Как работает искусственный интеллект?
Автор: Джумадильдаев Медет Редактор: Сейтенов АльдинашПоследние несколько лет машинное обучение и искусственный интеллект являются одними из самых популярных тем в компьютерных науках. Как известно, компьютеры - это машины, работающие согласно строгим алгоритмам и инструкциям. Очень сложно себе представить, что компьютеры действительно могут "думать"и решать нетривиальные задачи. Поэтому возникает резонный вопрос: а как именно и по каким правилам машины обучаются? В этой статье мы приведем базовые понятия машинного обучения и анализа данных, а также рассмотрим некоторые примеры.

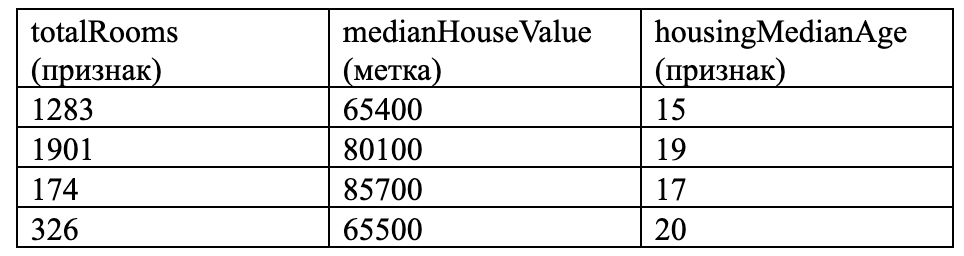
Машинное обучение – это алгоритмы, которые позволяют компьютеру учится на основе неких примеров. В данной статье мы рассмотрим эту задачу: нам в качестве статистики даны, средний возраст, количество комнат ЖК, алгоритм может предсказать цену если в зависимости от количества комнат. Для начала ознакомимся с некоторыми терминами:
Метка – это данные, которые наш алгоритм должен предсказать. Для линейной регрессии, это – y. Меткой может быть цена квартиры, порода собаки, перевод слова, и т.д.
Признаки – это входные данные, которые можно использовать чтобы найти ответ. В терминах линейной регрессии, это – x. Более сложные модели могут использовать миллионы меток.
В качестве примера можно привести цену на квартиры, город, в котором находится квартира, компания, и т.д.
Обучающая выборка – это набор признаков с известной меткой для тренировки ML-модели.
Мы используем обучающую выборку для того, чтобы улучшить модель. Например, в качестве нее можно взять нижеприведенную таблицу:
В машинном обучении выделяются два типа задач:
В задачах классификации, требуется найти дискретные значение. Например, ответы данного вида задач могут отвечать на вопросы:
- Это собака, кошка, или тюлень?
- Какое самое вероятное слово может соответствовать фразе?
В задачах регрессии, требуется найти непрерывные признаки. Например, они могут отвечать на такие вопросы:
- Какая цена такой квартиры?
- Какая вероятность того, что кто-то прочитает эту статью?
Как вы уже догадались, задача, которую мы решаем – задача регрессии.
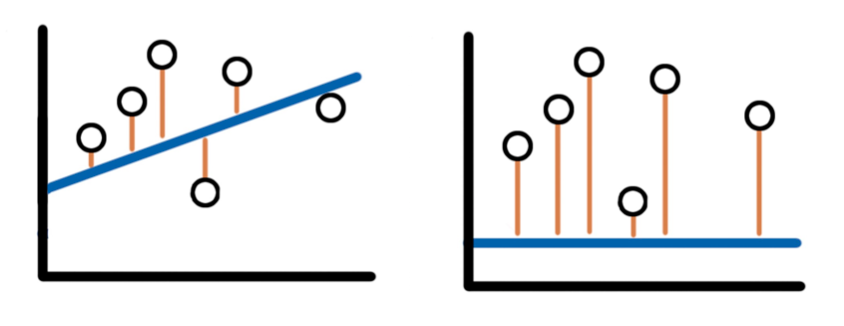
Известно, что ученики НИШ проводят меньше времени, играя в компьютер, когда увеличивается частота СОРов в неделю. Можно заметить, что отмечая точки на плоскости, мы получим почти линейную зависимость.
Конечно, график не проходит через каждую точку, но он показывает отношение между частотой СОРов и свободных часов. Таким образом, можно написать уравнение прямой (в терминах машинного обучения):
y' = b + w1x1
В данном случае,
- y' - метка,
- b – смещение,
- wi – вес i-того признака,
- xi – i-тый признак.
Таким образом, можно обобщить формулу для N признаков:
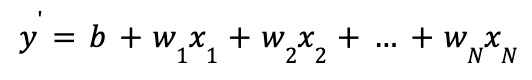
Можно заметить из формулы для общего вида, что нужно правильно подобрать значения для весов и смещения. Потому что, при изменении весов и смещения, изменяется и значение метки. Таким образом, чем меньше разница между настоящим значением и гипотезой, тем лучше модель. То есть, наша цель – уменьшить потерю.
Обычно, в качестве функции, используют среднюю квадратичную ошибку (Mean square error) для измерения потери. Такие функции называется функциями потерь.
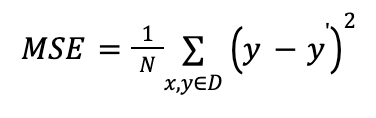
Теперь давайте поговорим про то, как можно настроить параметры так, чтобы функция потерь имела минимальное значение (потому что, уменьшение данной функции дает более точный результат). Остановитесь на момент, и подумайте. Как же можно подобрать значения для уменьшения?
Пожалуй, самый очевидный способ это – подобрать значения. Это может сработать для маленьких значений, но для больших значений нужно придумать что-то умнее. Если, вы ранее изучали математический анализ, то можно догадаться, что можно использовать градиент.
Градиент – это вектор, указывающий направление наибольшего возрастания некоторой величины . Модуль этого вектора равен скорости с которой нужно двигаться в нужном направлении.
Оказывается, что градиент можно посчитать с частными производными функции по всем независимым переменным. Таким образом, можно посчитать отрицательный градиент и найти минимум. Например, если есть функция
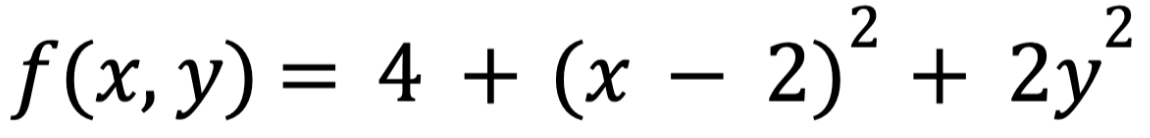
то с помощью MSE и нахождения градиента, можно показать, что минимум функции f(x,y) находится на (2, 0, 4)

Таким образом, мы находим минимум. Этот алгоритм называется градиентный спуск.
Тем не менее, можно заметить, что чем ближе значение к локальному минимуму, тем меньше модуль вектора. Это значительно замедляет алгоритм. Поэтому, есть гиперпараметры. Мы можем умножать модуль вектора на нашу константу, тем самым ускоряя процесс. К сожалению, бывают случаи, когда слишком большое значение может сломать алгоритм. Поэтому, можно экспериментировать с этими значениями, и найти самое оптимальное значение.