LoRa
Допустим, вы хотите дообучить GPT-2 на Q&A вашего продукта. В стандартном сетапе DDP + mixed precision(fp16|fp32) вам понадобится как минимум V100 32Gb.
А что если у меня есть только 4070 дома? Тут нам на помощь и приходит LoRa.
Есть предположение, что изменение весов (дельта, которую мы добавляем к изначальным весам) в процессе адаптации модели может иметь низкий ранг. Вспомним, что такое ранг - максимальное количество линейно независимых строк. Линейно независимая строка - строка, которую нельзя представить как линейную комбинацию других строк этой матрицы.
И вот вопрос: что, если мы будем дообучать не всю модель и даже не отдельные ее слои, а всего лишь некоторое матричное разложение матрицы низкого ранга?
В чем плюс:
- нет избыточных костов на хранение градиентов всей модели;
- можно дообучать много разных "адаптеров" на разные задачи;
- можно комбинировать с другими адаптерами(надстройками над базовыми слоями модели).
По сути, мы пытаемся уложить все шаги градиентного спуска в рамках файнтюнинга в один, причем это шаг зависит от другого набора параметров, который в разы меньше исходного множества параметров модели.
Что можно использовать вместо:
— BitFit — файнтюнить только bias вектора, остальные параметры модели заморожены.
—Префикс-эмбеддинг тюнинг — давайте вставим серию токенов перед текстом, скажем, что это эмбеддинги этих токенов — наши обучаемые параметры, и будем тюнить их. Основная модель все также заморожена, но из минусов — мы отнимаем полезное место под промпт.
— Префикс-слой тюнинг — а зачем нам учить эмбеддинги этих префиксных токенов, если можно сразу учить активации после каждого слоя?
Окей, теперь коротко формула самого процесса:
Мы пытаемся найти две матрицы B и А, чтобы при произведении они давали размерность исходных весов модели, при этом обе матрицы - ранга r.
W_0 + deltaW = W_0 + BA - что мы хотим получить.
forward - W_0*X + alpha_r * B*A*X
A - gaussian, B - нулевая матрица изначально.
alpha_r - метапараметр скорости сходимости
Ну раз мы файнтюним, то у нас и лосс есть, а значит, есть по чему градиенты считать. Таким образом, мы ищем оптимальные B и A, минимизирующие наш лосс.
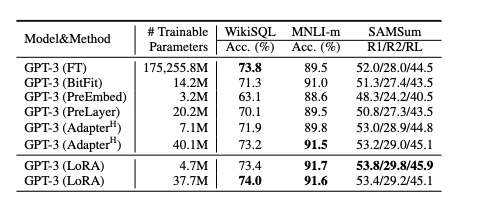
Еще дополнительно реально нужно подбирать r, так как иногда высокий ранг может ухудшать качество.
Почему — есть предположение, что за первые несколько векторов в подпространстве выучивается наиболее полезная информация, а дальнейшие — только докидывается шум. Очень похоже на PCA, не находите?
В целом, ребята показывают некоторые выкладки на тему похожести выученной матрицы и изначальных весов модели. Ну а раз мы можем предположить, что дельта весов — это матрица низкого ранга, то почему бы не использовать ту же схему для обучения изначальной модели?