Linux auditd для обнаружения угроз [Часть 2]
В первой части мы познакомились с auditd и разобрали основы написания правил. Я порекомендовал материалы для чтения и настройки, которые хорошо зарекомендовали себя в моей практике. Мы прошлись по наиболее релевантным источникам данных из MITRE и обсудили, какие правила auditd помогут их фиксировать. В конце поговорили о снижении шума и о том, как заставить auditd нормально работать в больших и разнородных окружениях.
Самым ценным выводом из первой части, на мой взгляд, было сопоставление правил ↔ источников данных и список рекомендуемых исключений. В этой части цель такая:
- подробно разобрать одно событие auditd
- посмотреть, какие поля особенно интересны нам с точки зрения поиска противника
- обсудить несколько приёмов расследования логов в Splunk
Этот пост будет довольно лёгким и по сути служит прологом к третьей части, которая выйдет вскоре после этой.
По ходу статьи я буду делиться своим опытом и разбирать вымышленные сценарии в контролируемой среде.
Безопасность в логах
Давайте возьмём какое-нибудь поведение, выполним его и потом залезем в логи, чтобы разобрать, что означают разные поля и какие из них потенциально могут быть нам полезны.
Я сосредоточусь на простом запуске скрипта через Python. Конкретный процесс здесь не так важен - важнее понять, как сама техника отражается в логах системы. Большая часть того, что вы увидите ниже, легко переносится на другие действия: создание или изменение файлов, сетевые события и т.д. В этой части я разберу только одну технику (запуск процесса/команды) и объясню поля. В части 3 покажу результаты тестов для других типов поведения.
Выполнение команды
Когда выполняется команда, системный вызов execve запускает программу. С точки зрения обнаружения атак это один из ключевых syscall’ов. Возьмём выполнение простой команды:
python badscript.py
Содержимое скрипта не имеет значения - там просто print.

Перед выполнением мы настроили auditd двумя правилами для мониторинга вызовов execve. Обратите внимание: здесь нет фильтрации, о которой мы говорили в первой части.
-a always,exit -F arch=b64 -S execve -a always,exit -F arch=b32 -S execve
После выполнения команды в логах появляется шесть различных записей для этой активности.
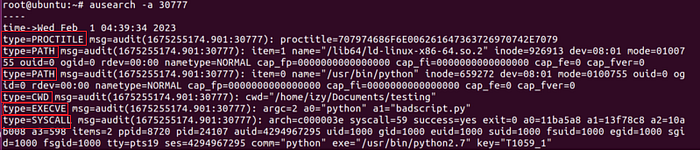
Поведение одно - запуск команды, - а вот типов записей несколько. В случае выполнения команды путь через ядро приводит к появлению записей типов: PROCTITLE, PATH, PATH, CWD, EXECVE и SYSCALL. У каждого из них свои поля - какие-то нам полезны, какие-то нет. Умение разбираться в этом сильно помогает при поиске угроз.
Давайте сузим фокус и разберём сами события.
type=PROCTITLE msg=audit(1675255174.901:30777): proctitle=707974686F6E006261647363726970742E7079
type=PROCTITLE: считается, что этот тип записи содержит полную командную строку, которая вызвала audit-событие. Однако она хранится в hex-кодировке. Если использовать утилиту ausearch, которая идёт вместе с auditd, с флагом -i (interpret), она декодирует значение за вас. Пользователи Splunk могут воспользоваться чем-то вроде:
| eval cmd = urldecode(replace(encoded_data,"([0-9A-F]{2})","%\1"))
Прежде чем углубляться дальше, важно отметить: хотя PROCTITLE и должен содержать полную командную строку, полагаться на него можно не всегда. В третьей части мы разберём ситуации, когда он подводит. Есть более надёжный тип записи, к которому мы скоро перейдём.
Первое поле, которое стоит обсудить, - это msg. У каждого события в audit.log должно быть это поле.
audit(1659896884.775:15237)
Поле msg имеет формат audit(time_stamp:ID).
time_stamp — это время в формате epoch.
А вот ID куда интереснее с точки зрения расследования. Все audit-события, которые появились в результате одного syscall’а приложения, будут иметь одинаковый audit event ID. Если то же приложение выполнит второй syscall - у него будет уже другой ID. Таким образом события группируются и можно собрать всю активность, связанную с конкретным syscall’ом.
Однако если вы используете пользовательские теги в правилах auditd (-k), я рекомендую искать события по связке ID + tag, потому что поле ID не является «абсолютно» уникальным - я видел, как со временем значения пересекались.
Чтобы разделить timestamp и ID в Splunk, можно использовать такой SPL (TA для auditd этого не делает):
| rex field=msg "audit\(\d+\.\d+:(?<id>[^\)]+)" | rex field=msg "audit\((?<epoch>[^:]+)" | eval log_time = strftime(epoch,"%Y-%m-%dT%H:%M:%S.%Q")
Имеет смысл вынести это в transform или macro для auditd-событий в вашем SIEM.
Двигаемся дальше.
type=PATH msg=audit(1675255174.901:30777): item=1 name="/lib64/ld-linux-x86-64.so.2" inode=926913 dev=08:01 mode=0100755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL cap_fp=0000000000000000 cap_fi=0000000000000000 cap_fe=0 cap_fver=0 type=PATH msg=audit(1675255174.901:30777): item=0 name="/usr/bin/python" inode=659272 dev=08:01 mode=0100755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL cap_fp=0000000000000000 cap_fi=0000000000000000 cap_fe=0 cap_fver=0
type=PATH: этот тип записи содержит путь, переданный в качестве параметра системному вызову (в нашем случае - execve).
Немного уйдём в сторону.
Вы часто будете видеть, что в PATH фигурирует ld.so (например, /lib64/ld-linux-x86-64.so.2), как в примере выше. Это зависит от бинарника, который вы запускаете. ld.so — аргумент, который нередко передаётся в execve при запуске ELF-файлов, использующих динамически подключаемые библиотеки.
Это означает, что программе во время выполнения нужно найти и подгрузить shared libraries. ld.so - это runtime-линкер. Определить, какие ELF-бинарники требуют динамической линковки, можно по их ELF program header. Если интересно углубиться в устройство ELF — вот хорошая статья: https://lwn.net/Articles/631631/
Возьмём /bin/chmod (то же самое будет и для /usr/bin/python). С помощью readelf можно проверить, будет ли ld.so загружаться во время выполнения:
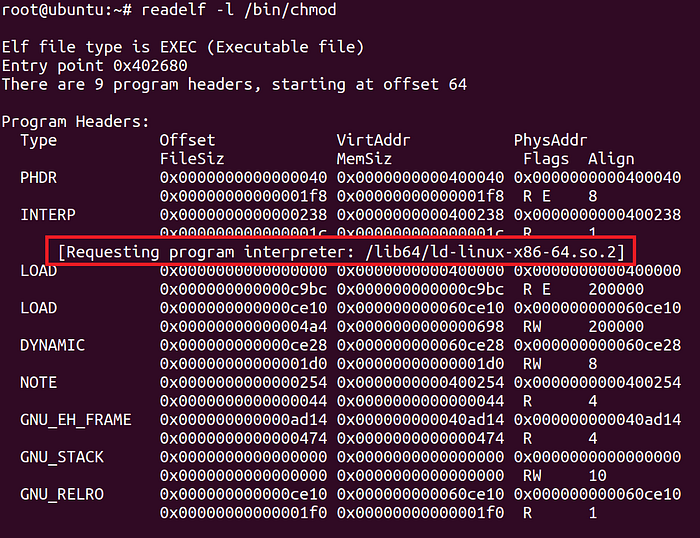
Так что видеть ld.so в execve - это нормально, в зависимости от запускаемого ELF-файла. Учитывайте, что сегодня большинство бинарников используют динамическую линковку, поэтому такое вы будете наблюдать чаще, чем нет.
Возвращаясь к PATH. Ещё одно полезное для нас поле - mode, потому что в нём содержатся права доступа к файлу. В нашем случае mode=0100755, что соответствует «file, 755».
755 (rwxr-xr-x) - это права на объект, здесь это lib64/ld-linux-x86-64.so.2 и /usr/bin/python.
Это важно: в PATH может оказаться подозрительный файл, который пытается выполниться, и его права могут многое сказать.
type=CWD msg=audit(1675255174.901:30777): cwd="/home/izy/Documents/testing"
type=CWD: этот тип записи содержит текущий рабочий каталог (Current Working Directory) процесса, который вызвал syscall (в нашем случае - execve).
Процессом, вызвавшим syscall, здесь является /usr/bin/python2.7, запущенный из указанной директории.
Стоит обратить внимание, что PATH и CWD фиксируют разные вещи - а значит, могут рассказывать разные истории. В нашем примере значения похожи, но так бывает не всегда. В третьей части посмотрим на случаи, где они расходятся.
type=EXECVE msg=audit(1675255174.901:30777): argc=2 a0="python" a1="badscript.py"
type=EXECVE - самый интересный тип записи, потому что он содержит командную строку. И именно ему стоит доверять больше, чем PROCTITLE.
Надо оговориться: есть редкие случаи, когда execve не включает всю командную строку и тогда PROCTITLE оказывается точнее. Мы разберём такие примеры в части 3. Но в большинстве ситуаций именно EXECVE можно считать надёжным источником полной командной строки.
Каждый аргумент передаётся в отдельном поле: от a0 до a*.
a0 - это бинарник, который выполняется (в нашем случае python).
Все последующие поля a1, a2 и т.д. - это параметры командной строки, переданные a0.
Если вы забираете эти логи в SIEM, есть один раздражающий момент - командную строку приходится собирать самостоятельно из всех аргументов. Splunk TA тоже этого не делает.
В Splunk можно использовать foreach, чтобы пройтись по всем полям a* в событии и собрать их в единую строку. Конкретный SPL оставлю в качестве упражнения для читателя :)
type=SYSCALL msg=audit(1675255174.901:30777): arch=c000003e syscall=59 success=yes exit=0 a0=11ba5a8 a1=13f78c8 a2=10ab008 a3=598 items=2 ppid=8720 pid=24107 auid=4294967295 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts19 ses=4294967295 comm="python" exe="/usr/bin/python2.7" key="T1059_1"
type=SYSCALL - тоже очень насыщенный тип записи, с большим количеством мета-информации, которая помогает лучше понять событие.
По сути, это событие сообщает нам, что syscall execve был успешно вызван 64-битным процессом python, указывает PID процесса и его родителя, а также то, что пользователь с uid 1000 (izy) выполнил действие в собственном пользовательском контексте. Информации много — но как именно она из этого события читается?
pid, ppid, comm, exe - довольно очевидные поля, останавливаться на них не буду.
auid - это audit user ID. Он присваивается пользователю при логине и наследуется всеми процессами, даже если меняется идентичность пользователя.
Это поле полезно, когда пользователь переключает контекст, но вам всё равно нужно понимать, кто изначально инициировал действия. Например, если пользователь вошёл в систему, а затем повысил привилегии до root (sudo su), значение auid останется прежним - до и после эскалации.
Иногда вы увидите значение 4294967295. Об этом говорили в первой части - это эквивалент unset.
success=yes: Syscall завершился успешно - процесс действительно был выполнен.
arch=c000003e: Hex-представление архитектуры x86_64 (64-бит).
syscall=59: Это ID вызванного системного вызова.59 соответствует execve. Для сопоставления ID и имени syscall удобно использовать таблицы соответствий. Также можно воспользоваться утилитой ausyscall --dump, чтобы посмотреть список syscall’ов. В Splunk можно добавить такую таблицу в lookup и делать обогащение на этапе поиска.
*id-поля: Все поля, заканчивающиеся на id, дают информацию о пользователе: в какой группе он состоит, выполнялось ли действие от имени текущего пользователя сессии или в контексте другого пользователя, был ли установлен suid-бит у исполняемого файла и т.д.
Это термины из POSIX, и я не буду подробно их разбирать, но разобраться в них стоит. Если хотите копнуть глубже - загляните в man-страницы.
В качестве удобного справочника по audit-полям могу порекомендовать вот эту таблицу:
https://access.redhat.com/articles/4409591
Поля a* внутри этой записи - это аргументы вызова самого execve (в hex), который имеет сигнатуру:
int execve(const char *pathname, char *const argv[],
char *const envp[]);
Важно отметить, что значения этих аргументов представлены в hex. Я, честно говоря, не копал достаточно глубоко, чтобы корректно и осмысленно интерпретировать их напрямую из этого события audit. Если кто-то знает простой способ декодировать аргументы командной строки, переданные в syscall, через этот лог - с радостью добавлю.
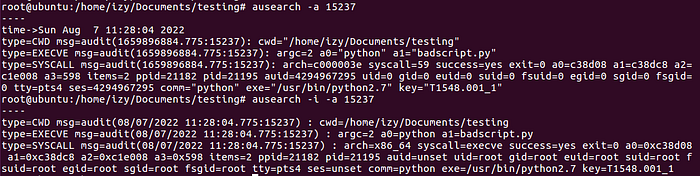
Ещё один полезный приём: если у вас есть доступ к хосту и вы хотите увидеть красиво разобранную версию audit-события, используйте ausearch -i. Эта опция делает большую часть парсинга за вас.
Обратите внимание, насколько меняется вывод с -i. Почти всё то, чего нам так не хватает в Splunk TA
Раз уж речь зашла о способах парсинга логов auditd, вот интересный инструмент визуализации от Steve Grubb:
https://github.com/stevegrubb/audit-explorer/
Side-note: Масштабирование security-агентов
Я забыл упомянуть этот момент в прошлой части, поэтому добавляю его здесь как короткое отступление. Позже перенесу это в часть 1 - туда оно подходит лучше.
В этой серии статей мой фокус - безопасность в масштабе. Поэтому даже если существуют «лучшие» способы что-то сделать, само понятие «лучше» у всех разное. Я говорю о разумной безопасности, которая масштабируется.
Мы - специалисты по безопасности, а не по эксплуатации. В идеальном мире вы бы работали вместе с центральной командой эксплуатации и совместно, аккуратно выкатывали агентов. В моём случае всё было далеко не так идеально, и в процессе деплоя я допустил несколько операционных антипаттернов, которых, надеюсь, вы сможете избежать.
Я видел, как auditd (и другие агенты) используются в очень больших масштабах (более 100 000 серверов) и при этом работают нормально. Не буду лукавить - это даётся непросто. Auditd, как и любой security-инструмент, требует внимания и постоянной настройки. Не существует одной универсальной конфигурации, которая подойдёт всем. Дополнительный момент - с auditd вы сами отвечаете за разбор и устранение проблем, нельзя «показать пальцем» на вендора и ждать фикса. С другой стороны, вы получаете полный контроль над тем, как работает технология - и лично я предпочитаю это «чёрному ящику» EDR-вендора, который что-то «чинит» за вас. У обоих подходов есть плюсы и минусы - вам решать, что лучше соответствует вашим целям и бюджету. С auditd ключевое - знать свою среду и понимать, как выжать из него максимум (надеюсь, эта серия в этом поможет).
При развёртывании auditd (или любого security-агента) почти всегда разумно использовать поэтапный rollout - по фазам или «кольцам». Если вы собрали набор правил auditd, который идеально работает в лаборатории, и выкатили его в продуктив - готовьтесь к мгновенному фейлу. Магической конфигурации, которая сработает везде, не существует, и важно заранее корректно выставить ожидания стейкхолдеров.
Разбейте инфраструктуру на тестовые «кольца», желательно объединяя хосты со схожими функциями. Степень детализации зависит от того, сколько времени и усилий вы готовы вложить, но логика одна и та же. Например: пользовательские рабочие станции - в одном кольце, базы данных - в другом, веб-серверы - в третьем и т.д. Можно пойти глубже - выделить отдельное кольцо для машин разработчиков, потому что вы знаете, что они часто запускают самые разные бинарники, в отличие от пользователей, далёких от технологий.
Логика проста: хосты схожего типа будут генерировать схожие процессы и активность. Это лучший способ тестировать ваш набор правил на разнообразных, но управляемых срезах инфраструктуры.
Приведу пример. В одной среде, где я работал, оказалось, что хотя мой набор правил auditd в целом работал хорошо, была группа систем, которые буквально захлёбывались логами. Это создавало проблемы и на уровне хостов (производительность), и на стороне SIEM (дисковое пространство). Разобравшись глубже, мы выяснили, что это набор веб-серверов, которые постоянно открывали и закрывали сетевые соединения - их нормальное поведение. В результате количество событий от мониторинга syscall connect было просто зашкаливающим.
Хорошая новость в том, что если вы нашли «проблемное» событие, его можно отфильтровать с помощью -F в .rules-файле. Учитывайте ограничения по типам полей, которые разрешено использовать с -F. И помните: правила обрабатываются сверху вниз, поэтому самые уверенные исключения размещайте в начале.
Также имейте в виду, что в /etc/audit/rules.d/*.rules может быть несколько .rules-файлов. Это можно использовать в своих интересах - например, хранить environment-specific исключения в отдельном файле для лучшей поддерживаемости. Подробнее об этом говорилось в части 1.
Заключение
Такие типы записей, как PROCTITLE, PATH, CWD, SYSCALL - вы будете видеть постоянно в audit.log, независимо от того, какое именно действие выполняется. Поэтому понимание того, что именно они означают, - это база для чтения логов auditd. И эти знания легко переносятся на другие типы поведения. Это также помогает решить, какой тип записи вам действительно полезен, а какой - нет.
С тем, что мы разобрали выше, у вас уже должно быть достаточно контекста, чтобы понимать и анализировать другие audit-события. Цель второй части была в том, чтобы взять одно конкретное поведение (запуск процесса) и показать, какую информацию auditd способен о нём дать без какой-либо фильтрации.
В части 3 мы посмотрим, как выглядят логи для симуляций, покрывающих все применимые источники данных MITRE. Я не буду разбирать каждый из них так подробно, как здесь - скорее поделюсь результатами и интересными наблюдениями там, где это уместно. Также приложу сырые и обогащённые примеры логов для каждого случая.