Linux auditd для обнаружения угроз [Финал]
Это последняя часть серии - и, на мой взгляд, самая интересная. Очень рекомендую сначала прочитать части 1 и 2.
В этой статье мы сосредоточимся на том, какие именно действия приводят к появлению тех или иных событий в auditd. Кроме того, вы увидите, в каких случаях auditd не способен зафиксировать события - даже при максимально «болтливых» настройках.
К концу статьи у вас должны появиться ответы на следующие вопросы:
- Что вообще умеет записывать auditd?
- Какие события auditd пропускает?
- Сколько типов записей auditd генерирует для конкретного действия?
Небольшой дисклеймер: статья насыщена содержанием. Но задумывалась она как справочник - чтобы к ней можно было обращаться при разборе логов или создании правил детектирования. Быстрое прочтение даст понимание структуры материала, а дальше лучше просто сохранить её в закладки и возвращаться по мере необходимости.
Рекап и введение
В первой части серии мы разобрали базовое введение в auditd, какие события имеет смысл логировать и пару моментов про масштабируемость.
Во второй части - на примере запуска процесса - посмотрели, как расследовать логи auditd.
Если помните из первой части:
Событие в Linux может привести к появлению нескольких записей auditd. Есть одно основное событие и набор вспомогательных записей разных типов (record types). Эти вспомогательные записи содержат дополнительную информацию. Их количество зависит от того, по какому пути системный вызов (syscall) проходит в ядре и в каких местах auditd «подцепляется» к этому пути. Насколько мне известно, на данный момент не существует таблицы соответствия между syscall и генерируемыми типами записей.
На сегодняшний день такой таблицы я так и не нашёл.
Мы охотимся за противником, опираясь на разные артефакты - и логи событий один из них. Мы рассчитываем, что именно логи расскажут нам историю произошедшего. Но помимо понимания семантики конкретного события и того, что оно вообще способно сообщить, не менее важно знать, какие именно записи генерируются при определённом поведении - и почему.
Идея простая: если вы понимаете, что именно auditd может рассказать вам о конкретном действии (и по какой причине), то сможете лучше решить, что действительно стоит мониторить в вашей организации, а также быстрее разбираться в логах, которые попадают к вам на расследование.
На мой взгляд, эта тема куда глубже проработана в экосистеме Windows, чем в Linux. Есть отличные статьи, где разбирается цепочка логов, возникающих при конкретной операции в Windows. Отдельно стоит упомянуть проект EVTX-ATTACK-SAMPLES от @SBousseaden - отличная база, когда нужно ответить на вопрос: «А как эта атака будет выглядеть в логах?».
С auditd всё сложнее. Из-за того, как устроена подсистема аудита в Linux, чтобы понять, как будут выглядеть логи для конкретной операции, нужно разобраться в двух вещах:
- Какие syscall’ы будут вызваны при выполнении операции - это относительно легко определить по природе действия (создание файла, запуск процесса, сетевое соединение и т.д.)
- По какому пути этот syscall проходит в ядре и где именно auditd может его перехватить - а вот это уже куда менее очевидно
В этой статье мы попробуем ответить на эти вопросы для ряда типичных действий, которые интересны нам как защитникам. Посмотрим на серию выполнений различных операций/поведений и разберём, что именно auditd способен зафиксировать в каждом случае.
Внутри статьи вы найдёте:
- матрицу с набором распространённых действий и соответствующими типами записей, которые генерирует auditd
- «сырые» и обогащённые примеры логов для каждого случая (через GitHub)
Подробно разбирать каждую строку я не буду - вторая часть уже дала для этого необходимый контекст. Вместо этого я выделю отдельные моменты там, где это действительно важно.
И ещё один момент: в отличие от упомянутого выше EVTX-проекта, я не работаю на уровне техник или процедур. Я фокусируюсь на уровне источника данных.
Источник данных -> тип записи
Для удобства снова привожу источники данных MITRE - чтобы можно было быстро к ним вернуться.
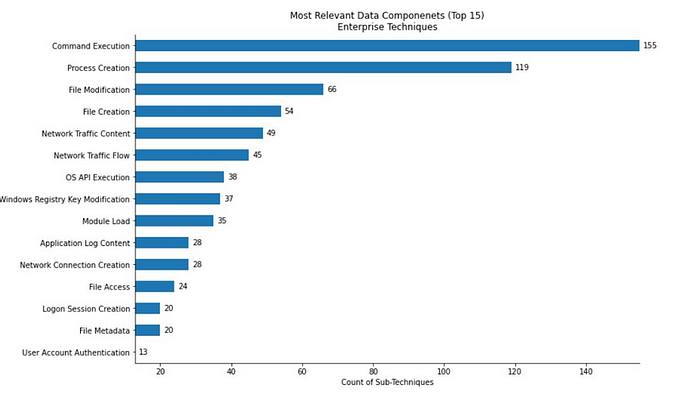
Опираясь на них, я расширил простую таблицу соответствия «источник данных ↔ правило auditd» из первой части до более полной схемы:
источник данных ↔ правило auditd ↔ смоделированное поведение ↔ сгенерированные типы записей
Заодно я обновил часть правил.
Ссылка на таблицу:
https://docs.google.com/spreadsheets/d/1OPX-RXl_OKhwsqbWUqyGJvREim2K6sAOVUYKMmlxMNM/edit?usp=sharing
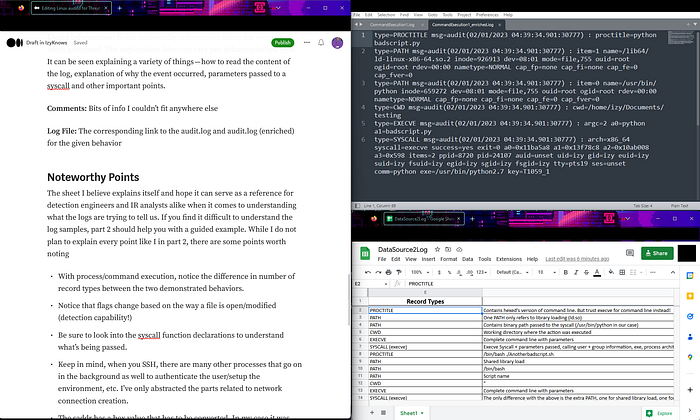
Чтобы проще ориентироваться в следующих разделах, рекомендую открыть три окна - желательно рядом друг с другом:
- этот блог
- указанную Google-таблицу
- соответствующий лог-файл для каждого поведения (ссылка есть в таблице)
Как устроено соответствие
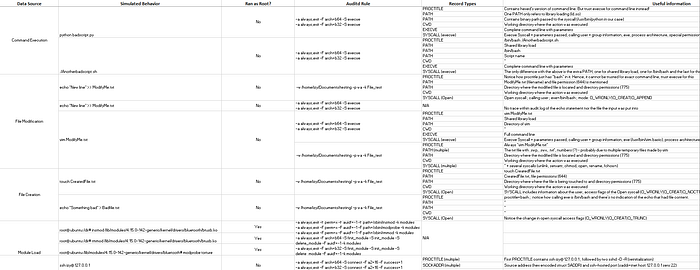
В таблице вы найдёте все источники данных из схемы MITRE, которые применимы к auditd, а также следующие колонки:
Simulated Behavior - команды, которые выполнялись, чтобы сгенерировать события для соответствующего источника данных.
Ran as Root? - указывает, запускалось ли поведение с правами root. В целом это не должно влиять на логи, если отдельно не указано иное.
Auditd Rule - правило (или правила) auditd, которые были активны в момент выполнения данного поведения. Обратите внимание: кроме указанных в строке правил, никакая дополнительная фильтрация в audit.rules не применялась.
Record Types - список всех типов записей, которые появились в audit.log после выполнения смоделированного поведения.
Useful information - важные замечания по конкретному событию. Содержимое этой колонки может отличаться в зависимости от поведения и типа записи: где-то это пояснение, как читать лог, где-то - почему событие вообще возникло, какие параметры были переданы в syscall, и другие существенные детали. Максимальный смысл эта колонка имеет, если смотреть её параллельно с реальным «сырым» логом (из GitHub).
Comments - информация, которую не удалось органично разместить в других колонках.
Log File - ссылка на соответствующий audit.log и его «обогащённую» версию для конкретного поведения.
На что стоит обратить внимание
Таблица, как мне кажется, достаточно самодостаточная и может служить справочником - как для detection-инженеров, так и для IR-аналитиков, когда нужно понять, что именно пытаются рассказать нам логи. Если примеры логов кажутся запутанными, вернитесь ко второй части - там есть подробный разбор на конкретном примере.
Я не буду разжёвывать каждый пункт, как раньше, но есть несколько моментов, на которые стоит обратить внимание:
- Man-страницы системных вызовов (syscalls) отлично помогают понять, какие аргументы передаются и что они означают.
- В сценариях с запуском процессов/команд обратите внимание на разницу в количестве типов записей между UC001 и UC002. Оно может меняться в зависимости от того, каким образом вызывается
execve(). Важно понимать, что именно происходит «под капотом» при запуске. - В UC001 Python (найденный через переменную окружения
$PATH, не путать с типом записиPATH) скорее всего вызывается напрямую, а имя файла передаётся как параметр. - В UC002 (запуск через bash) мы указываем
/в команде, тем самым явно задаём путь к исполняемому файлу (в.) и обходим поиск по$PATH, выполняя его через текущую оболочку. - Объяснить абсолютно всё не всегда получится, но эти два примера дают представление о повторяющихся паттернах, которые можно применить к другим способам запуска.
- В кейсах, связанных с операциями над файлами (UC003–UC006), обратите внимание, как меняются флаги (
a1) в зависимости от способа открытия или модификации файла. Комбинации флагов позволяют понять, с каким намерением файл был открыт. - Несмотря на разные способы выполнения файла, мы не видим изменённое содержимое - даже если мониторим
execve. Если кто-то знает способ увидеть содержимое изменений через auditd, дайте знать. - UC003 - хороший пример того, почему
PROCTITLEнельзя считать надёжным источником полной командной строки. С пайпами и редиректами он справляется плохо. - В UC006 использование
vimпри мониторинге каталога генерирует целую лавину событий - потому чтоvimв процессе работы создаёт множество временных файлов. - UC009–UC011: мне так и не удалось добиться логирования загрузки модулей, хотя я пробовал разные, вполне стандартные команды. Если у кого-то получится это воспроизвести - обновлю таблицу.
- При SSH (UC012) в фоне происходит гораздо больше процессов: аутентификация, настройка окружения и т.д. Здесь я абстрагировался и оставил только ту часть, которая относится к созданию сетевого соединения.
- Поле
saddr(UC012, UC013) содержит IP-адрес в hex-виде - его нужно декодировать. В моём случае это был0.0.0.0, потому что я подключался по ssh с того же хоста. Формат кодирования довольно специфичный; вот пример запроса для Splunk, который помогает расшифровать значение:
| eval ipaddr = substr(saddr,9,30)
| rex field=ipaddr "(?i)(?<d1>[0-9A-F]{2})(?<d2>[0-9A-F]{2})(?<d3>[0-9A-F]{2})(?<d4>[0-9A-F]{2})"
| eval ip=tostring(tonumber(d1,16))+"."+tostring(tonumber(d2,16))+"."+tostring(tonumber(d3,16))+"."+tostring(tonumber(d4,16))
- При создании сетевого соединения вы получаете IP назначения, а также информацию о процессе и пользователе, которые его инициировали - крайне полезно.
- UC016: «метаданные файла» как поведение - это очень широкое понятие. По определению MITRE:
Контекстные данные о файле: имя, содержимое (подписи, заголовки, данные/медиа), владелец, права доступа и т.д.
- Auditd - это не polling-решение вроде OSQuery, поэтому информацию о файле мы получаем только тогда, когда процесс с ним взаимодействует. В данном случае я сосредоточился на изменении прав доступа. Просматривая техники MITRE, связанные с этим источником данных, я не нашёл других сценариев, которые auditd мог бы корректно покрыть.
- Другие операции с файлами (запись, чтение, исполнение, изменение атрибутов) уже были разобраны ранее.
- Для отслеживания изменений прав я выбрал мониторинг конкретных команд -
chown,chmod. При этом также имеет смысл отслеживать системные вызовы изменения атрибутов (fchmod,fchown,lsetxattrи т.д.). В первой части приведён расширенный список таких syscall’ов вaudit.rules. - UC017/UC018: для мониторинга аутентификации в целом я рекомендую использовать
secure.logилиauth.log. Auditd тоже может дать эту информацию - для сравнения я показал оба варианта. - UC017:
USER_AUTHвыглядит более надёжным, чемUSER_LOGIN. ВUSER_LOGINя замечал пропуски некоторых значений. - И будьте осторожны: если вы мониторите неудачные SSH-логины через
audit.log, то в зависимости от набора правил получите массу дополнительных событий с результатомsuccess. Например, обращения кhosts.allow,hosts.deny, вызовconnectи другие сетевые операции будут отображаться как успешные. Нас же интересует именно итог аутентификации - успешна она или нет. В приложенном логе фокус именно на этом.
Заключение
Информации получилось много. Текста тоже немало, но надеюсь, несмотря на объём, всё остаётся понятным. Тестирование заняло прилично времени, но было действительно интересным - многие результаты удивили и меня самого. Я пытался найти более надёжный способ определить вспомогательные события, копаясь в исходниках, но код оказался настолько разбросанным, что «брутфорс» через практические эксперименты в итоге оказался эффективнее.
Как уже говорил, этот материал задумывался как справочник - для IR-аналитиков, detection-инженеров, threat hunter’ов и вообще всех, кто пытается разобраться в логах auditd и научиться использовать их для поиска угроз.