Разница между Hadoop 1 и Hadoop 2
#HadoopHadoop — это программная среда с открытым исходным кодом для хранения большого количества данных и выполнения вычислений. Его фреймворк основан на Java-программировании с некоторым собственным кодом на языке C и сценариями оболочки.
Hadoop 1 против Hadoop 2
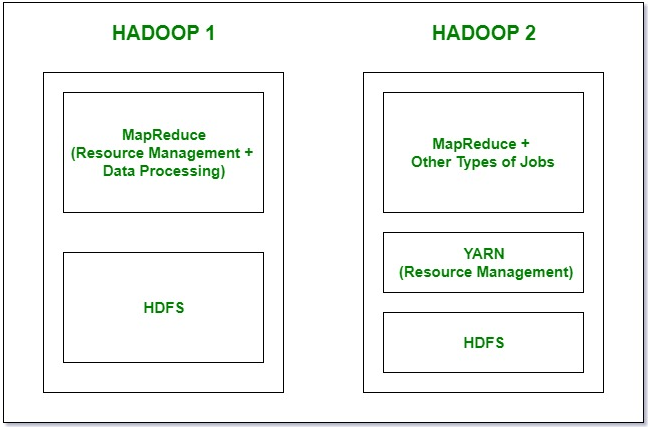
1. Компоненты: в Hadoop 1 у нас есть MapReduce, но в Hadoop 2 есть YARN (еще один посредник по ресурсам) и MapReduce версии 2.

2. Домены:

3. Работа:
- В нем есть HDFS, которая используется для хранения данных, и, кроме того, Map Reduce, которая работает как для управления ресурсами, так и для обработки данных. Из-за этой нагрузки на Map Reduce это повлияет на производительность.
- В, снова есть HDFS, которая снова используется для хранения, а в верхней части HDFS есть YARN, который работает как Управление ресурсами. Он в основном распределяет ресурсы и поддерживает все происходящее.
4. Ограничения:
Hadoop 1 является архитектурой Master-Slave. Он состоит из одного мастера и нескольких рабов. Предположим, что в случае сбоя главного узла, независимо от ваших лучших подчиненных узлов, ваш кластер будет уничтожен. Опять же, создание этого кластера означает, что копирование системных файлов, файлов изображений и т. Д. В другой системе занимает слишком много времени, что не будет восприниматься организациями в наше время.
Hadoop 2 также является архитектурой Master-Slave. Но это состоит из нескольких мастеров (т.е. активных наменодов и резервных наменодов) и нескольких рабов. Если здесь произошел сбой мастер-узла, то его перехватит резервный мастер-узел. Вы можете создать несколько комбинаций активных резервных узлов. ,
5. Экосистема
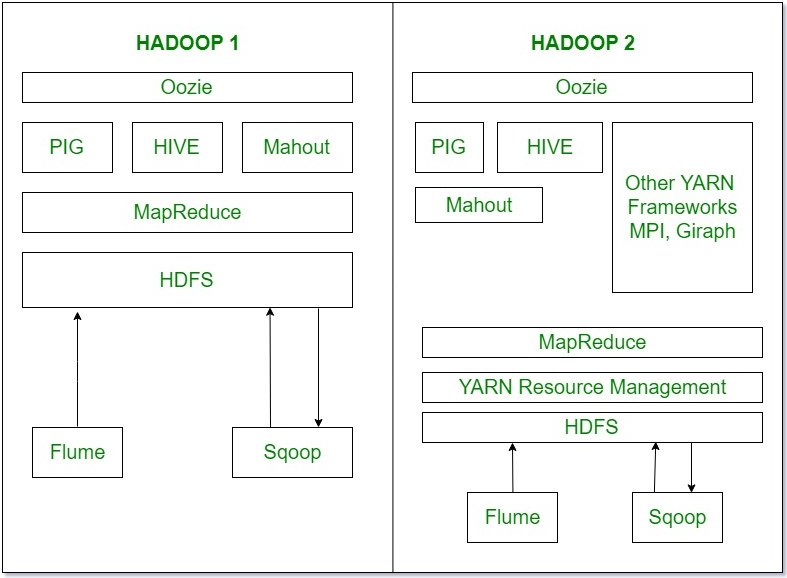
- это в основном Work Flow Scheduler. Он определяет конкретное время выполнения заданий в зависимости от их зависимости.
- являются инструментами обработки данных, которые работают на вершине Hadoop.
- используется для импорта и экспорта структурированных данных. Вы можете напрямую импортировать и экспортировать данные в HDFS, используя базу данных SQL.
- используется для импорта и экспорта неструктурированных данных и потоковых данных.