains its gains with strong ablations, and it leaves behind a
reproducible framework that others can build on. For a research blog
assignment, that combination is ideal. It gives you a paper that is
historically important, technically understandable, experimentally rich,
and still relevant for modern computer vision.
References
[1] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Girshick.
Mask R-CNN. ICCV 2017. Open-access paper:
https://openaccess.thecvf.com/content_ICCV_2017/papers/He_Mask_R-CNN_ICCV_2017_paper.pdf
[2] Tsung-Yi Lin et al. Microsoft COCO: Common Objects in
Context. ECCV 2014. arXiv: https://arxiv.org/abs/1405.0312
[3] matterport/Mask_RCNN. GitHub repository:
https://github.com/matterport/Mask_RCNN
[4] Zhaojin Huang et al. Mask Scoring R-CNN. CVPR 2019.
Open-access paper:
https://openaccess.thecvf.com/content_CVPR_2019/papers/Huang_Mask_Scoring_R-CNN_CVPR_2019_paper.pdf
[5] Daniel Bolya et al. YOLACT: Real-Time Instance
Segmentation. ICCV 2019. Open-access paper:
https://openaccess.thecvf.com/content_ICCV_2019/papers/Bolya_YOLACT_Real-Time_Instance_Segmentation_ICCV_2019_paper.pdf
[6] facebookresearch/detectron2. GitHub repository:
https://github.com/facebookresearch/detectron2