Компиляция и бенчмарки AsmX для хейтеров
Илон МаскУ AsmX есть три варианта компиляции: EXE, APP, ARM. Разберём их работоспособность и производительность на последней версии языка от 18.08.23 13.00.
Часть 1. EXE
Самый недоделанный вариант компиляции, несмотря на разработку с 16 июня 2023 года, до сих пор полностью неработоспособна.
Часть 2. ARM
Компиляция под ARM в AsmX создаёт .s файл с ассемблерным кодом под ARM. Скомпилируем программу, состоящую из одной инструкции @add 1, 1.
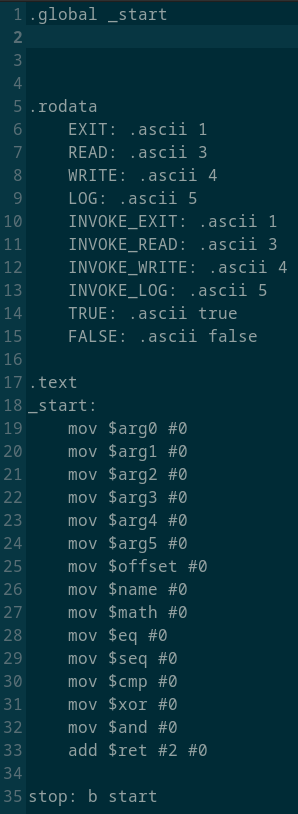
Мало того, что этот способ компиляции работает в отрыве от характеристик конкретного ARM ядра, которые очень разнообразны(от дешёвых микроконтроллеров STM32F103 до мобильных процессоров серии Qualcomm Snapdragon). Микроконтроллерных действий, как например, настройки частоты ядра и переферии или назначения режима работы и подтяжек по напряжению пинам чипа не выполнено. Имена регистров не подходят ни одному существующему процессору. Есть очень условная оптимизация в сложении аргументов во время компиляции, но зачем тогда здесь исползована команда add с одним нулевым аргументом?
Так же крайне ограничен набор компилируемых инструкций:
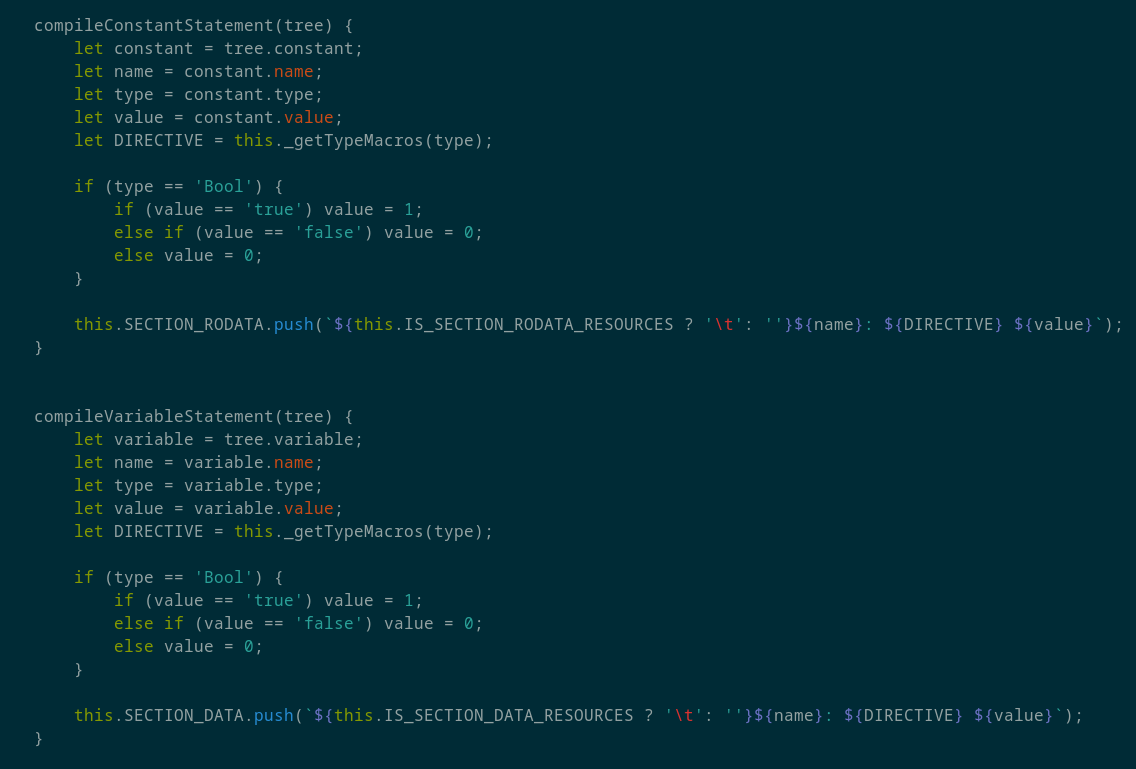
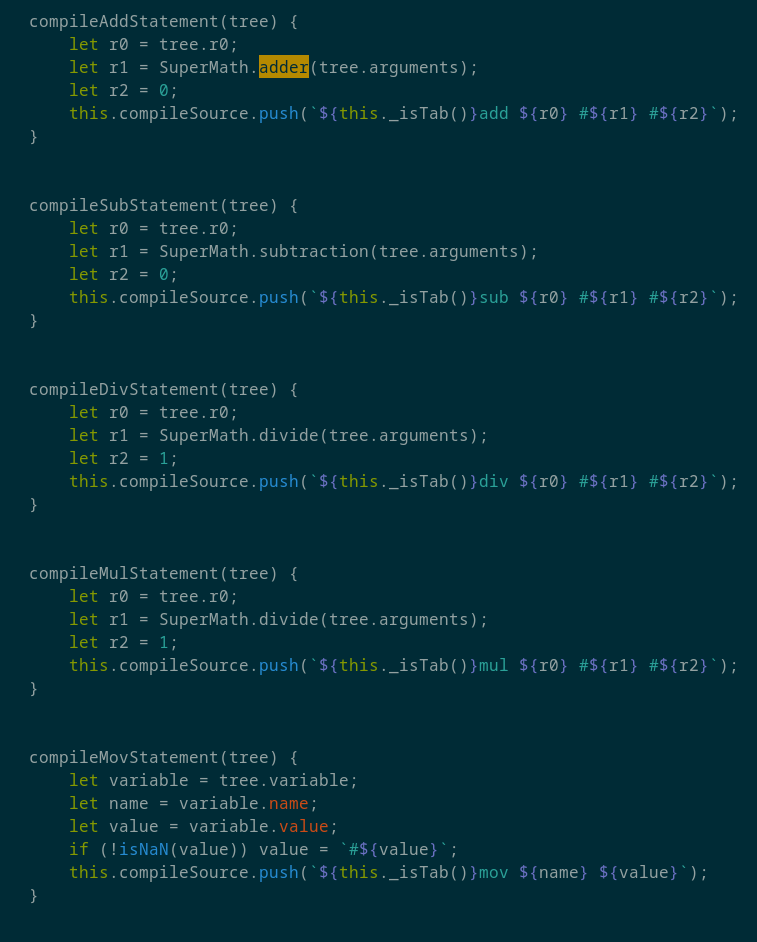
Таким образом скомпилировать даже Hello, world! на AsmX под ARM невозможно.
Часть 3. APP
Уникальный авторский бинарник и единственный рабочий способ компиляции и последующего выполнения AsmX на данный момент.
Этот формат также страдает от проблемы малого количества поддерживаемых инструкций. Их до сих пор всего четыре:
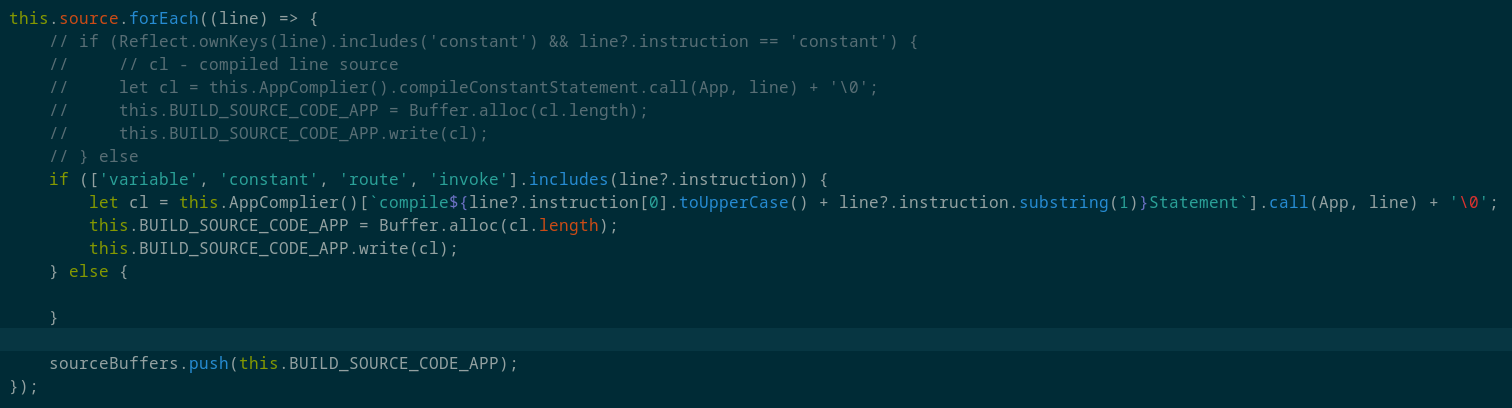
Для проверки компиляции этих инструкций скомпилируем простой вывод переменной в APP.


Что мы тут видим? Странный заголовок, напоминающий заголовок ARM компилята из прошлой части:
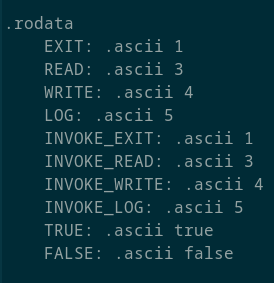
Затем имя переменной обычным текстом, её значение, тоже, конечно, текстом и вызов прерываний просто указанием номера инструкции invoke, их номера и аргумента. Прошу заметить десятичность номеров прерываний и их текстовость.
Примечание: Обычно @invoke 16 не компилируется, я удалил из компилятора ошибку, связанную с номером прерывания. для доказательсятва десятичности номеров.
Теперь поговорим о возможностях этих четырёх инструкций. @set - создание переменной, @define - создание константы, @route - push в стэк, @invoke - вызов авторских прерываний, в основном, предназначенных для ввода/вывода. То есть нет возможности компилировать даже арифметические операции.
Так же присутствует занимательная ошибка: для трансляйии в APP формат код интерпретируется, при интерпретации условные переходы просто возвращает интерпретатор на несколько строк назад, при любой неопознанной операции в файл добавляется всякий мусор проде заголовка файла. Из-за этой ошибки компиляция цикла приводит к разрастанию .app файла до невероятных размеров:
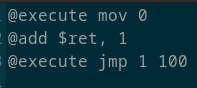


Трансляция кода размером в 50 байт создаёт файл размером 675 килобайт.
Теперь к деталям исполнения этого формата файлов. При исполнении команды node kernel.js asmx-cli tun app ./file.app код будет ТРАНСЛИРОВАН ОБРАТНО в AsmX и затем интерпретирован! Смысл такого формата мне не ясен. Шифровки нет, можно обратно перевести его в исходник командой консоли, ускорения интерпретации тут тоже нет из-за обратной трансляции и затем уже обычной интерпретации, список команд ограничен. Обычный исходный код будет выиграшнее по всем параметрам.
Часть 4. Производительность
Так как способы компиляции не поддерживают арифметические операции или не собираются в бинарные файлы, будем проверять скорость исполненияна интерпретаторе.
Методология.
Для измерения времени интерпретации AsmX будет использована встроенная библиотека времени Javascript, измерим время выполнения kernel.js. При таком измерении мы встретимся с проблемой - интерпретация происходит асинхронно.
Придётся немного изменить исходный код kernel.js. Изменение 1 - поднимем класс CompilerAsmX в самый верх файла, прямо после импортов. Изменение 2 - заменим этот код:
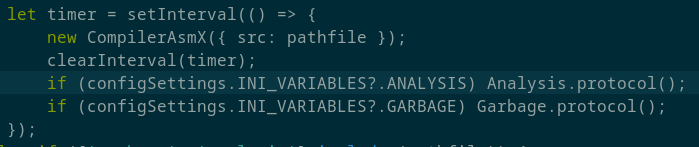
На:

Для бенчмарков на Javascript используется та же библиотека, для бенчмарков C++ будем использовать встроенную библиотеку времени std::chrono.
Бенчмарк 1. Сложение:
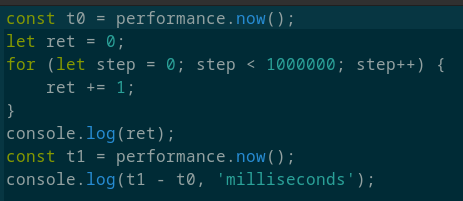
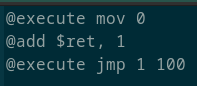
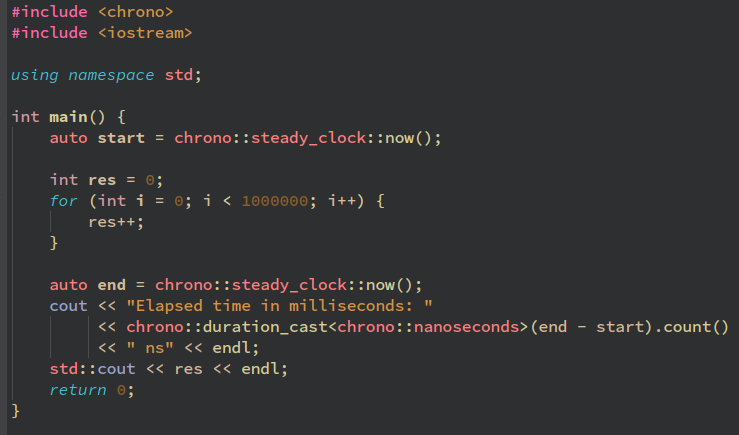
Результаты:

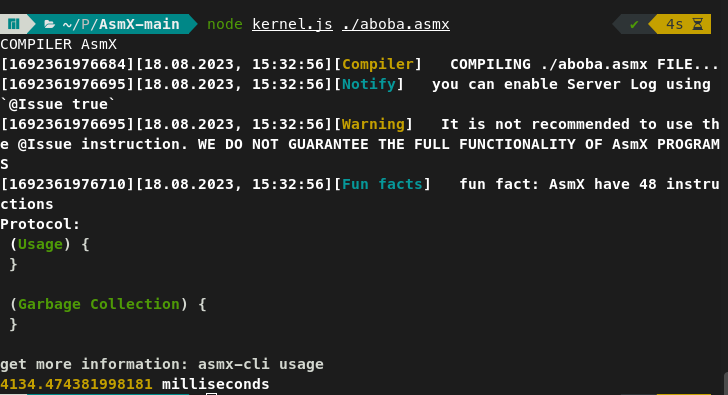

Asmx в 5905714 раз(4134/7 * 1000000/100, 5.9 миллионов раз) медленнее Javascript и в 898695652173(4134/0.000046 * 1000000/100, 8.9 миллиардов раз) медленнее ВЫСОКОУРОВНЕВОГО языка C++.
Бенчмарк 2. Десять сложений:
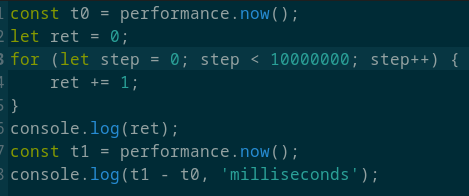

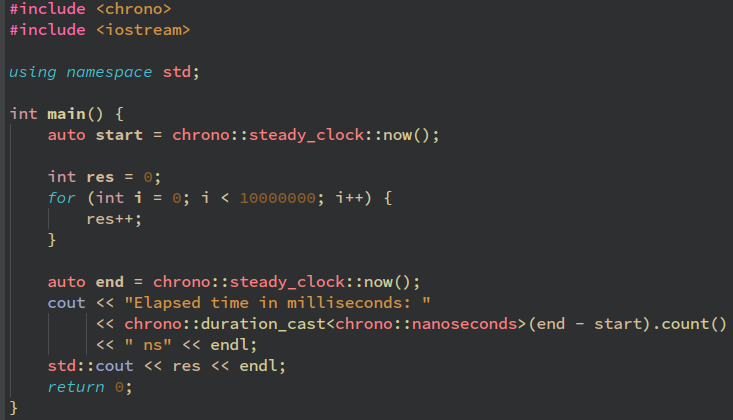
Результаты:

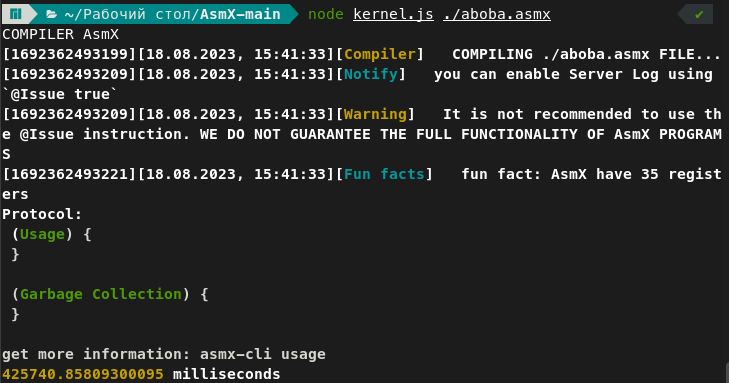

Asmx в 327492307 раз(425740/13 * 10000000/1000, 327.5 миллионов раз) медленнее Javascript и в 72159322030000(425740/0.000059 * 10000000/1000, 72.2 ТРИЛЛИОНА раз) медленнее ВЫСОКОУРОВНЕВОГО языка C++.
Вывод:
AsmX тотально медленнее как сверхвысокоуровневых, так и высокоуровневых языков. Так же асимптотика времени выполнения AsmX хуже, чем у других: для js и cpp асимптотика меньше, либо равна O(n), а для AsmX - ближе к O(n^2), где n - количество итераций.
Дальнейшие бенчмарки считаю бесполезными, вот вам на последок обещания авторов о скорости AsmX:

Часть 5. Post Scriptum
Здесь я хочу объяснить выбор языков и отсутствие классического ассемблера. От самого AsmX ожидалась скорость хотя бы на уровне языка его реализации и продвиутые возможности интерпретатора для оптимизации кода. Именно на проверку этих двух взможностей и был нацелен такой выбор языков для сравнения. Начнём с Javascript, он выбран как бэйзлайн для всех тестов, так как он является бэкенд языком AsmX. С++ выбран, как язык демонстрирующий в данных тестах возможности компилятора по оптимизации, если заглянуть в бинарный код, сгенерированный C++, то можно заметить, что сложения были выполнены компилятором, результат записан в константу и при запуске просто выведен в консоль.
Сравнение со стандартными ассемблерами по скорости считаю непоказательным, так как AsmX на несколько порядков медленнее jit-компилируемого языка Javascript, а сверять возможности компилятора по оптимизации кода просто не с чем, у стандартных ассемблеров полноценного компилятора нет.
Часть 6. Циклы
С новым обновлением было выяснено, что проблема производительности AsmX - в циклах. Без использования условного перехода производительность вырастает вплоть до 100 раз, а асимптотика становится линейной или даже процентов на 10 лучше, чем строго линейная. Это убирает весёлые результаты с 72.2 триллиона раз разницы в производительности(заменяя их на жалкие 300 миллиардов), но пораждает новый вопрос: как можно было так запороть условный переход?
Часть 7. APP v2
Стандарт вышел буквально несколько минут назад и, справедливости ради, он значительно лучше APP v1. Он поддерживает все инструкции, кроме ветвлений (Рискну предположить, что причина в тотально сломанных условных переходах). У него асимптотика чуть лучше линейной(1000 сумм - 300 миллисекунд, 10000 сумм - 2700 миллисекунл), но есть интересный момент: исполнение APP v2 в полтора раза медленнее интерпретации исходного кода:
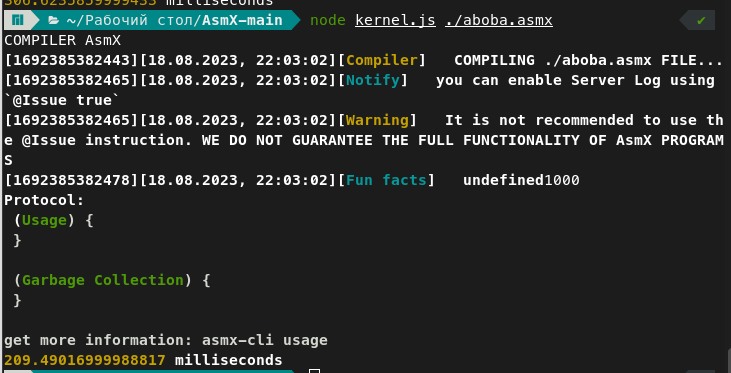

Так что смысл этого формата мне так же непонятен, а разница во времени хоть и сильно сократилась(72 триллиона -> 450 миллиардов по сравнению с C++), не дотягивает даже до бэкенд-языка Javascript.
Так же хочу заметить, что в связи с возможностью тестировать APP файлы с миллионами сложений, была найдена утечка памяти. Привожу пример на APP v2 с 1000 сложений:

Прошу заметить замедление на 20%. При выполнении с меньшим размерам выходит ошибка переполнения кучи:
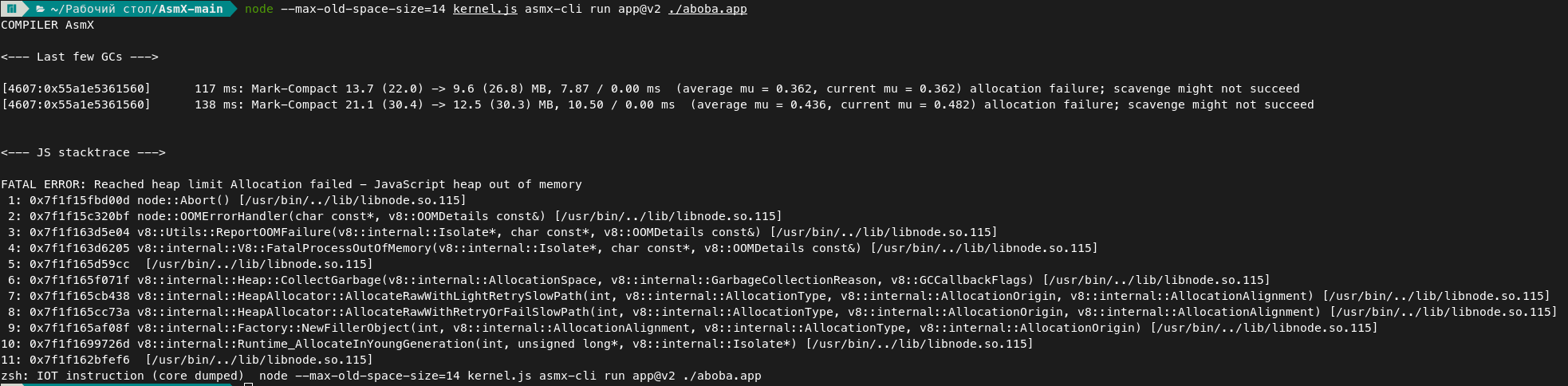
Внимание! Пятнадцать МЕГАБАЙТ памяти на 1000 сложний! посмотрим, как потребление зависит от количества итераций:
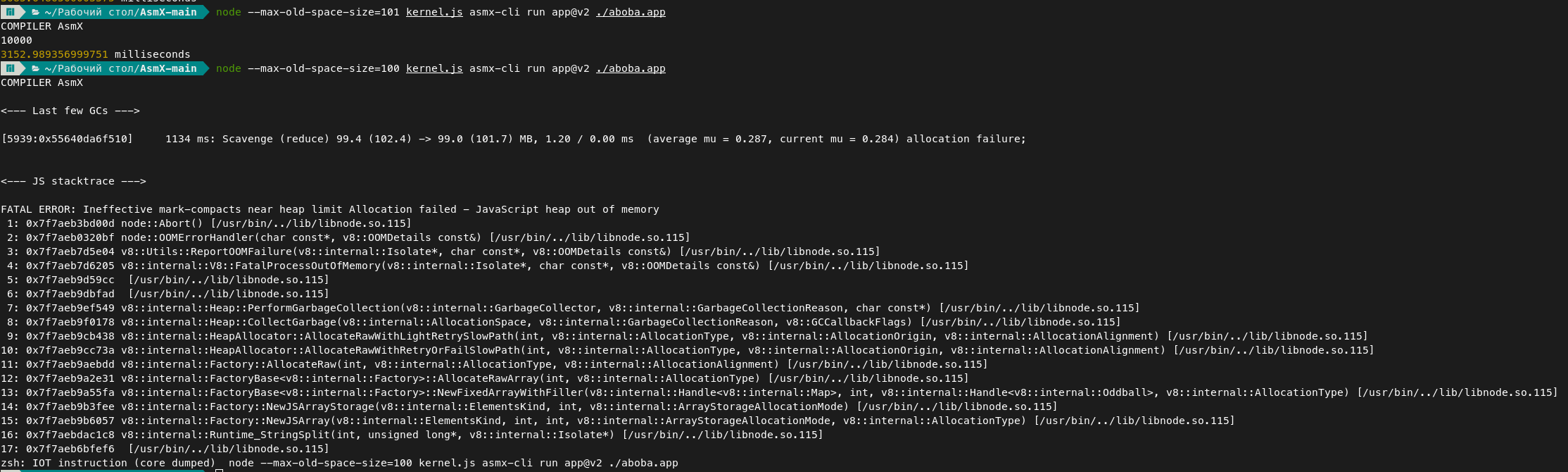
Простим 5 мегабайт памяти на работу самого node.js и получим линейную асимптоту памяти! Получается миллион сложений потребует около 10 гигабайт оперативной памяти для работы! Для сравнения миллиону сумм на Javascript нужно не более 2 МБ памяти:
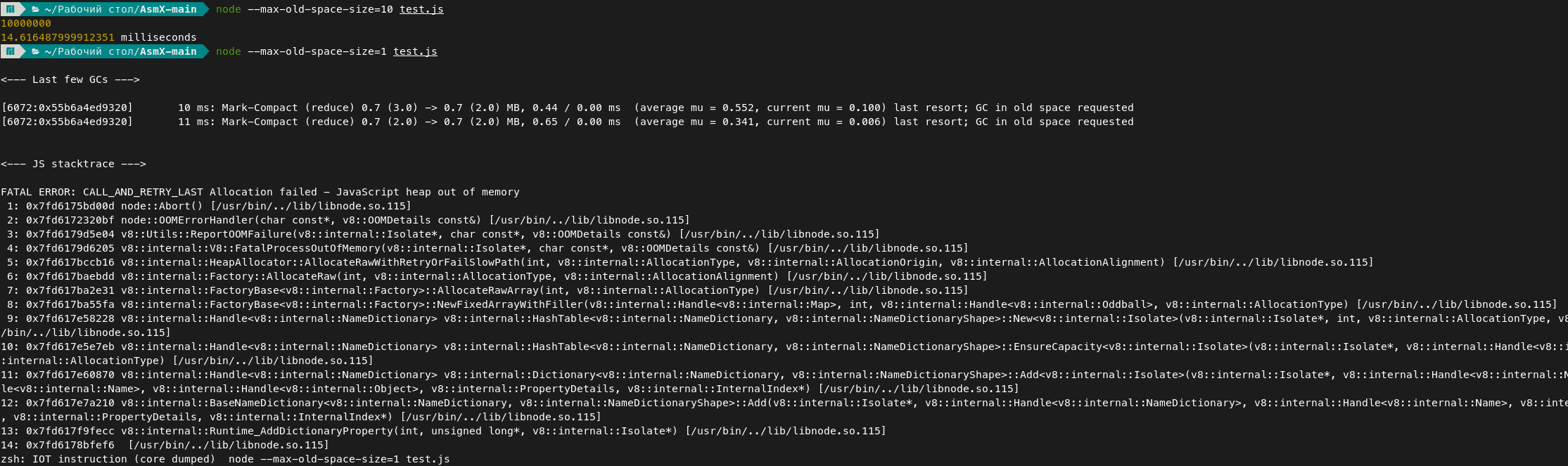
Миллион сумм на C++ же вообще не требует выделения памяти из кучи.
Часть 8. Вывод
Последним обновлением автор значительно улучшил формат APP, однако создал здоровую утечку памяти, всё ещё не догадался писать байты памяти в БИНАРНИК, а не символы текста или то, что выдаёт Javascript'овский buffer.toString(). Циклы сломаны напрочь, интерпретация все ещё самый быстрый способ выполнения, поддерживающий все инструкции. Люблю запах интерпретируемого ассемблера с утечкой памяти и без условных переходов по утрам.