Linux auditd для обнаружения угроз [Часть 1]
Несколько лет назад меня попросили подготовить конфигурацию auditd, которая должна была стать основной технологией детектирования для крупной организации. Хотя я неплохо разбирался в Linux, оказалось, что материалов по использованию auditd именно для масштабного мониторинга безопасности на удивление мало.
В этой статье я планирую разобрать:
- Краткое введение в Linux Audit System
- Советы по написанию audit-правил
- Проектирование конфигурации для мониторинга безопасности
- Что именно стоит логировать с помощью auditd
- Как справляться с шумом
Эта статья ориентирована на специалистов по безопасности, IR и blue team - тех, кому нужно определить, какие логи должны попадать в SIEM, чтобы эффективно выявлять вредоносную активность. Надеюсь, со временем всё станет проще благодаря eBPF, но, если честно, мы ведь никогда не умели полностью избавляться от старых технологий, правда?
Вполне возможно, что существуют более удачные способы конфигурировать и использовать auditd, поэтому статья не претендует на исключительность.
Linux Audit System
Linux Audit System - это механизм, который позволяет логировать события, происходящие в системе Linux. Возможности аудита здесь довольно широкие: процессы, сетевые события, операции с файлами, входы и выходы пользователей и многое другое. В этой серии я сосредоточусь только на событиях, значимых с точки зрения безопасности и детектирования. Полный список типов событий, которые можно записывать, доступен в документации - он пригодится при анализе логов.
Во многих популярных дистрибутивах пакеты, необходимые для работы Linux Audit System, уже установлены по умолчанию, поэтому установку я здесь рассматривать не буду.
auditd - это демон аудита, который использует возможности Linux Audit System для записи событий на диск. Пользовательские приложения выполняют системные вызовы, которые ядро пропускает через определённые фильтры, а затем - через фильтр exclude. Эти фильтры играют ключевую роль при написании правил auditd. Мне очень нравится диаграмма от Red Hat, которая наглядно это объясняет.
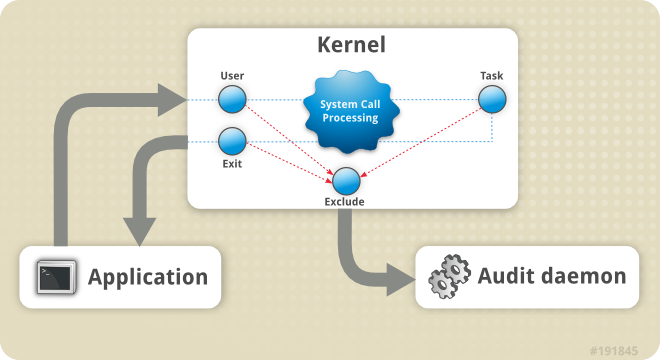
По умолчанию логи пишутся в /var/log/audit/audit.log. В этом каталоге вы можете увидеть несколько файлов audit.log - каждый из них ограничен по максимальному размеру.
В рамках audit-системы нас в первую очередь интересуют два файла:
- audit.rules - определяет, какие события должен записывать демон аудита. Именно здесь проходит большая часть работы: нужно решить, какие события для вас действительно важны.
- audit.conf - управляет тем, как работает демон аудита: путь к логам, размер буфера, параметры ротации и так далее. С этим файлом я бы не стал экспериментировать без необходимости, но к нескольким важным параметрам мы ещё вернёмся позже.
Это было лишь краткое введение. Существуют более подробные разборы подсистемы Audit. Документация Red Hat, о которой я упоминал выше, - хорошая отправная точка. Также могу порекомендовать материалы Understanding Linux Audit от Suse и The Linux Audit Documentation Project.
Написание audit-правил
Всё, что вы укажете в audit.rules, в итоге и окажется в audit.log. Когда запускается демон аудита (auditd) - а это должно происходить при старте системы - именно правила из этого файла определяют, какие события попадут в лог.
Файл audit.rules расположен по пути /etc/audit/audit.rules. Это финальный файл, к которому обращается auditd при записи событий на диск. Обращаю на это внимание потому, что в начале файла обычно написано:
## This file is automatically generated from /etc/audit/rules.d
Это не значит, что вы не можете редактировать его вручную. Но в большой инфраструктуре часто бывает так, что разные наборы правил поддерживаются разными командами и должны работать совместно. В таком случае отдельные файлы *.rules размещаются в каталоге /etc/audit/rules.d/.
Утилита augenrules собирает все *.rules-файлы (в порядке естественной сортировки) в итоговый /etc/audit/audit.rules. Важно помнить: augenrules удаляет комментарии и пустые строки перед генерацией audit.rules. Отмечаю это отдельно, потому что в прошлом мне уже приходилось выслушивать странные обвинения по этому поводу.
Теперь к написанию правил. Сосредоточимся на двух типах правил, которые нас интересуют в контексте мониторинга безопасности:
- File watches - позволяют отслеживать чтение, запись, выполнение или изменение атрибутов файлов
- Syscalls - фиксируют системные вызовы, которые приложение отправляет в ядро
Я не буду глубоко погружаться в синтаксис auditd-правил - для этого лучше открыть man audit.rules.
Полезные источники, которые стоит изучить при написании правил:
- Встроенные примеры - https://github.com/linux-audit/audit-userspace/tree/master/rules
- Набор правил на основе MITRE - https://github.com/bfuzzy/auditd-attack/tree/master
- Best practice ruleset от Florian Roth - https://github.com/Neo23x0/auditd
- https://slack.engineering/syscall-auditing-at-scale/
Несколько моментов, о которых стоит помнить при построении правил:
- Используйте теги. В audit-правилах есть возможность добавлять теги (
-k), и это сильно упрощает последующий анализ событий. Можно использовать свои собственные теги или, например, маркировать правила MITRE ID (см. ссылку bfuzzy выше). - При аудите syscalls чаще лучше логировать на выходе, а не на входе (
-a always,exit). На момент входа в функцию важные параметры могут быть ещё не определены - соответственно, вы их просто не увидите. - Старайтесь объединять правила для syscalls, когда это возможно
Например:
-a always,exit -S rmdir -S unlink -S rename
Каждое правило syscalls проверяется для каждого системного вызова, который делает любая программа. В сумме это даёт нагрузку и влияет на производительность.
- При написании правил вы можете встретить фильтр
-F auid!=4294967295. Это число - эквивалент0xFFFFFFFF, то есть максимальное значение unsigned int. По сути, оно соответствует-1, а в мире auditd это означает “unset” - значение не задано. Такое часто встречается у процессов, которые стартовали до запуска auditd. Вman audit.rulesэто описано так:
“Audit system рассматривает UID как беззнаковые числа. Значение -1 используется для обозначения того, что loginuid не установлен. При выводе это выглядит как 4294967295. В правилах можно использовать ‘unset’, или -1, или 4294967295 - это одно и то же.”
- Про исключения. Убедитесь, что ваши исключения (
-a never,exclude) достаточно специфичны и расположены в начале - так они будут отрабатывать первыми. Существует дискуссия о том, что должно идти выше: специфичные include или exclude. С точки зрения производительности лучше сначала размещать точные include, но в больших инфраструктурах это часто нереалистично.
На практике именно такие syscalls, как execve, дают максимум полезной информации для детектирования. Если поставить их в самом верху, возможности для последующей оптимизации производительности почти не останется.
Конфигурация демона аудита
Настройки auditd можно задавать в двух местах:
- напрямую в начале файла
audit.rules- в виде control-правил - в файле
audit.conf
Набор параметров, доступных в этих двух местах, различается. Если нет веской причины, я бы не стал активно крутить конфигурацию auditd - за исключением нескольких действительно важных параметров.
Backlog size
Задаётся через ключ -b, после которого указывается количество audit-сообщений в буфере.
Параметр backlog ограничивает число сообщений, которые могут находиться в очереди в ожидании записи в лог. Обычно имеет смысл начать со значения по умолчанию и постепенно увеличивать его при необходимости. В production-среде я встречал рабочее значение 8192.
Если лимит превышен, в логах появится сообщение “backlog limit exceeded” - это хороший индикатор того, что буфер стоит увеличить.
При этом не забывайте: чем больше буфер, тем больше потребление памяти.
Failure flag
Задаётся через -f и определяет, что должен делать auditd, если буфер переполнен.
В production-системах вам точно не нужна остановка или сбой сервиса, поэтому я рекомендую устанавливать значение 1 - в этом случае событие просто будет записано в лог без каких-либо дополнительных действий.
Enabled flag
Задаётся через -e и позволяет сделать конфигурацию audit неизменяемой.
Если установить значение 2, любые попытки изменить конфигурацию будут отклонены и залогированы. Изменить настройки можно будет только после перезагрузки системы.
Важно: это правило должно быть последним в вашем наборе правил.
Это, по сути, всё из конфигурации, что я обычно рекомендую менять. В audit.conf можно заглянуть, но, как правило, я стараюсь не трогать его без необходимости.
Если в вашей среде важно, например, определить поведение демона при переполнении лог-файла, тогда audit.conf действительно стоит изучить. В большинстве случаев значения по умолчанию меня вполне устраивали.
Что логировать?
Подсистема Linux Audit позволяет писать в лог практически всё. Вопрос в другом - что из этого действительно имеет смысл записывать, а что нет?
Для начала посмотрим на самые релевантные источники данных с точки зрения MITRE.
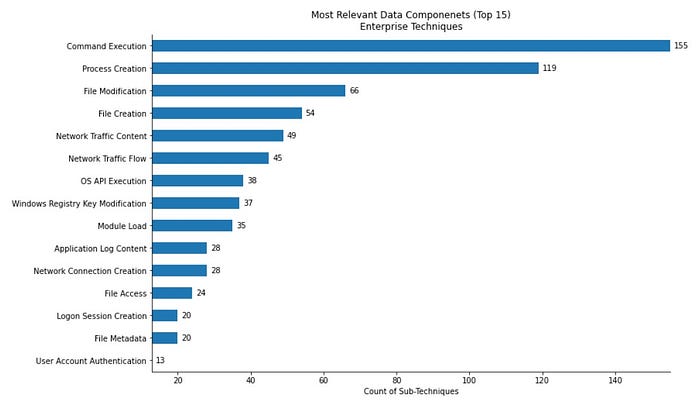
График выше основан на фреймворке MITRE ATT&CK Enterprise и сопоставляет под-техники с источниками данных. Как видно, большая часть техник детектируется через события выполнения команд и создания процессов. Причина проста - именно там обычно содержится командная строка.
Возвращаясь к auditd: большую часть этих источников данных можно мониторить с его помощью (разумеется, не бесплатно с точки зрения ресурсов). Ниже - моя попытка сопоставить список источников данных с типами записей auditd, которые дают нам эту информацию.

Поскольку Medium ужасно обращается с форматированием, список приведён в виде картинки. Ту же версию я выложил здесь:
https://github.com/izysec/linux-audit/blob/main/DS-to-audit.MD
Этот список нужен скорее для приоритизации правил. Auditd по своей природе шумный инструмент, и хотя точное влияние зависит от среды, если ориентироваться на порядок величин - при security-ориентированной конфигурации auditd на production-системах я бы закладывал увеличение загрузки CPU примерно на 10–15%.
Можно долго обсуждать, что считать “production” и откуда именно берётся этот процент, но это лишь ориентир, чтобы задать правильные ожидания. Auditd - тяжёлый инструмент. И в зависимости от характера хоста эта «тяжесть» проявляется по-разному.
Один пример. Был production-сервер с базой данных для крупного публичного веб-приложения. Его задача - хранить данные. Это означало миллионы операций записи в день. Auditd активно потреблял CPU, особенно из-за правил, отслеживающих файловые syscalls (например, open). Поскольку база по своей природе постоянно работает с файлами, audit.log заполнялся записями минимальной ценности, а auditd проверял и логировал практически каждую файловую операцию (то есть почти непрерывно). Хорошо, что размер audit.log ограничен - иначе мы бы получили ещё и проблему с дисковым пространством.
В итоге мы добавили исключения для каталогов, в которые постоянно шла запись, и разместили это правило выше проблемного - чтобы оно срабатывало первым. Похожие эффекты мы наблюдали и на серверах другого профиля - например, при активном мониторинге сетевых syscalls (connect).
Я не могу точно сказать, как auditd повлияет на вашу production-среду. Но могу поделиться своим опытом - возможно, это заставит вас заранее подумать о поведении в вашей инфраструктуре.
Основные факторы влияния на производительность - это загрузка CPU и потребление памяти. При этом реальный эффект часто становится понятен только после внедрения.
Мой совет:
- Работайте вместе с командой эксплуатации.
- Заранее проговорите возможные побочные эффекты.
- Используйте их знание среды, чтобы получить максимально реалистичную оценку поведения в production.
- Ограничьте допустимый размер логов auditd.
- Рассмотрите возможность ограничения ресурсов auditd (например, через
nice,cpulimit,cgroups). - Разворачивайте конфигурацию поэтапно.
- И самое главное - анализируйте результаты и адаптируйте правила.
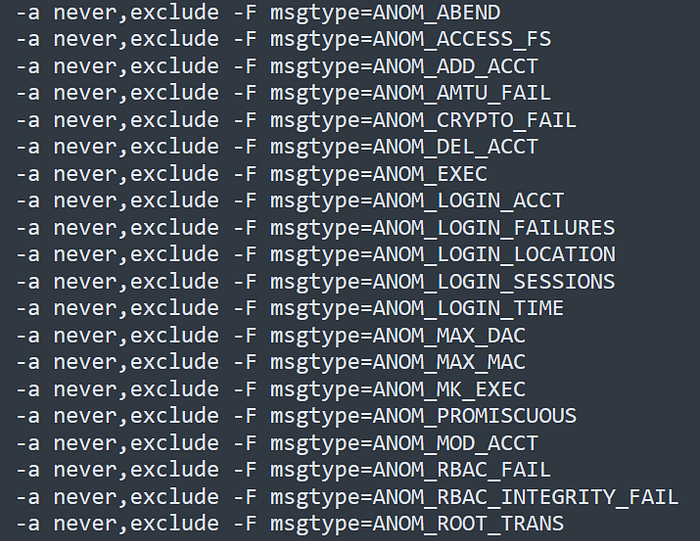
Поскольку у auditd огромное количество типов записей, мониторить их все подряд - идея так себе. Даже если вы аккуратно пишете правила, исключение отдельных типов сообщений может существенно снизить шум. Ниже - список типов сообщений, которые, на мой взгляд, действительно имеют ценность с точки зрения безопасности.
При написании audit.rules имеет смысл явно указывать, какие типы записей логировать не нужно. На практике это оказалось хорошим способом уменьшить шум от auditd. Делается это примерно так:
-a never,exclude -F msgtype=ANOM_ACCESS_FS
Каждая строка в файле правил обрабатывается последовательно. И хотя объединение правил обычно полезно для производительности, в случае таких исключений это, к сожалению, не работает. Для каждого msgtype, который вы хотите исключить, придётся писать отдельную строку.
Что касается syscalls: движок auditd перехватывает каждый системный вызов, который делает программа, и пытается сопоставить его с правилами. Когда правила передаются в ядро, поля syscalls помещаются в маску, так что для проверки совпадения достаточно одного сравнения. В этом случае объединение нескольких syscalls в одном правиле действительно эффективно.
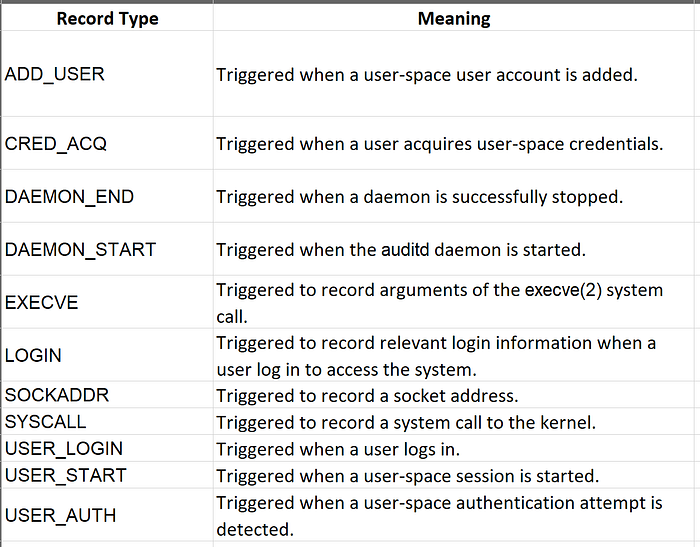
Полный список типов записей можно найти в документации. Основные и вспомогательные типы также перечислены прямо в исходном коде.
Одно событие в Linux может породить сразу несколько записей auditd. Есть основное событие, а за ним - вспомогательные записи разных типов. Эти вспомогательные записи содержат дополнительную информацию. Их количество зависит от того, какой путь системный вызов проходит через ядро и в каких местах auditd в него «встраивается».
Насколько мне известно, готовой таблицы соответствия между syscall и генерируемыми типами записей не существует, поэтому я начал составлять её самостоятельно.
Пример вспомогательной записи - тип CWD, который вы часто увидите в audit.log. Он показывает текущий рабочий каталог, в котором произошло основное событие. В списке выше его нет. Почему? Потому что, хотя в некоторых случаях эта информация полезна, для задач детектирования она редко критична. По другим данным зачастую можно сделать вполне обоснованные выводы.
Здесь всё упирается в баланс между безопасностью и реализуемостью. Получить абсолютно всё - не вариант.
Заключение
Я считаю, что auditd вполне можно использовать для обнаружения угроз на Linux-эндпоинтах - даже в крупных инфраструктурах. Но если просто взять готовый набор правил из интернета и закинуть его в прод, проблемы гарантированы. Нужно чётко понимать, что именно вы хотите мониторить, и активно убирать шум описанными выше способами — только так можно прийти к конфигурации, пригодной для сложной и масштабной среды.
Мой подход выглядел бы так:
сначала - syscalls, которые вам действительно важны (execve, connect) и которые стоят в самом верху;
затем - файлы и каталоги, представляющие интерес;
и уже после - более простые правила для мониторинга конкретных бинарников вроде nmap, tshark и т.п., если это для вас актуально.
При мониторинге файлов не забудьте и про конфигурацию самого auditd. Не хотелось бы, чтобы атакующий спокойно отключил или изменил логирование и ушёл незамеченным.
Планирую в перспективе написать ещё один пост - о том, как удобнее анализировать audit-логи, а также показать примеры логов для разных типов активности, чтобы было понятно, как это выглядит на практике. Когда доберусь - не знаю, всё зависит от того, насколько полезной окажется эта статья.
Спасибо, что дочитали до конца.