Краткая инструкция по по FAT
SpaceCatСейчас будет рассказано, как быстро и просто,без хуйни, вытащить файл из системы FAT и посчитать MD5SUM.
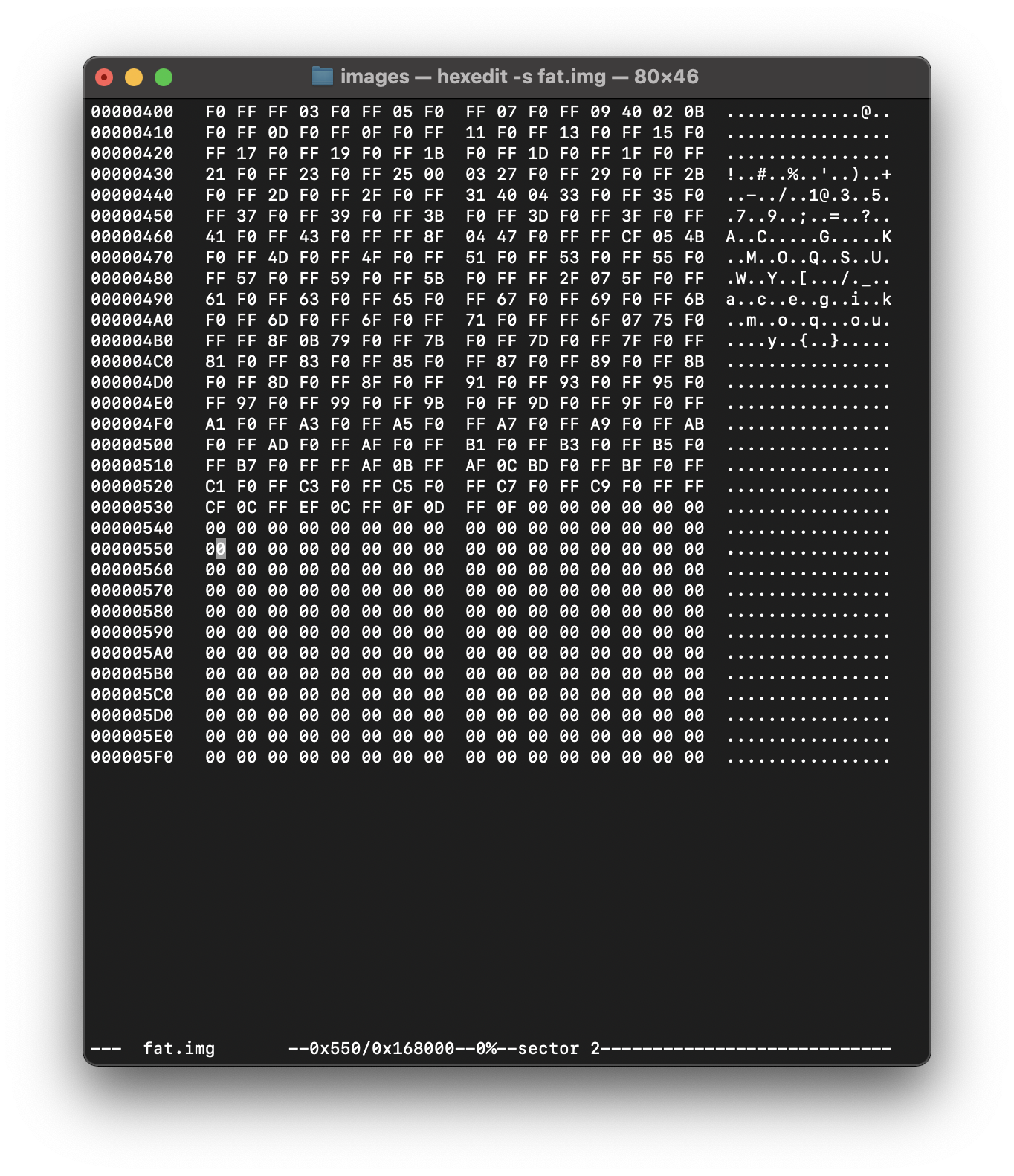
hexedit -s fat.img

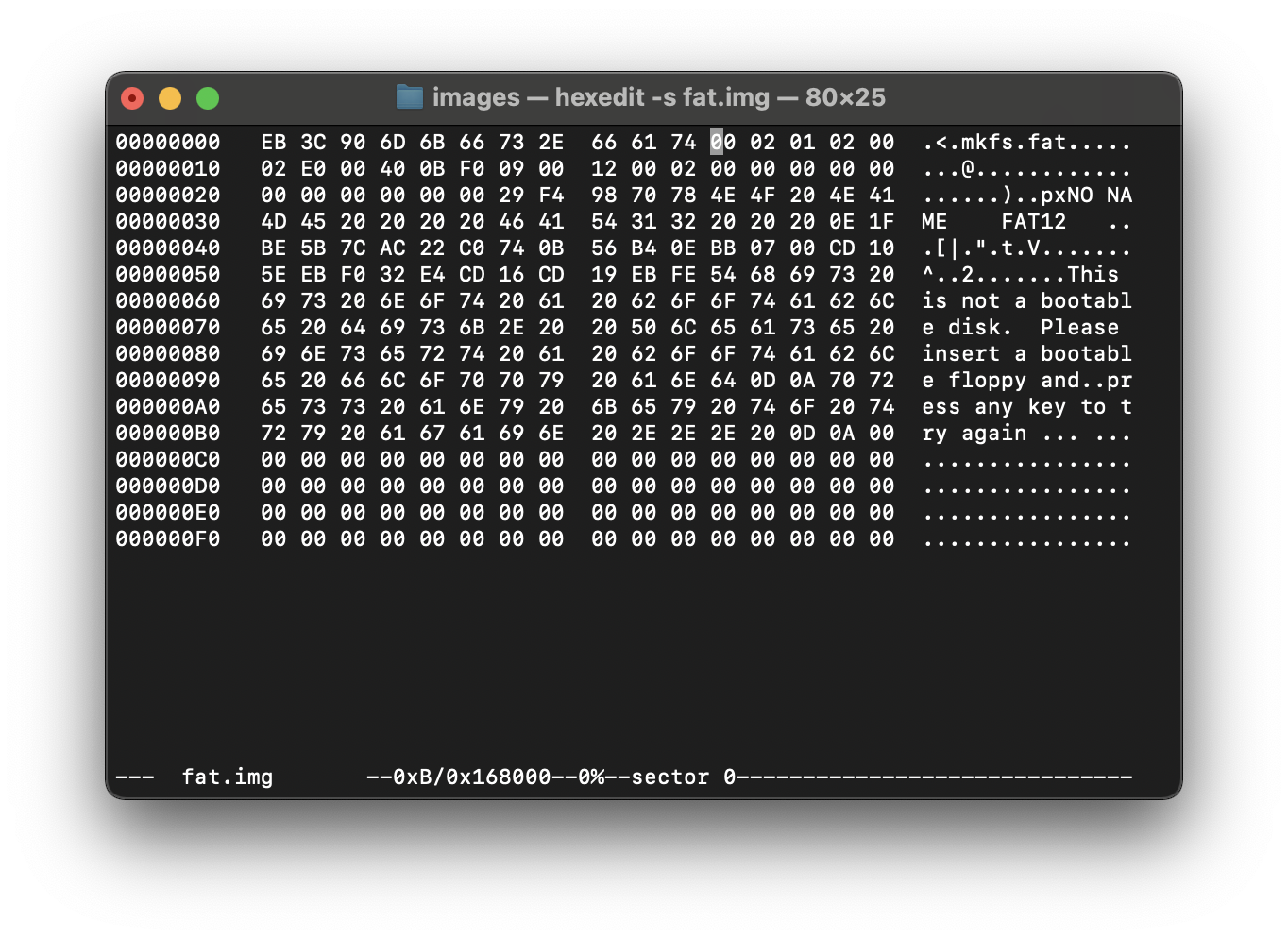
Первое что смотрим в открывшейся у нас херне - размер сектора.
Его мы ищем по значению Bh и Ch внизу экрана

Далее - важно!
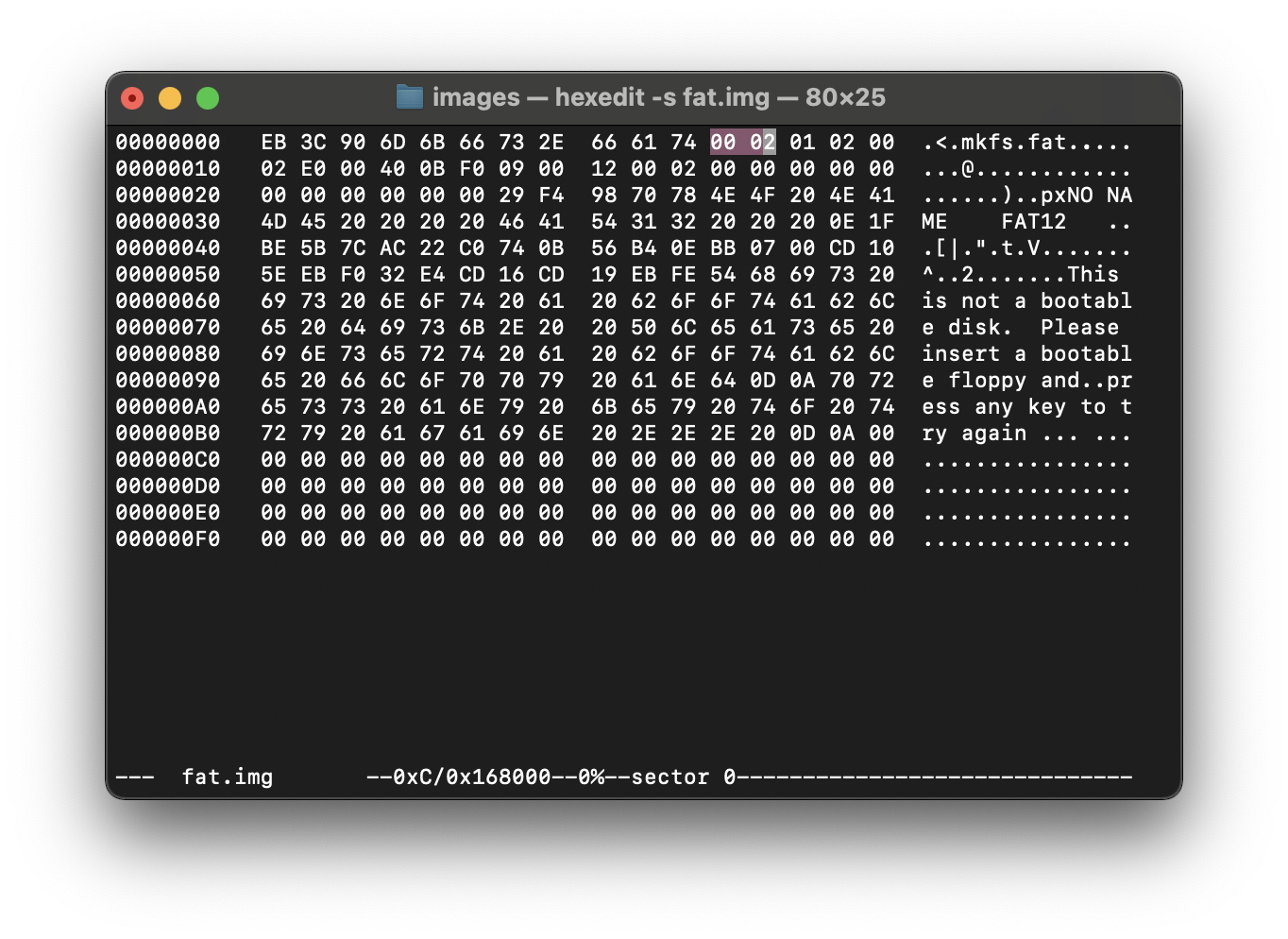
Допустим, будем называть вычисления далее перехуевертом определим действие “перехуеверчивание” по правилу: был у нас 00 02 - стал 02 00, что равняется 200(меняем местами)
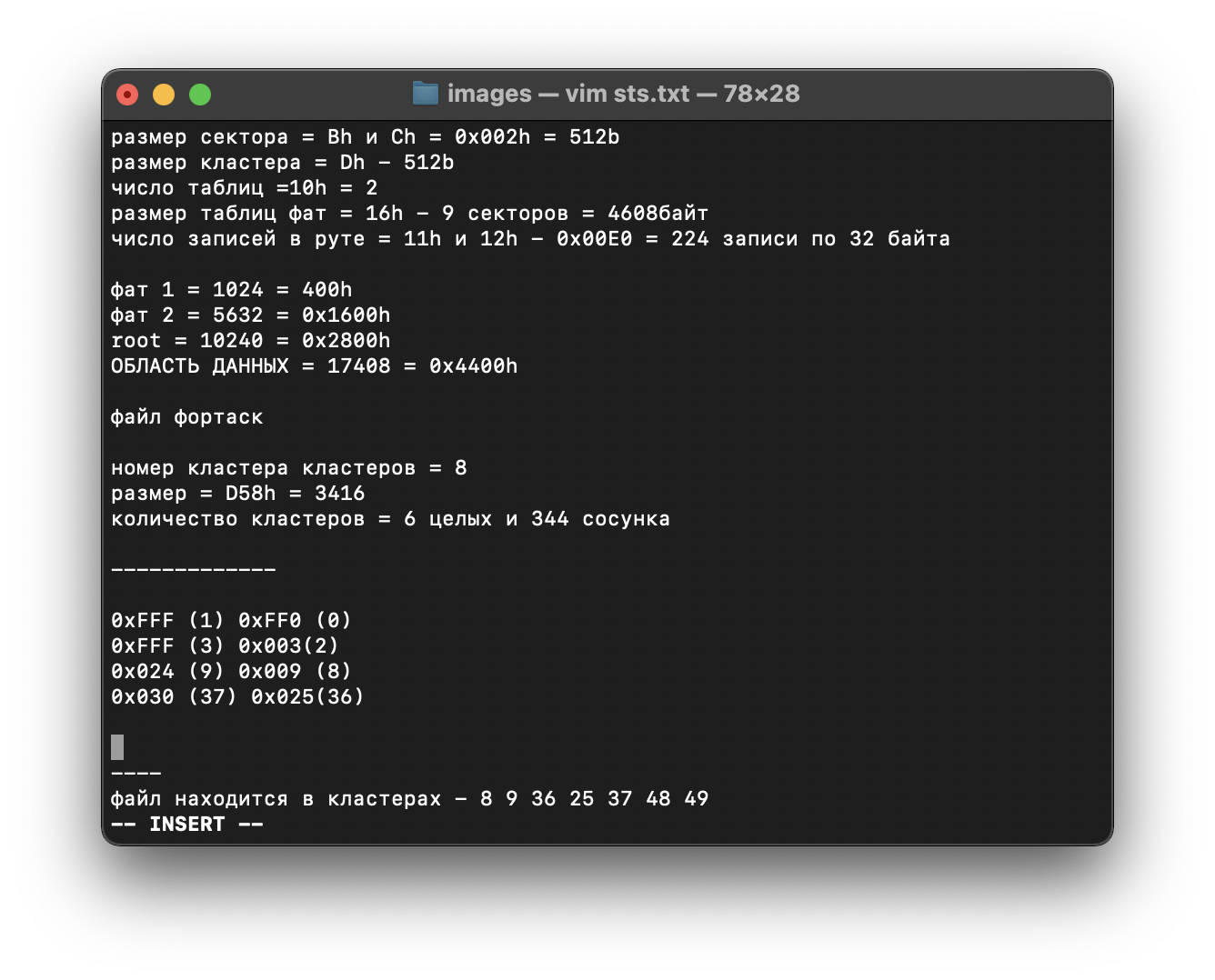
размер сектора будет равен 0x200h = 512b - из шестнадцатерички переводим.
P.S. Почти везде он 512b.
Далее смотрим размер кластера - Dh.

далее считаем число таблиц - 10h
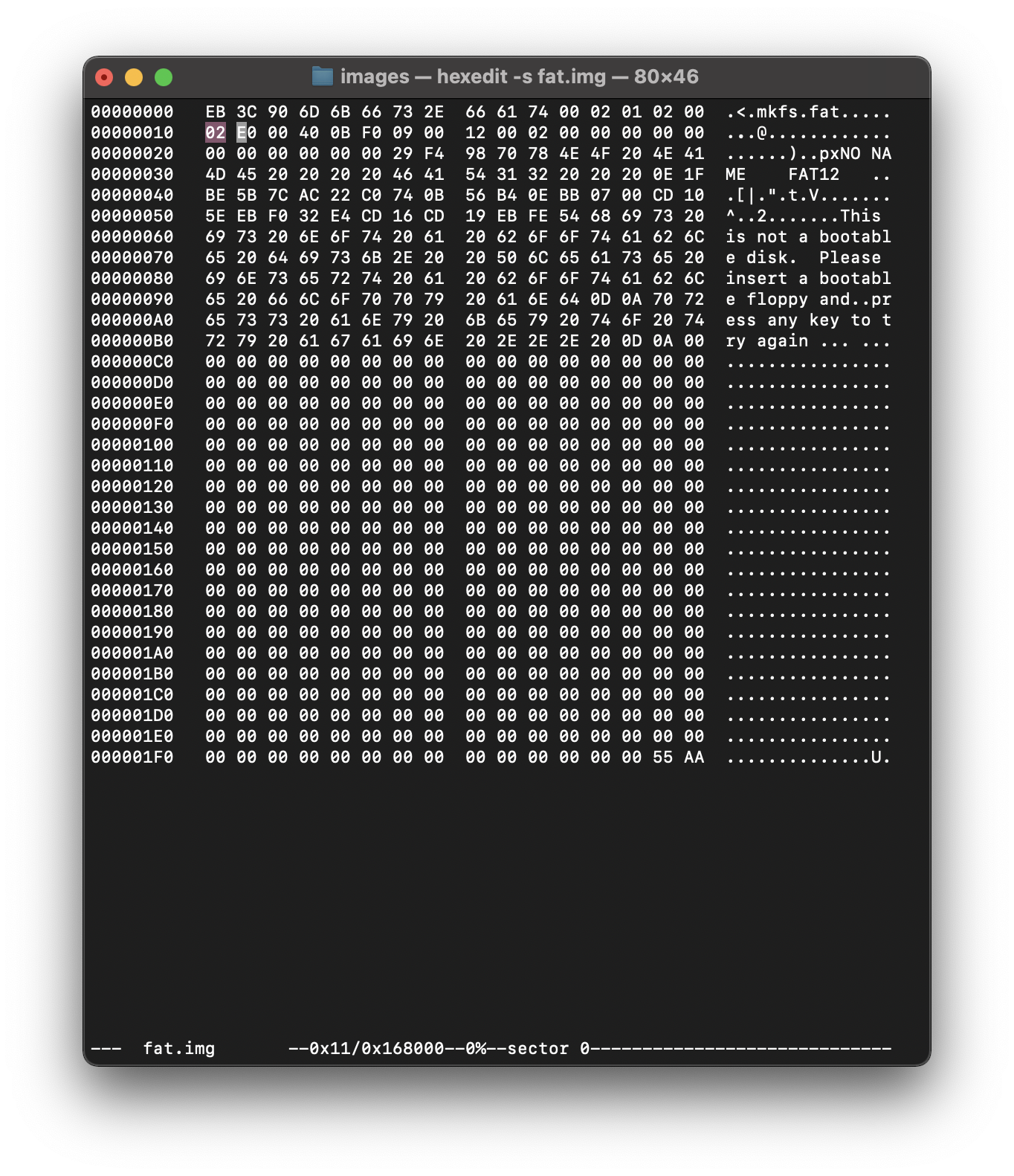
далее считаем размер этих хаев таблиц. - 16h
у нас пизда. 9 секторов.

что будет равно 9 СЕКТОРОВ = 9*размер сектора = 4608 байт.
проще выкинуть комп в окно.
считаем число записей в руте. 11h и 12h
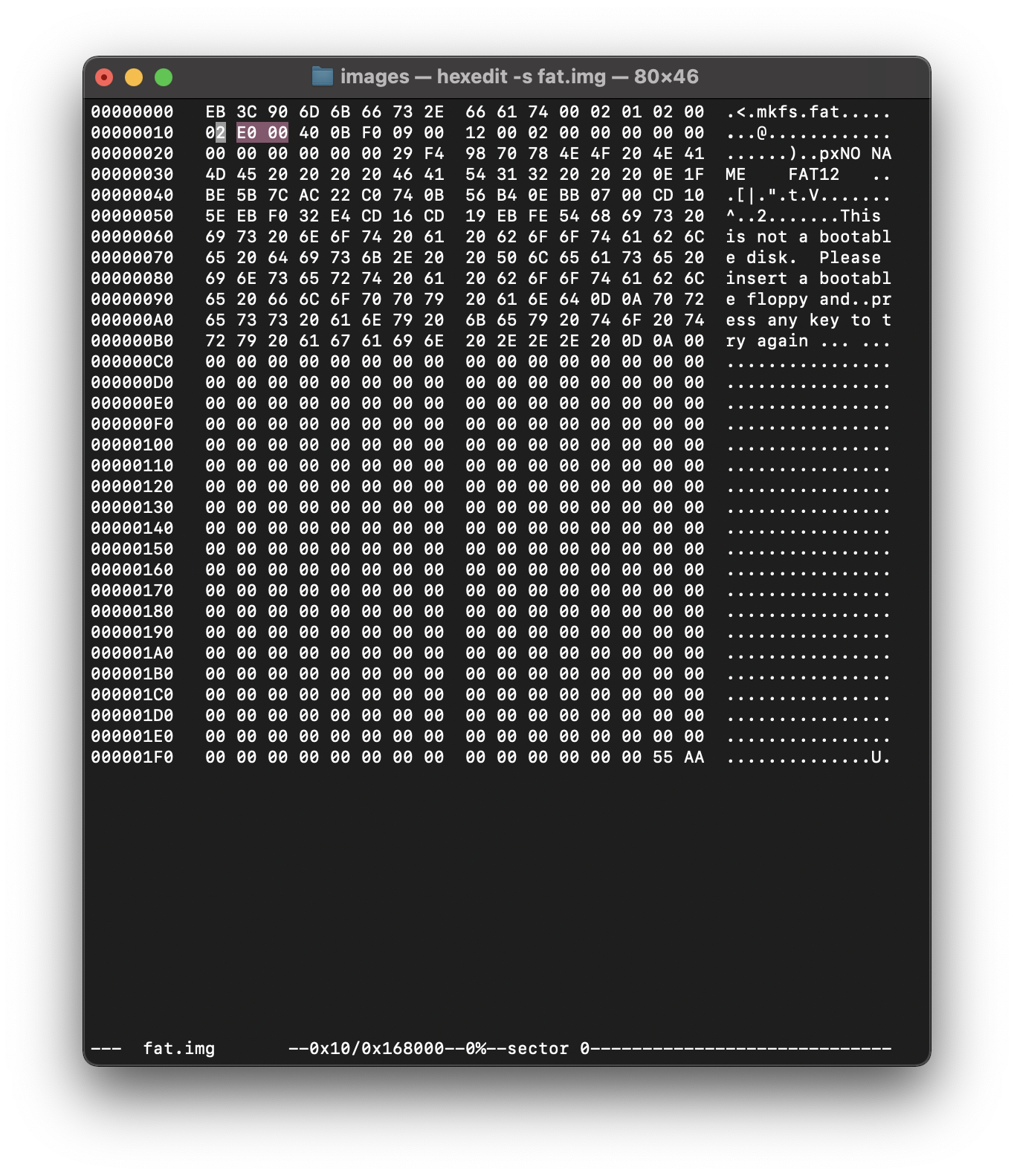
для подсчета используем перехуеверчивание и получаем 0x00Е0= 224 записи по 32 байта (похуй, не знаю как - это не важно)
всего у нас две таблицы. Смещение до первой - стандартно - 512 = 200h(в нашем случае не стандартно - 400h - адски тыкаем PageDown
далее считаем смещения. для этого
берем смещение до первой таблицы фат -
фат 1 - 400h - 1024байта
Фат 2 - Фат 1 + размер таблицы Фат = 1024+4608 = 5632 = 0x1600h - наше смещение
далее смещение до рута считаем
фат 2 + размер таблицы фат = 5632 + 4608 = 10240 = 0x2800h
теперь считаем самое важное - область данных
(это была прелюдия, теперь сам БДСМ)
нам нужен файл фортаск.
Прыгаем на рут четез ctrl+G и ищем там его

ищем номер кластера (мне похуй, мне лень объяснять - просто ищем
(байт А вторая строка в файле FORTASK)

размер - последние четыре байта файла записи в руте

используя привычное действие перехуеверчивание получаем 00 00 0D 58 или 3416 байт
считаем количество кластеров - файл ж не в одном (очевидно - нихуя, но так надо. похуй)
для этого делим размер файла на размер кластера = 3416/512 = 6 целых кластеров и один СОСУНОК - 344 байта в недоноске (лол, растишку не жрал)
прыгаем на таблицу фат 1
БЕРЕМ ПО ТРИ БАЙТА. (ПО КЛАСТЕРУ)

угадаете дальнейшее действие?)))
у нас F0 FF FF - будет FFFFF0 - разбиваем по ТРИ - 0xFFF и 0xFF0
записываем.
(ВНИМАТЕЛЬНО СМОТРИ СУЧКА И ПОЙМЕШЬ)
0xFFF - 1 кластер, а 0xFF0 - 0 кластер
АNALогично (fisting)
03 F0 FF - FFF003 - 0xFFF (3) 0x003 (2)
считаем так до 8ого кластера (потому что 8ой кластер у нас высчитан выше - это НАЧАЛО)
09 40 02 - 0x024 (9) 0x009 (8)
cмотрим на зхначение 8ого кластера - он указывает нам на 9ый
9ый кластер нам известен - он указывает на 36ой кластер
листам до 36
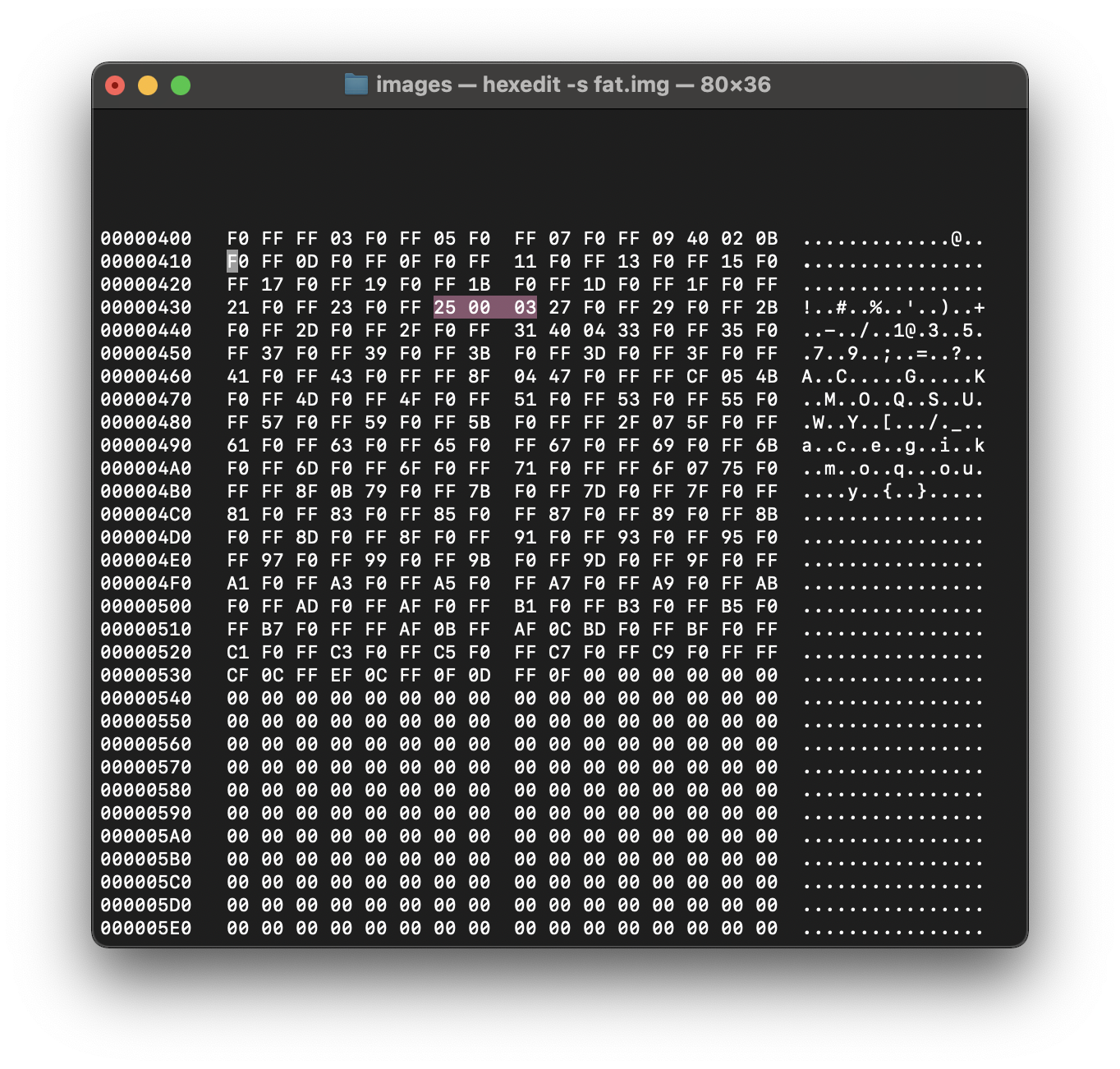
25 00 03 = 0x030h (37) 0x025 (36)
он указывает на 37 кластер
(нам нужно найти 7 кластеров таким макаром)
летим на 48 кластер
31 40 04 = 0x044 (49) 0x031 (48)
48 кластер указывает на 49 кластер - у нас все 7 элементов
записываем все. (ниже прикладываю ВСЕ ВЫЧИСЛЕНИЯ и переходим к подсчету MD5/вытаскиванию
((ЕБАЛ Я НАХУЙ ШРИМРАОЫТ ПИСАТЬ ЭТО ТРЕЗЫЫЫЫЫЫМ_)
что делаем
dd if=fat.img of=1.bin bs=1 skip=$((17408+(8-2)*512)) count=$((512))
что это обозначает:
dd - команда if - название образа оf - для каждой итерации (пока не кончатся кластера новый файл) bs - байт сектор (ПОХУЮ ВАЩЕ ВСЕГДА 1) skip - смещение до данных + номер кластера в котором лежит файл минус 2(ВСЕГДА) count - размер кластера
повторяем для каждого кластера (скрин приведу итоговый)

далее сшиваем файлы в один
cat 1.bin 2.bin 3.bin 4.bin 5.bin > pizda.bin

считаем md5sum
md5sum <имя файла>
в нашем случае
md5sum pizda.bin
я буржуй ебаный - скрин с мака - команда чуть другая. суть та же

PROFIT
идем курить пить и употребляясь, ибо это такое очко....
НЕ ЗАБЫВАЕМ ПЕРЕВОРАЧИВАТЬ БАЙТЫ И ПЕРЕВОДИТЬ ЧИСЕЛКИ ИЗ ХЕКСОВ В ДЕСЯТИЧКУ
Загрузочный сектор:
размер сектора = байты 0Bh и 0Ch = 200h = 512 byte
размер кластера (В СЕКТОРАХ БЛЯДЬ) = байт 0Dh = 4 cектора = 512*4 = 2048 байтов
число зарезервированных секторов (В ШТУКАХ) = байты 0Eh и 0Fh = 4 штуки
размер таблицы FAT (В СЕКТОРАХ БЛЯДЬ) = байт 16h = 3 сектора = 1536 байтов
число таблиц FAT (В ШТУКАХ) = байт 10h = 2 штуки
число элементов в руте = байты 11h и 12h = E0h = 224 записей по 32 байта каждая
смещения:
ТАБ1 = размер сектора умножаем на количество рез. секторов = 512*4 = 2048 = 800h
ТАБ2 = предыдущее значение смещения + размер таблицы = 2048 + 1536 = 3584 = E00h
рут = предыдущее значение смещения + размер таблицы = 3584 + 1536 = 5120 = 1400h
область данных = предыдущее значение смещения + число записей умножить на 32 байта =
= 5120 + 224*32 = 12288 = 3000h
ПРЫГАЕМ В РУТ И ИЩЕМ ФАЙЛ ФОРТАСК
файл фортаск:
номер первого кластера = байт Аh второй строки записи = 1Eh = 30
размер файла фортаска = четыре последние байта второй строки = 3558h = 13656 байт
сколько кластеров занимает файл = размер файла / на размер кластера =
= 6 полноценных полностью забитых кластеров + один огрызок на 1368 байтов
итого семь кластеров
смещение в области данных до начала файла =
= смещение до области данных + (номер первого клaстера - 2)*
*размер кластера = 12288 + (30-2)*2048 = 69632 = 11000h
ЛЕТИМ В ФАТ
Цепочка кластеров: 30 > 31 > 36 > 37 > 68 > 69 > 74
1F 40 02 > 02 40 1F > 02401F > 024h (31 кластер) 01Fh (30 кластер)
25 40 04 > 04 40 25 > 044025 > 044h (37 кластер) 025h (36 кластер)
45 A0 04 > 04 A0 45 > 04A045 > 04Ah (69 калстер) 045h (68 кластер)
НАЧИНАЕМ БРАТЬ ИЗ ФАЙЛОВОЙ СИСТЕМЫ
dd if=имя_образа of=имя_назначения_с_расширением_.bin bs=1 skip=$((смещение до области данных + (номер кластера в цепочке -2)*размер кластера)) count=$((размер кластеров в цепочке))
ПОЛУЧИЛИ НЕСКОЛЬКО ОТДЕЛЬНЫХ ФАЙЛОВ И ТЕПЕРЬ СШИВАЕМ ИХ
cat 1.bin 2.bin 3.bin 4.bin 5.bin 6.bin 7.bin > gotovo.bin
ВЫСЧИТВАЕМ МД5
md5sum gotovo.bin