Лучшие практики Python для специалистов по обработке данных
https://t.me/data_analysis_mlПроблема
Если вы когда-либо «гуглили» одни и теже вопросы, термины или синтаксис снова и снова, знайте — вы не одиноки.
Я делаю это постоянно! Это нормально, если вы постоянно заглядываете на StackOverflow или на другие ресурсы в поисках ответов на ваши вопросы. Однако это замедляет ваш рабочий процесс и ставит знак вопроса относительно вашего полного понимания языка. Сегодня, у нас есть бесконечное множество свободных и доступных источников информации, найти которые мы можем по одному запросу в поисковике — в любое удобное для нас время. Однако данное явление может стать как благословением, так и проклятием. Иногда мы просто не в состоянии эффективно обрабатывать большие объемы информации. Кроме того, ежеминутно обращаясь к различным информационным ресурсам, мы начинаем зависеть от них — что в долгосрочной перспективе может стать очень плохой привычкой.

Однажды, я заметил за собой одну особенность: на протяжении определенного времени, я несколько раз просто копировал фрагменты кода с различных тематических форумов, вместо того чтобы заняться изучением и закреплением на практике некоторых концепций в языке, чтобы в будущем подобных проблем у меня не возникло. Такой подход я называю ленивым подходом. Конечно, в краткосрочной перспективе это сэкономит вам определенное количество времени, однако в конечном итоге вы станете менее продуктивным и это немало навредит вашему профессиональному и карьерному росту.Цель
Не так давно я начал изучать онлайн-курс на Udemy под названиями «Python for Data Science and Machine Learning» («О я говорю как этот парень с Youtube»). На первых занятиях мне напомнили некоторые концепции и синтаксис, которые я постоянно упускаю из виду при выполнении анализа данных на Python. Для того чтобы закрепить в памяти изученный материал и немного упростить вам жизнь и сэкономить время — я написал эту статью. В ней мы рассмотрим несколько концепций, которые многие из нас забывают при работе с Python, NumPy и Pandas. Для каждой концепции я написал краткое описание и примеры. Для лучшего усвоения, я добавил ссылки на видео-уроки и другие ресурсы, которые также помогут вам в изучении каждой концепции.Понимание однострочных списков
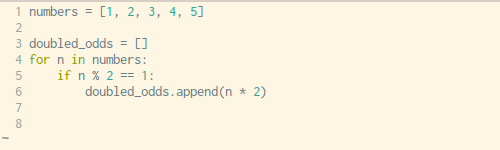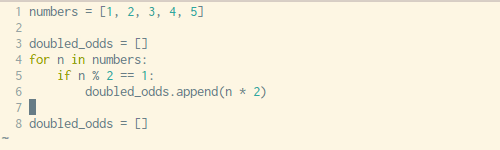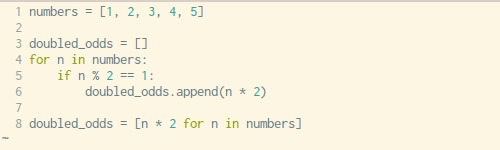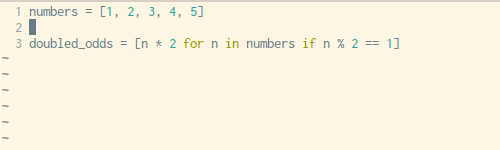
Писать цикл for каждый раз, когда вам нужно определить какой-то список — утомительно. К счастью, Python может решить эту проблему одной строчкой кода. Синтаксис может показаться вам немного сложным для понимания, но как только вы познакомитесь с ним и научитесь применять его на практике- вы будете использовать его довольно часто.
Посмотрите на примеры выше и ниже. Здесь вы увидите, как мы обычно понимаем списки в Python с помощью цикла for против создания списка с помощью одной единственной строчки кода, о чем я и говорил.x = [1,2,3,4]
out = []
for item in x:
out.append(item**2)
print(out)
[1, 4, 9, 16]
# vs.
x = [1,2,3,4]
out = [item**2 for item in x]
print(out)
[1, 4, 9, 16]
Lambda — функции
Посмотрите на примеры выше и ниже. Здесь вы увидите, как мы обычно понимаем списки в Python с помощью цикла for против создания списка с помощью одной единственной строчки кода, о чем я и говорил.x = [1,2,3,4]
out = []
for item in x:
out.append(item**2)
print(out)
[1, 4, 9, 16]
# vs.
x = [1,2,3,4]
out = [item**2 for item in x]
print(out)
[1, 4, 9, 16]
Lambda — функции
Вы когда-нибудь уставали от создания функции после функции ограниченного использования? Если да, то Lambda придет к вам на помощь! Лямбда-функции используются для создания небольших, одноразовых и анонимных объектов функций в Python. Они позволяют создавать функции без создания функции. Основной синтаксис Lambda- функции:
lambda arguments: expression
Обратите ваше внимание на то, что Lambda- функции могут выполнять все то же самое, что и обычные функции, если есть только одно выражение. Ознакомьтесь с простым примером ниже, и видео, которое будет далее, для того чтобы лучше разобраться с функцией Lambda и познать всю ее мощь:
double = lambda x: x * 2 print(double(5)) 10
Map и Filter
Как только вы полностью разберетесь с Lambda- функциями, изучите возможность их сопряжения с функциями map и filter — в дальнейшем это может стать мощным инструментом для вас. В частности, map берет список и преобразует его в новый список, выполняя определенные операции над каждым элементом. В примере ниже она проходит через каждый элемент и выводит результат в новый список. Обратите внимание: функция list просто преобразует вывод в список.
# Map seq = [1, 2, 3, 4, 5] result = list(map(lambda var: var*2, seq)) print(result) [2, 4, 6, 8, 10]
Функция Filter принимает список и правило фильтрации, подобно функции map, однако возвращает подмножество исходного списка, сравнивая каждый элемент с логическим правилом фильтрации.
# Filter seq = [1, 2, 3, 4, 5] result = list(filter(lambda x: x > 2, seq)) print(result) [3, 4, 5]
Arange и Linspace
Для создания быстрых и простых массивов в NumPy используйте функции arange и linspace. Каждая из этих функций имеет свое специфическое предназначение, но они привлекательны (в отличии от использования диапазона) тем что они выводят массивы NumPy, с которыми зачастую, в дальнейшем, намного проще работать. Arange возвращает равномерно расположенные значения в пределах заданного интервала. Наряду с начальной и конечной точкой вы также можете определить размер шага или тип данных, если это необходимо. Обратите внимание на то, что конечная точка интервала значится как ‘cut-off’, поэтому она не будет включена в выходные данные массива.
# np.arange(start, stop, step) np.arange(3, 7, 2) array([3, 5])
Linspace очень похож на функцию Arange. Функция Linspace возвращает равномерно расположенные числа за указанный интервал, при этом учитывая начальную и конечную точку интервала и ряд других данных — все это linspace равномерно распределит в массиве NumPy. Это особенно полезно для визуализации данных и при построении осей графика.
# np.linspace(start, stop, num) np.linspace(2.0, 3.0, num=5) array([ 2.0, 2.25, 2.5, 2.75, 3.0])
Что на самом деле обозначает ось?
Вы наверняка сталкивались с этим, когда удаляли столбец в Pandas или складывали значения в матрице NumPy. Если же не сталкивались, готовьтесь к тому, что этот момент обязательно наступит. Сейчас мы рассмотрим эту проблему на примере удаления столбца:
df.drop('Column A', axis=1)
df.drop('Row A', axis=0)
Уже и не помню, сколько раз я писал эти строки кода, прежде чем понял, для чего я прописывал значения осям. Как вы можете догадаться, исходя из вышеприведенного кода, установив значение на 1, вы получите столбцы, а значение 0 дает строки. Но почему именно так? Вот мое мнение на этот счет:
df.shape (# of Rows, # of Columns)
Вызов атрибута shape из датафрейма Pandas возвращает нам tuple (кортеж) с первым значением, обозначающим число строк, и вторым значением, обозначающим количество столбцов. Вы можете спросить: «Как это индексируется в Python?». Так вот, строки находятся в 0, а столбцы в 1, так же, как и при значении оси.Функция Concat, Merge и Join
Если вы знакомы с SQL, то вам будет намного проще разобраться с этим функциями. А если не знакомы, достаточно знать, что эти функции объединяют датафреймы конкретными методами. Но бывает достаточно тяжело отследить, в какое время и при каких обстоятельствах использовать эти функции. Не бойтесь, я вам в этом помогу. Функция Concat позволяет пользователю добавлять один или несколько датафреймов друг к другу, либо в столбец, либо друг за другом в ряд(в зависимости от того, как вы определяете ось).
Функция Merge объединяет несколько датафреймов в определенных, общих столбцах, которые служат в качестве первичного ключа.
Функция Join, подобно Merge, объединяет два датафрейма. Однако она объединяет их на основе индексов, а не общего столбца.
Для более полного понимания, ознакомьтесь с документацией Pandas. Узнайте больше про особый синтаксис, а также прочтите про специальные случаи, с которыми вам скорее всего придется столкнуться.
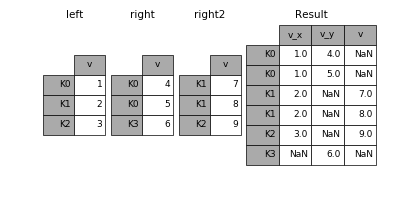
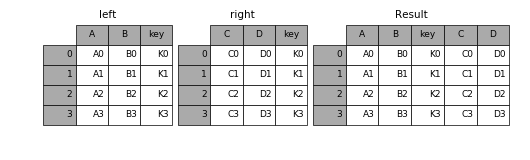
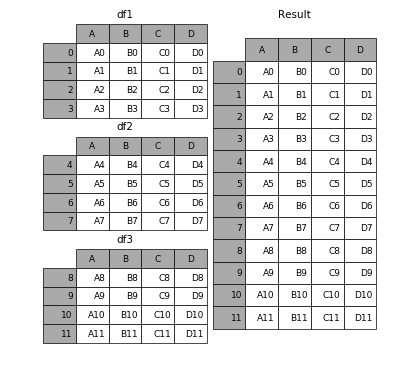
Использование Apply в Pandas
Apply это что-то вроде map функции, но в датафреймах Pandas или скорее в Series. Если вы не знаете, Series во многом очень схож с массивами NumPy. Apply передает функцию каждому элементу вдоль столбца или строки, в зависимости от того, что вы задали. Вы даже не можете себе представить, насколько это полезно, особенно для форматирования и обработки значений по всему столбцу датафреймов, без необходимости в циклах.
Теперь обратимся к рекомендациям, изложенным в PEP8.
Стиль именования
- Переменные, функции, методы, пакеты, модули:
- Строчные буквы, слова разделены нижним подчёркиванием: например,
check_pass
2. Классы и исключения:
- Заглавная буква в начале, верхний регистр между словами вместо пробела:
CamelCase, например,JustCounter.
3. Защищённые методы и внутренние функции:
- Знак подчёркивания впереди:
_start_engine
4. Приватные методы:
- Два знака подчёркивания впереди:
__foo(self, ...).
5. Константы:
- Верхний регистр:
IP_SERVER='111.11.11.11'
6. Лучше использовать обратную нотацию:
elements = ... active_elements = ... defunct_elements ...
Отступ
Используем 4 пробела и никакой табуляции.
Импортирование
- Порядок импорта должен быть следующим:
1. Встроенные пакеты Python. 2. Пакеты сторонних разработчиков. 3. Локальные пакеты.
Длина строки
Стараемся разбивать строку длиннее 80 символов.
even_numbers = [var for var in range(100)
if var % 2 == 0]
Иногда дальше разбивать не получается, особенно в случае с цепочкой методов.
Пробел
- Обязательно ставим пробел между двоеточием и значением ключа в словаре:
names = {'gagan': 123}
2. Ставим пробел между операторами в случае арифметических операций и операций присваивания:
var = 25 math_operation_result = 25 * 5
3. Не ставим пробел между операторами при передаче в качестве параметра:
def count_even(num=20):
pass
4. Ставим пробел после запятой:
var1, var2 = get_values(num1, num2)
Документация
Следуем рекомендациям в PEP 257, чтобы научиться документировать программу на Python.
- Используем однострочную форму документирования для очевидных функций:
"""Return the pathname of ``foo``."""
2. Многострочная документация должна состоять из:
Строки с кратким описанием Случая использования, если есть Аргументов Типа возвращаемого значения и семантики, если не возвращено None
Пример:
class Car:
"""A simple representation of a car.
:param brand: A string, car's brand.
:param model: A string, car's model.
"""
def __init__(self, brand, model):
self.brand = brand
self.model = model
class Car:
"""A simple representation of a car.
Последним, но не менее важным пунктом стоят сводные таблицы. Если вы знакомы с Microsoft Excel, то вы, с вероятностью в 100%, слышали о сводных таблицах. Встроенная функция pivot_table в Pandas создает сводную электронную таблицу в виде датафрейма. Обратите внимание, что уровни в сводной таблице хранятся в виде мультииндексовых объектов.Заключение
Вот и все, что я хотел вам рассказать. Я надеюсь, что эта статья помогла вам понять или может быть освежить в памяти важные, но в некоторых моментах сложные методы, функции и концепции, с которыми вы часто сталкиваетесь при использовании Python в работе с данными. По личному опыту могу сказать, что даже само написание этой статьи помог мне во многом разобраться.