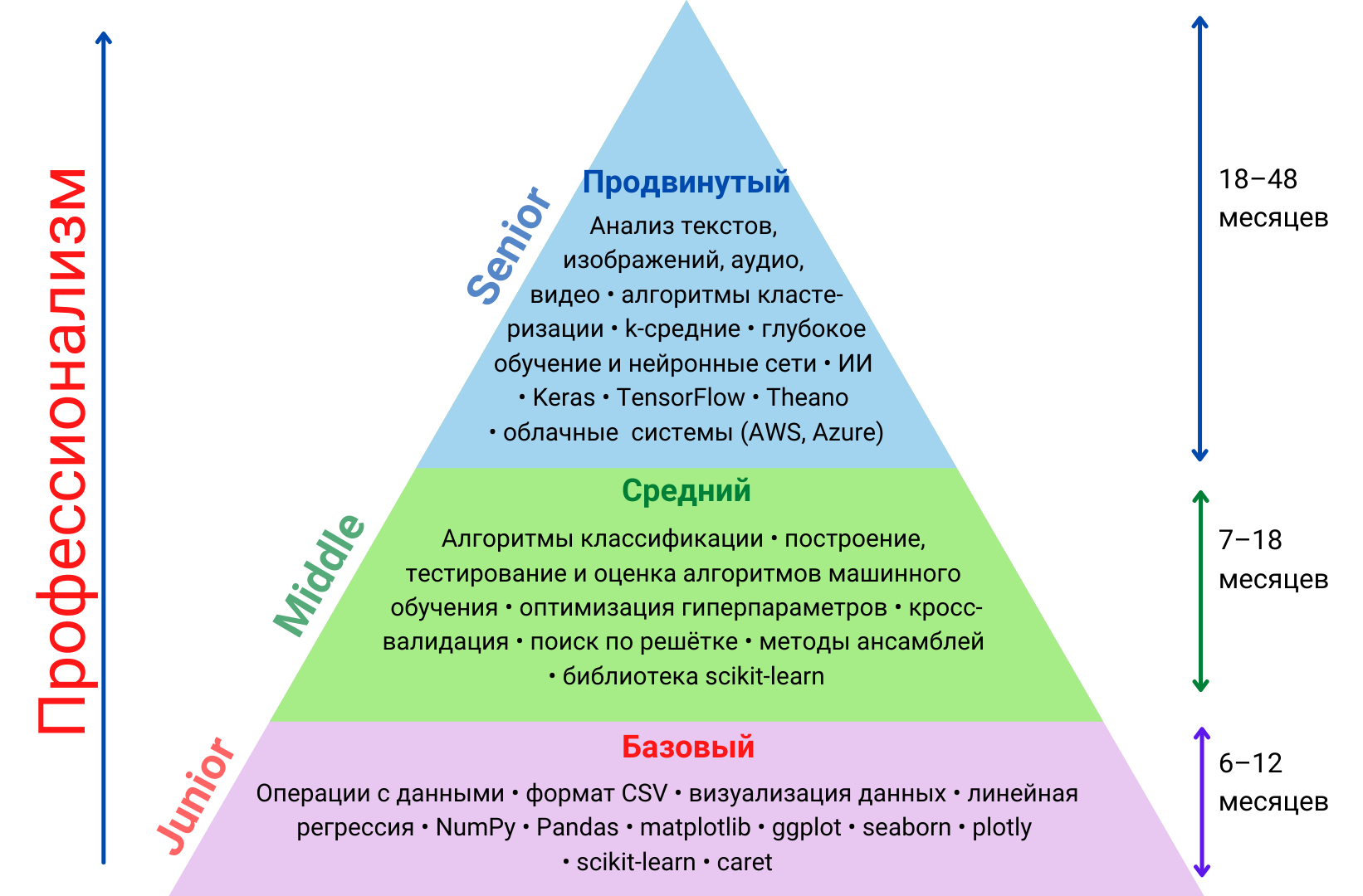
Карта развития дата-сайентиста: с чего начать, к чему идти и сколько времени потребуется
https://t.me/ai_machinelearning_big_dataКаждый, кто заинтересовался наукой о данных, задаётся вопросом: а сколько времени понадобится, чтобы её изучить? Мы составили примерный график профессионального развития дата-сайентиста по трём уровням — базовый, средний и продвинутый. Чтобы было проще сравнивать с требованиями вакансий, привели их к принятым в IT терминам: стажёр (intern), джун (junior, младший), мидл (middle, средний) и сеньор (senior, старший).
Уровни для дата-сайентиста рассмотрим на примере языка Python. Но вообще в Data Science используют и другие языки и платформы — R, Julia, SAS, MATLAB.

Уровень 1. От стажёра к джуну
Главное на этом уровне — научиться работать с датасетами в виде CSV-файлов, обрабатывать и визуализировать данные, понимать, что такое линейная регрессия.
Основы обработки данных
В первую очередь придётся манипулировать данными, чистить, структурировать и приводить их к единой размерности или шкале. От новичка ждут уверенной работы с библиотеками Pandas и NumPy и некоторых специальных навыков:
- импорт и экспорт данных в CSV-формате;
- очистка, предварительная подготовка, систематизация данных для анализа или построения модели;
- работа с пропущенными значениями в датасете;
- понимание принципов замены недостающих данных (импутации) и их реализация — например, замена средними или медианами;
- работа с категориальными признаками;
- разделение датасета на обучающую и тестовую части;
- нормировка данных с помощью нормализации и стандартизации;
- уменьшение объёма данных с помощью техник снижения размерности — например, метода главных компонент.
Визуализация данных
Новичок должен знать основные принципы хорошей визуализации и инструменты — в том числе Python-библиотеки matplotlib и seaborn (для R — ggplot2).
Какие компоненты нужны для правильной визуализации данных:
- Данные. Прежде чем решить, как именно визуализировать данные, надо понять, к какому типу они относятся: категориальные, численные, дискретные, непрерывные, временной ряд.
- Геометрия. То есть какой график вам подойдёт: диаграмма рассеяния, столбиковая диаграмма, линейный график, гистограмма, диаграмма плотности, «ящик с усами», тепловая карта.
- Координаты. Нужно определить, какая из переменных будет отражена на оси x, а какая — на оси y. Это важно, особенно если у вас многомерный датасет с несколькими признаками.
- Шкала. Решите, какую шкалу будете использовать: линейную, логарифмическую или другие.
- Текст. Всё, что касается подписей, надписей, легенд, размера шрифта и так далее.
- Этика. Убедитесь, что ваша визуализация излагает данные правдиво. Иными словами, что вы не вводите в заблуждение свою аудиторию, когда очищаете, обобщаете, преобразовываете и визуализируете данные.
Обучение с учителем: предсказание непрерывных переменных
Главное: стажёру придётся изучить методы регрессии, стать почти на ты с библиотеками scikit-learn и caret, чтобы строить модели линейной регрессии. Но чтобы стать полноценным джуниором, стажёр должен знать и уметь ещё кучу всего (осторожно — там сложные слова, но есть подсказки):
- проводить простой регрессионный анализ с помощью NumPy или Pylab;
- использовать библиотеку scikit-learn, чтобы решать задачи с множественной регрессией;
- понимать методы регуляризации: метод LASSO, метод упругой сети, метод регуляризации Тихонова;
- знать непараметрические методы регрессии: метод k-ближайших соседей и метод опорных векторов;
- понимать метрики оценок моделей регрессии: среднеквадратичная ошибка, средняя абсолютная ошибка и коэффициент детерминации R-квадрат;
- сравнивать разные модели регрессии.
А как вы хотели — сделать Терминатора непросто :)
Уровень 2. От джуна к мидлу
Прочно закрепив на практике все те неприличные слова из блока для джуна, можно штурмовать более продвинутые техники и методы: предсказание дискретных переменных в обучении с учителем (supervised learning), оценку и настройку моделей, а также сбор разных алгоритмов в единые ансамбли методов. Вы уже поняли, что сейчас опять начнётся ковровое бомбометание дата-сайентистскими терминами? Не вздумайте употреблять их в публичных местах — а то бабушки начнут креститься, как будто увидели сатаниста или парня с татуировками по всему телу :)
Обучение с учителем: предсказание дискретных переменных
Начните с алгоритмов бинарной классификации — вот какие надо знать мидлу:
- перцептрон;
- логистическая регрессия;
- метод опорных векторов;
- решающие деревья и случайный лес;
- k-ближайших соседей;
- наивный байесовский классификатор.
Мастхэв — на хорошем уровне работать с библиотекой scikit-learn (она уже тут мелькала), которая помогает строить модели. Также придётся решать задачи на нелинейную классификацию с помощью метода опорных векторов, освоить несколько метрик для оценки алгоритмов классификации — точность, погрешность, чувствительность, матрица ошибок, F-мера, ROC-кривая.
Оценка моделей и оптимизация гиперпараметров
Чтобы правильно оценивать и настраивать модели, специалисту нужно:
- соединять трансформеры (к Оптимусу Прайму и Бамблби они отношения не имеют — пока) и модули оценки (estimators) в конвейеры машинного обучения (machine learning pipelines).
- использовать кросс-валидацию для оценки модели;
- устранять ошибки в алгоритмах классификации с помощью кривых обучения и валидации;
- выявлять проблемы смещения и дисперсии с помощью кривых обучения;
- работать с переобучением и недообучением, используя кривые валидации;
- настраивать модель машинного обучения и оптимизировать гиперпараметры с помощью поиска по решётке;
- читать и правильно интерпретировать матрицу ошибок;
- строить и правильно толковать ROC-кривую.
Сочетание разных моделей в ансамбле методов
- использовать ансамбль методов с различными классификаторами;
- комбинировать разные алгоритмы классификации;
- знать, как оценить и настроить ансамбль моделей классификации.
Уровень 3. От мидла к сеньору
На этом уровне дата-сайентист углубляется в конкретную специализацию — и разбег по требованиям может быть очень большим. Однако каждому благородному дону, то есть сеньору, точно придётся работать со сложными датасетами: текстом, изображениями, аудио (голос) и видео. Поэтому к навыкам среднего уровня добавится вот что:
- алгоритм кластеризации (обучение без учителя);
- k-средние;
- глубокое обучение;
- нейронные сети;
- библиотеки Keras, TensorFlow, Theano;
- основы разработки в облачных сервисах: AWS, Azure.
Дорожная карта развития навыков Data Science
Итак, чтобы стать специалистом базового уровня, понадобится от 6 до 12 месяцев. Вырасти с базового уровня до среднего можно за 7–18 месяцев. Продвинутый уровень потребует ещё от 18 до 48 месяцев.
Программирование: что и как учить?
Что такое SQL и зачем его учить?
SQL является стандартом для получения данных в нужном виде из разных баз данных. Это тоже своеобразный язык программирования, который дополнительно к своему основному языку используют многие программисты. Большинство самых разных баз данных использует один и тот же язык с относительно небольшими вариациями.
SQL простой, потому что он "декларативный": нужно точно описать "запрос" как должен выглядеть финальный результат, и всё! - база данных сама покажет вам данные в нужной форме. В обычных "императивных" языках программирования нужно описывать шаги, как вы хотите чтобы компьютер выполнил вашу инструкцию. C SQL намного легче, потому что достаточно только точно понять что вы хотите получить на выходе.
Сам язык программирования - это ограниченный набор команд.
Когда вы будете работать с данными - даже аналитиком, даже необязательно со знанием data science, - самой первой задачей всегда будет получить данные из базы данных. Поэтому SQL надо знать всем. Даже веб-аналитики и маркетологи зачастую его используют.
Как учить SQL:
Наберите в Гугле "sql tutorial" и начните учиться по первой же ссылке. Если она вдруг окажется платной, выберете другую. По SQL полно качественных бесплатных курсов.
На русском языке тоже полно курсов. Выбирайте бесплатные.
Главное - выбирайте курсы, в которых вы можете сразу начать прямо в браузере пробовать писать простейшие запросы к данным. Только так, тренируясь на разных примерах, действительно можно выучить SQL.
На изучение достаточно всего лишь от 10 часов (общее понимание), до 20 часов (уверенное владение большей частью всего необходимого).
Почему именно Python?
В первую очередь, зачем учить Python. Возможно, вы слышали что R (другой популярный язык программирования) тоже умеет очень многое, и это действительно так. Но Python намного универсальнее. Мало сфер и мест работы, где Python вам не сможет заменить R, но в большинстве компаний, где Data Science можно делать с помощью Python, у вас возникнут проблемы при попытке использования R. Поэтому - точно учите Python. Если вы где-то услышите другое мнение, скорее всего, оно устарело на несколько лет (в 2015г было совершенно неясно какой язык перспективнее, но сейчас это уже очевидно).
У всех других языков программирования какие-либо специализированные библиотеки для машинного обучения есть только в зачаточном состоянии.
Как учить Python
Основы:
Прочитать основы и пройти все упражнения с этого сайта можно за 5-40 часов, в зависимости от вашего предыдущего опыта.
После этого варианты (все эти книги есть и на русском):
1 Learning Python, by Mark Lutz (5 издание). Существует и на русском.
Есть много книг, которые сразу обучают использованию языка в практических задачах, но не дают полного представления о детальных возможностях языка.
Эта книга, наоборот, разбирает Python досконально. Поэтому по началу её чтение будет идти медленнее, чем аналоги. Но зато, прочтя её, вы будете способны разобраться во всём.
Я прочёл её почти целиком в поездах в метро за месяц. А потом сразу был готов писать целые программы, потому что самые основы были заложены в pythontutor.ru, а эта книга детально разжевывает всё.
В качестве практики берите, что угодно, когда дочитаете эту книгу до 32 главы, и решайте реальные примеры (кстати, главы 21-31 не надо стараться с первого раза запоминать детально. Просто пробежите глазами, чтобы вы понимали что вообще Python умеет).
Не надо эту книгу (и никакую другую) стараться вызубрить и запомнить все детали сразу. Просто позже держите её под рукой и обращайтесь к ней при необходимости.
Прочитав эту книгу, и придя на первую работу с кучей опытных коллег, я обнаружил, что некоторые вещи знаю лучше них.
2 Python Crash Course, by Eric Matthes
Эта книга проще написана и отсеивает те вещи, которые всё-таки реже используются. Если вы не претендуете быстрее стать высоко-классным знатоком Python - её будет достаточно.
3 Automate the Boring Stuff with Python
Книга хороша примерами того, что можно делать с помощью Python. Рекомендую просмотреть их все, т.к. они уже похожи на реальные задачи, с которыми приходится сталкиваться на практике, в том числе специалисту по анализу данных.
Какие трудозатраты?
Путь с нуля до уровня владения Python, на котором я что-то уже мог, занял порядка 100ч. Через 200ч я уже чувствовал себя уверенно и мог работать над проектом вместе с коллегами.
(есть бесплатные программы - трекеры времени, некоторым это помогает для самоконтроля)
все эти книги есть тут бесплано.
Конечно, это приблизительные сроки. Многое зависит от бэкграунда: тем, кто неплохо прокачан в физике, математике, естественных и компьютерных науках, работал инженером или финансистом, будет гораздо проще. Но в первую очередь важны усилия и время, которые вы вкладываете в изучение Data Science, — в общем, никакой магии. Просто берём и делаем.