ML in Python. Introduction
https://t.me/notes_of_young_data_scientistПонятие машинного обучения и его основные термины
Машинное обучение - главный тренд IT в последнее время. Если простыми словами, то машинное обучение это обучение системы решению разных задач.

Существует два метода обучения:
обучение с учителем. В качестве обучения предоставляется training data, то есть по факту сборник {признаки(features) : ответ}.
обучение без учителя. Метод обучения, когда система сама обучается решать поставленную задачу без внешнего вмешательства.
Многие задачи машинного обучения делятся на два типа:
классификация - задача точно определить к какому классу принадлежит множество признаков.
регрессия - задача как наиболее точно оценить какую-то величину в зависимости от разных факторов
Вся работа ML изображена в этой "диаграмме":

Здесь куча "заумных" слов, и мы будем использовать "простонародские" термины. Первый этап - получение данных и их обработка. Очень редко данные поступают в таком виде, как нам надо.
В качестве примера возьмём выборку характеристик листьев ириса: [длина, ширина, кол-во жилок]. Ввиду существования различных мер измерения длины(сантиметры, дюймы) мы должны обработать данные так, как нам надо(к примеру, слишком маленькие значения перевести в сантиметры).
В этом примере длина, ширина, кол-во жилок являются признаками(features). Выборка: единичный набор признаков и соответствующий ответ для него(если мы используем обучение с учителем).
Далее вводимые данные делятся на тренировочные и тестовые(train, test). Обычно они делятся в соотношении 3/1. На traindata наша система будет обучаться, а с помощью testdata мы оценим правильность работы системы.
Затем, если правильность работы нас устраивает, то мы можем прогнозировать результат уже для других данных.
Практика
К сожалению, если рассказывать о всех алгоритмах обучения, то выйдет слишком долго и занудно, потому мы разберём один, а далее продолжим по нарастанию. Обозреваемым алгоритмом станет метод k-ближайших соседей.
Однако это позже.
Нам стоит определиться с нашими инструментами для работы.
В качестве стека технологий для начинающих будет лучше всего связка Python & Numpy, SciPy, scikit-learn, Pandas, matplotlib, jupyter notebook. Кратко разберём каждый из пакетов:
NumPy - пакет для математических вычислений.
SciPy - пакет для символьной математики (в этой статье использоваться не будет).
scikir-learn - пакет, содержащий классы моделей базовых алгоритмов машинного обучения.
Pandas - пакет для работы с данными (в этой статье использоваться не будет).
matplotlib - библиотека для различных математических построений.
jupyter notebook - интерактивная среда разработки, упрощающая работу с ML.
Каждый пакет можно установить командой:
pip/pip3 install [package], где package - название пакета только маленькими буквами.
Показанным примером будет реальный набор данных по раку молочной железы Университета Висконсин(cancer - если кратко). Этот пример взят из книги "Введение в машинное обучение с помощью Python" от Андреаса Мюллера и Сары Гвидо. Полезные материалы я укажу в конце статьи.
Я взял этот пример, поскольку загрузить датасет мы можем прямо из модуля scikit-learn. Для запуска среды мы прописываем команду
jupyter notebook
Копируем указанную ссылку, если заходим в первый раз, и перед нами открывается такое окно:

Выбираем New >> Python 3.
Я не буду расписывать всю работу с этим инструментом, по типу магических функций и т.д., поскольку это несколько отличается от моей цели, да и это легко узнать из оф. документации.
Загружаем датасет путем импортирования из модуля:
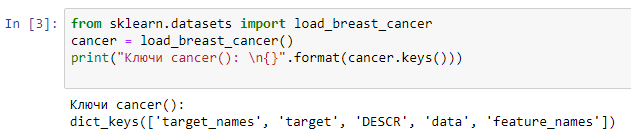
Видим, что весь датасет представляет собой структуру данных, похожую на словарь.

Массив cancer.data является двумерным, где первое число является его длинной, второе является кол-вом признаков тестового набора.
Чтобы узнать имена признаков, просто "распечатаем" cancer.feature_names:

Вся информация в текстовом виде о датасете лежит в поле 'DESCR':

Также давайте распечатаем первые пять тестовых данных.

И так можно исследовать каждое из полей датасета.
Как уже указывалось ранее, обозревать мы будем алгоритм k-ближайших соседей.
Работает он довольно просто: выстраивает диаграмму признаков в точечном виде, и выбирает k ближайших соседей :) Какого типа соседей больше, такое и предсказание будет у нашего классификатора. Лучше это понять по иллюстрации:

Стрелочками изображено, каких соседей "выбирают" точки. В данном случае k = 1, потому точки "выбирают" только одного соседа.
Пример для k = 3:

Далее импортируем функцию для разбивания набора на train и test:

Видим, что выбралось 426 выборок из всего сета. Также стоит создать модель для обучения. В scikit-learn для этого есть отдельный класс:

Устанавливаем кол-во соседей, равное 3, и двигаемся дальше:

Метод .fit() служит для обучения модели на основе traindata. Теперь мы можем предсказывать результат для других данных.
Как мы видим, метод .fit() возвращает саму модель. Позже мы провернём с этим один фокус.
После этого, предскажем результаты для testdata. Чтобы получить прогноз, воспользуемся методов .predict().

И напоследок проверим правильность нашей модели обучения:

Округляем результат до двух знаков после запятой и получаем правильность 0.92. Довольно неплохо, как для первого опыта в ML :)
Также хочется провести исследование алгоритма k-ближайших соседей в зависимости от кол-ва "соседей".

Видно плоховато, однако весь код можно будет скопировать по ссылке, которую я укажу в конце статьи.
Сверху магическая команда, которая выводит построения matplotlib в сам блокнот. Полученный результат:

Здесь мы ставим приоритет на правильность на тестовом наборе, и замечаем, что при 6-ти соседях правильность больше всего. Хотя разница в доли процента, однако и она может сыграть свою роль.
Использование
Использовать Machine Learning можно практически во всех сферах.
Очевидным примером является сортировка пользовательского контента в соц.сетях, сортировка отзывов посетителей кинотеатров и др.
Почти каждая компания из Fortune 500 делает все больше и больше денег благодаря машинному обучению.
Пара примеров:
- Pinterest, к примеру, уже использует МО чтобы показывать вам более интересный контент;
- Yelp пользуется им для сортировки загруженных пользователями фотографий;
- NextDoor оно нужно, чтобы сортировать контент у себя на досках объявлений;
Невозможно недооценить значимость машинного обучения в теории игр и прогнозировании различных числовых значений.
Продвижение
В дальнейшем продвижении вам помогут:
Kaggle - платформа для соревнования в ML. Там вы сможете найти датасеты, всяческие подсказки и др.
"Введение в машинное обучение с помощью Python", Андреас Мюллер и Сара Гвидо - книга, откуда и был взят сегодняшний пример. Отлично подойдёт для новичков из-за множества примеров кода и набора своих функций mglearn.
Ведь код из статьи можно найти здесь.
Присоединяйтесь к моему телеграмм-каналу, там будет много подобных материалов.