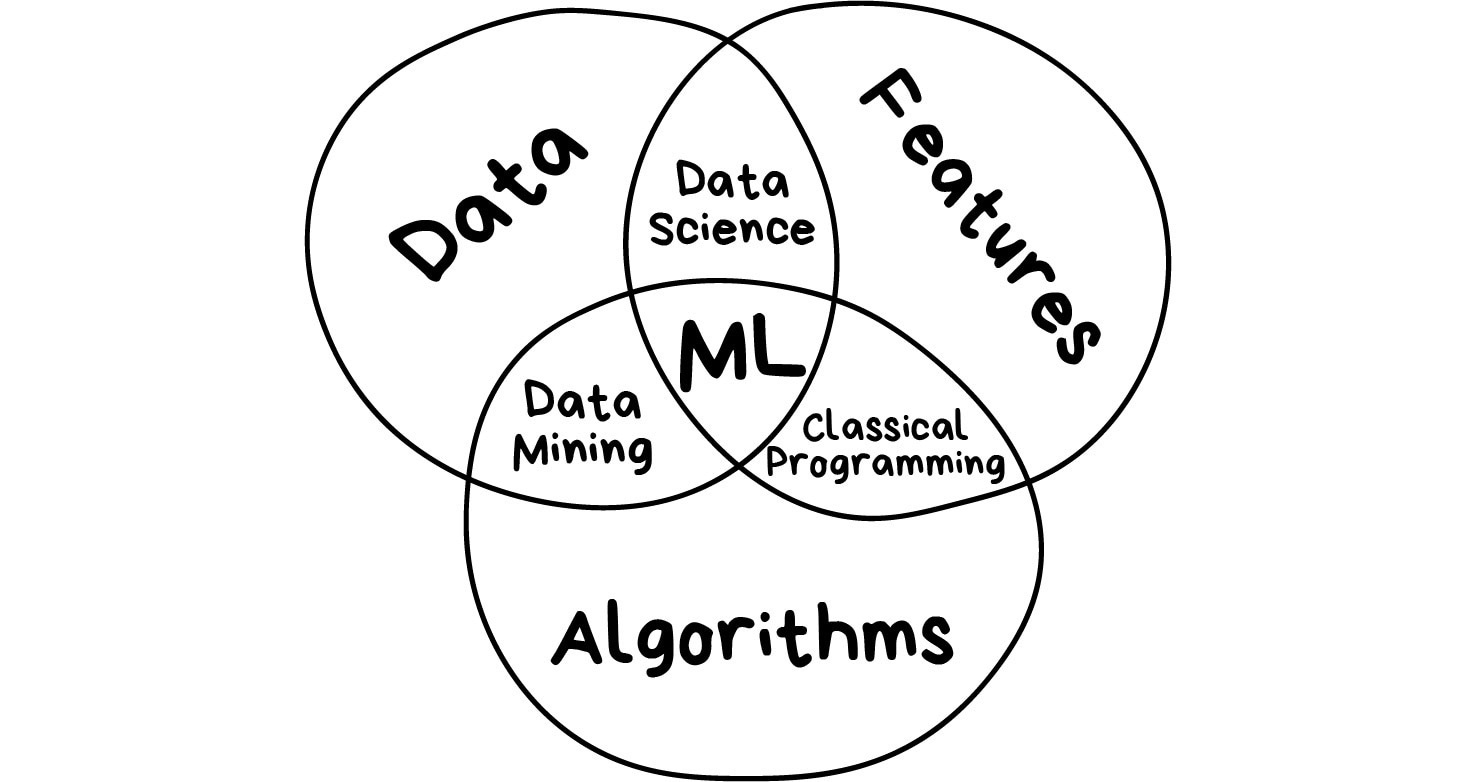
Машинное обучение простыми словами
Vitalii SavchukМашинное обучение — как секс в старших классах. Все говорят о нем по углам, единицы понимают, а занимается только препод. Статьи о машинном обучении делятся на два типа: это либо трёхтомники с формулами и теоремами, которые я ни разу не смог дочитать даже до середины, либо сказки об искусственном интеллекте, профессиях будущего и волшебных дата-саентистах.
Решил сам написать пост, которого мне не хватало. Большое введение для тех, кто хочет наконец разобраться в машинном обучении — простым языком, без формул-теорем, зато с примерами реальных задач и их решений.
Let's go!
Зачем обучать машины
Снова разберём на Олегах.
Предположим, Олег хочет купить автомобиль и считает сколько денег ему нужно для этого накопить. Он пересмотрел десяток объявлений в интернете и увидел, что новые автомобили стоят около $20 000, годовалые — примерно $19 000, двухлетние — $18 000 и так далее.
В уме Олег-аналитик выводит формулу: адекватная цена автомобиля начинается от $20 000 и падает на $1000 каждый год, пока не упрётся в $10 000.
Олег сделал то, что в машинном обучении называют регрессией — предсказал цену по известным данным. Люди делают это постоянно, когда считают почём продать старый айфон или сколько шашлыка взять на дачу (моя формула — полкило на человека в сутки).
Да, было бы удобно иметь формулу под каждую проблему на свете. Но взять те же цены на автомобили: кроме пробега есть десятки комплектаций, разное техническое состояние, сезонность спроса и еще столько неочевидных факторов, которые Олег, даже при всём желании, не учел бы в голове.
Люди тупы и ленивы — надо заставить вкалывать роботов. Пусть машина посмотрит на наши данные, найдёт в них закономерности и научится предсказывать для нас ответ. Самое интересное, что в итоге она стала находить даже такие закономерности, о которых люди не догадывались.
Так родилось машинное обучение:)
Три составляющие обучения
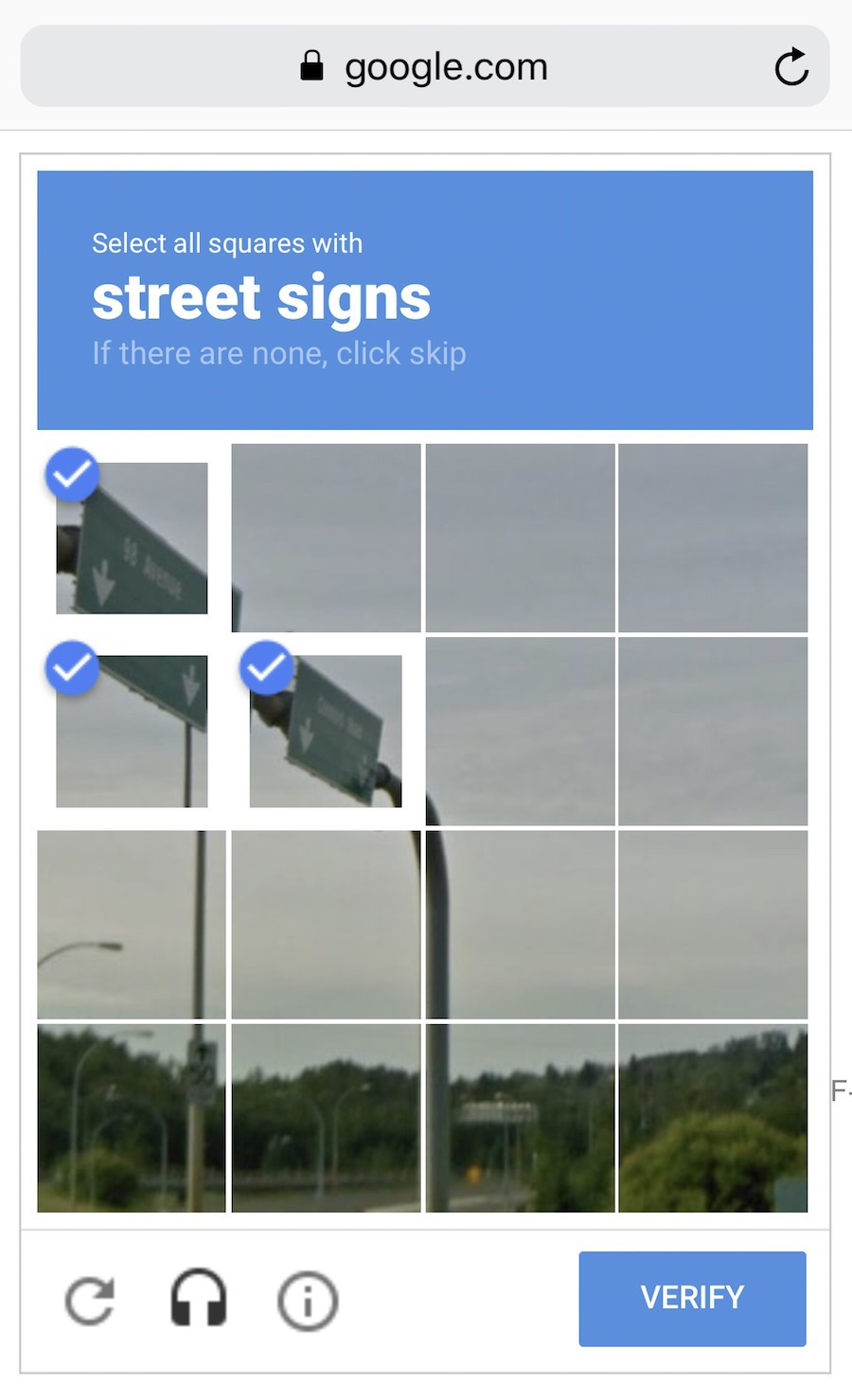
Данные | Хотим определять спам — нужны примеры спам-писем, предсказывать курс акций — нужна история цен, узнать интересы пользователя — нужны его лайки или посты. Данных нужно как можно больше. Десятки тысяч примеров — это самый злой минимум для отчаянных. Данные собирают как могут. Кто-то вручную — получается дольше, меньше, зато без ошибок. Кто-то автоматически — просто сливает машине всё, что нашлось, и верит в лучшее. Самые хитрые, типа гугла, используют своих же пользователей для бесплатной разметки. Вспомните ReCaptcha, которая иногда требует «найти на фотографии все дорожные знаки» — это оно и есть.
За хорошими наборами данных (датасетами) идёт большая охота. Крупные компании, бывает, раскрывают свои алгоритмы, но датасеты — крайне редко.
Признаки | Мы называем их фичами (features), так что ненавистникам англицизмов придётся страдать. Фичи, свойства, характеристики, признаки — ими могут быть пробег автомобиля, пол пользователя, цена акций, даже счетчик частоты появления слова в тексте может быть фичей. Машина должна знать, на что ей конкретно смотреть. Хорошо, когда данные просто лежат в табличках — названия их колонок и есть фичи. А если у нас сто гигабайт картинок с котами? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные» на его взгляд признаки и вносит в модель субъективность — она начинает дико врать.
Алгоритм | Одну задачу можно решить разными методами примерно всегда. От выбора метода зависит точность, скорость работы и размер готовой модели. Но есть один нюанс: если данные говно, даже самый лучший алгоритм не поможет. Не зацикливайтесь на процентах, лучше соберите побольше данных.