Как устроены GPT чат-боты. Часть 3
@QuantValerianМы уже разобрались с тем, что такое нейросеть, эмбеддинг, контекст, как кодировать и декодировать тексты и контекст, как обучать нейросеть. Давайте теперь попробуем выучить согласование токенов между собой в тексте.
Например, прилагательное будет иметь разные окончания в зависимости от рода существительного, а сам смысл существительного может зависеть от наречия перед ним. Кроме того, во многих языках порядок слов в предложении определяет, где там подлежащее, сказуемое, объект и субъект, а артикли могут подсказывать число и род.
Кодируем порядок токенов
До этого момента мы с вами кодировали только состав контекста. Теперь ясно, что порядок токенов тоже несет полезную информацию. Закодировать его достаточно просто. Берем эмбеддигновую таблицу для наших контекстов, размерности AxCxB (A -- размер алфавита, C -- размер контекста). Создаём такую же таблицу, но в размерности CxB. Считаем, что вторая таблица хранит вектора, кодирующие место токена в контексте.
Складываем эти таблицы вместе (для каждого A добавляем одну и ту же позиционную таблицу) -- получаем эмбеддинг, в котором и сами токены и их положение в контексте. Дальше мы будем работать именно с этими эмбеддингами. Более подробно можно посмотреть вот в этом кусочке видео:
Собираем аттеншен
Query
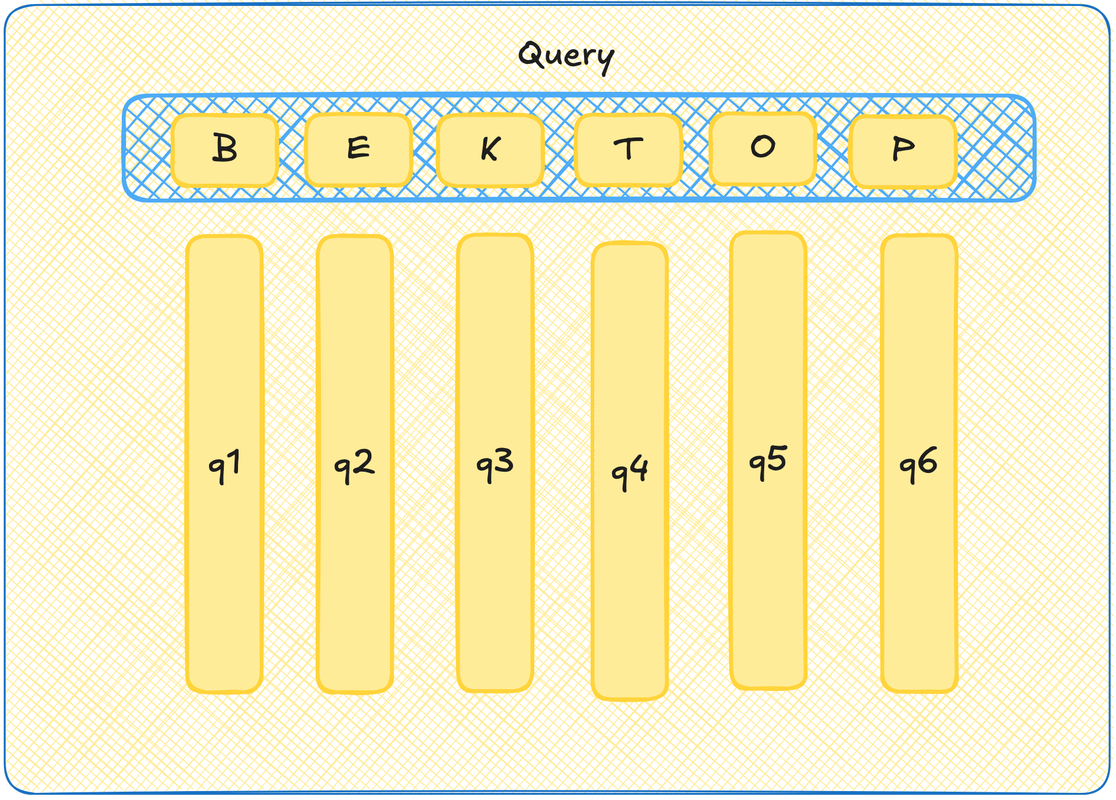
Давайте представим, что каждый токен из нашего контекста отправляет вопрос во вселенную. Например, а есть ли в контексте молодые спортивные прилагательные с зависимостью от курения и любовью к античным текстам? На самом деле, мы, как обычно, не знаем, что там за вопрос, мы вообще всё случайными числами заполняем, но пусть для примера сойдет. Вот у каждого токена тогда пусть будет вектор-вопрос -- query.
Чтобы было красиво и видеокарточно, давайте еще скажем, что на самом деле есть матрица Query, при умножении ембеддинга токена на которую, мы получим вот этот вектор вопрос. Тогда все вектора вопросы хранятся в матрице Query, а чтобы получить любой из них, достаточно взять эмбеддинг токена и с этой матрицей перемножить.
Key
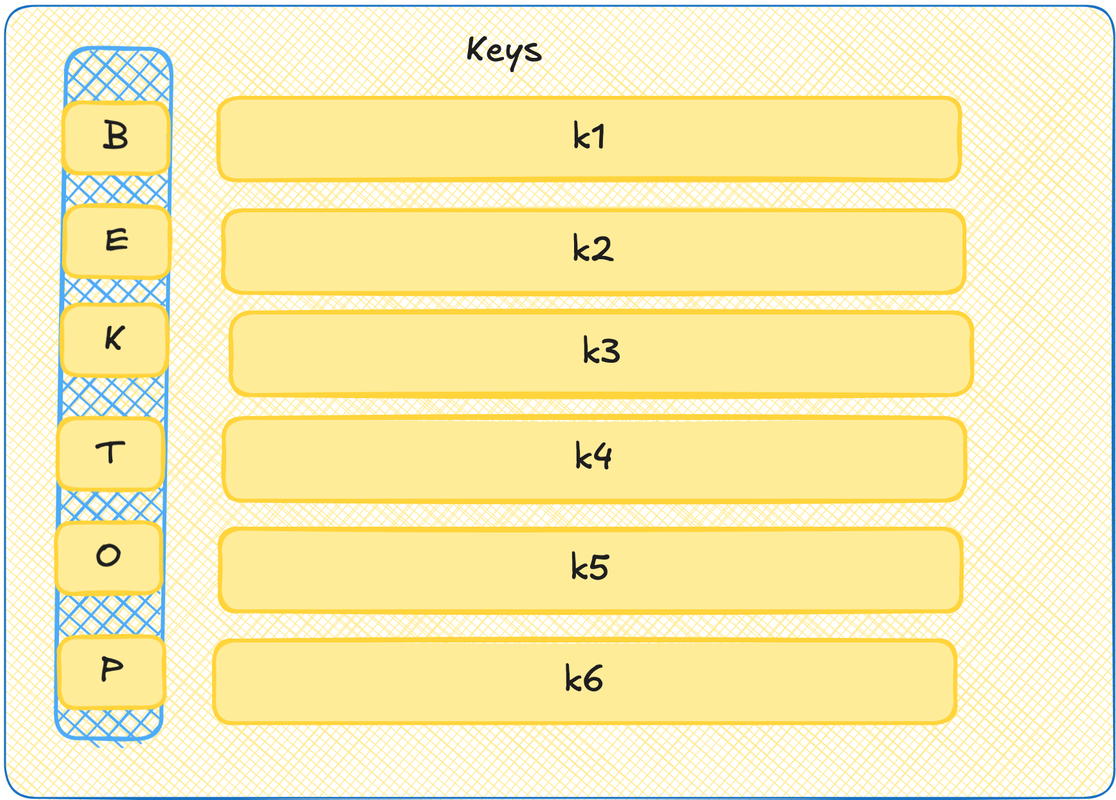
Теперь давайте представим ещё, что каждый токен умеет рассказывать о себе. Ну то есть вот если query выше -- это поиск по анкетам на сайте знакомств, то тут у нас будут сами анкеты. Давайте тоже скажем, что это такие векторы. И давайте эти векторы тоже закодируем в матрице. Такая матрица будет называться Key.
А теперь давайте мэтчить! Если query это вектор, и key это вектор, то можно их перемножить скалярно и узнать степень их сонаправленности. Получается, подбираем наиболее подходящие пары!
Value
Это круто, что мы нашли самых подходящих, но что с этим теперь делать? Теперь мы хотим поменять наш изначальный эмбеддинг! Мы хотим повернуть вектор нашего токена в "смысловом" пространстве так, чтобы он лучше соответствовал контексту, в котором находится. Повернуть вектор можно добавив к нему другой вектор в том же пространстве. С помощью Query x Key мы определили, какие токены влияют на текущий сильно, а какие слабее. То есть длины этих добавочных векторов нам уже ясны. А вот чтобы задать их направления мы возьмем ещё одну матрицу - Value. Она также поставит в соответствие каждому токену из контекста вектор.
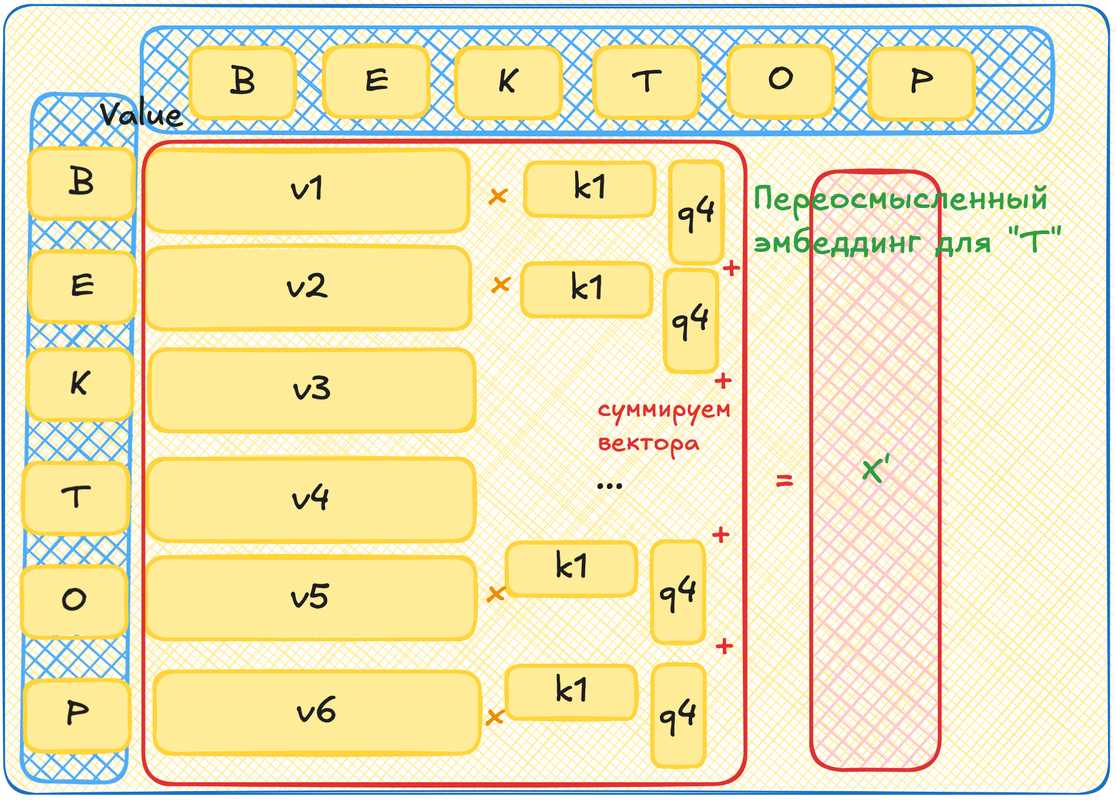
Теперь мы выбираем любой токен из контекста. Генерим для него query вектор. Для всех остальных генерим key вектора и value вектора. Умножаем query на key. Теперь для каждого value вектора умножаем его на получившееся произведение. Теперь складываем все эти вектора, мы можем, они в одном пространстве. Это получился вектор, на который нужно повернуть эмбеддинг нашего первого токена, чтобы он учел окружающий его контекст.
Multi-head attention
Этот механизм и называется голова аттеншена. А теперь, если мы для каждого слова сгенерируем по несколько таких "анкет" query, key и value, то сможем зацепить повороты в разных пространствах! То есть сможем учесть больше разных смыслов. У нас будет профиль не только по тиндеру, но и по линкедин. Использование сразу нескольких наборов таких матриц (с учетом магии линейной алгебры для более эффективных вычислений) называется многоголовым аттеншеном.
Гораздо понятнее станет, если посмотреть вот это видео в с красивыми картинками:
Feed Forward
Значит, повернули мы ембеддинги в самые правильные места, казалось бы, всё! Но не так быстро! Я, честно, не очень понимаю, зачем нужен конкретно вот этот кусок в трансформере. Мои ожидания были, что он никакого качества не добавит. И он (по чистому совпадению) в видео Андрея нифига и не добавил (или добавил, но я запомнил иначе!). Однако, Андрей объясняет, что после аттеншена слова узнали что-то про соседей, но полученную информацию ещё не переварили. Вот, чтобы её как-то обратботать, нужен еще один просто Multi-Layer Perceptron из первой части поста. Он и называется Feed Forward. Про него эпизод здесь:
Add & Norm
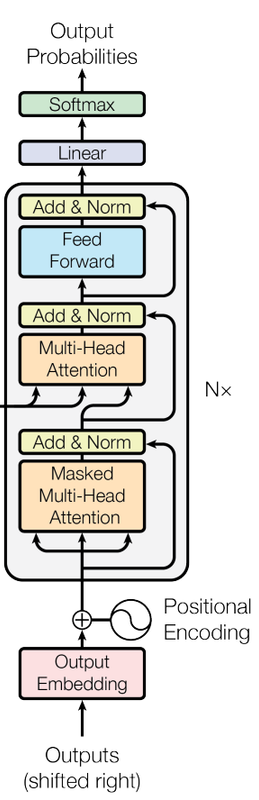
Add
Вот мы эмбеддинги наши повернули куда-то. Потом ещё поворачивать будем. Так можно далеко уехать! Поэтому мы возьмём эмбеддинги до аттеншена и прибавим к эмбеддингам после аттеншена. Если задуматься, то у нас был для токена вектор X. Мы к нему добавили аттеншен, какой-то ΔX. А теперь снова добавляем изначальный X. То есть мы как бы удваиваем силу изначального направления вектора! X' = X + ΔX + X = 2X + ΔX
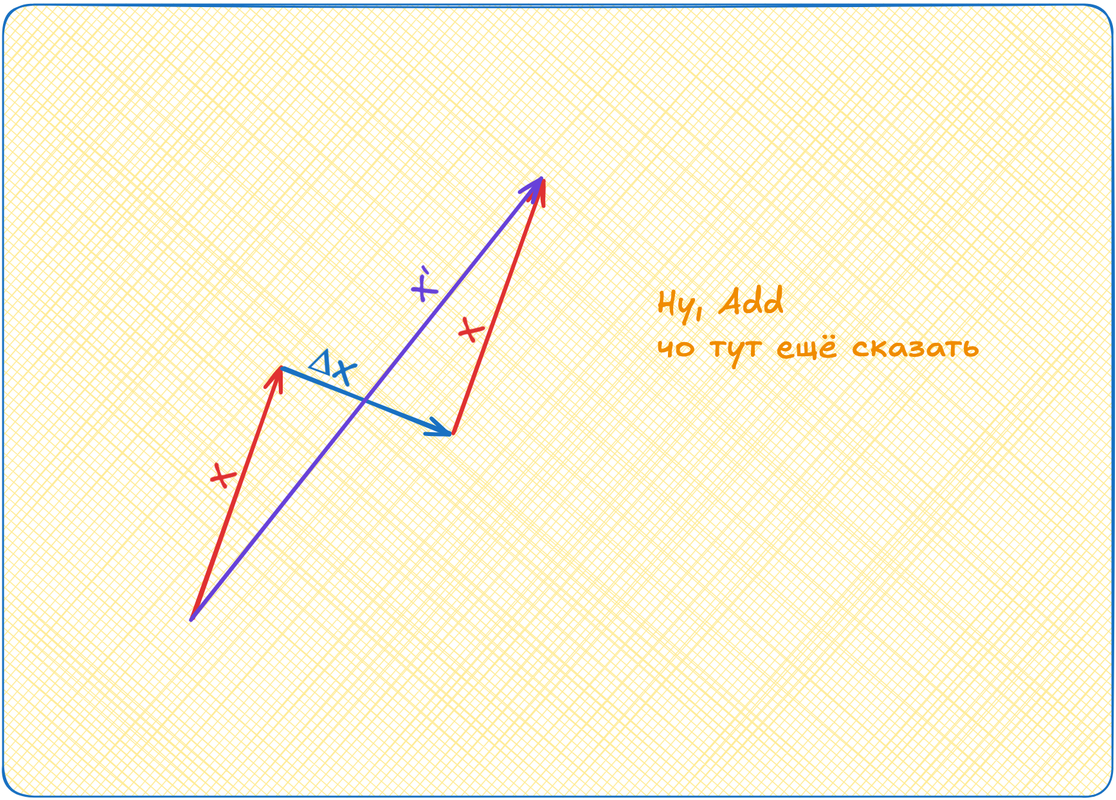
Эта штука добавляет стабильности работе модели и называется Add.
Norm
Кто позвал Осетинскую? Показалось!
Так вот, параметры разъезжаются, числа достигают девятизначных значений и всё такое. Поэтому добавляют этап layer norm. Это процедура, когда мы берем выходы слоя нейросети и делаем трансформацию значений в нём так, чтобы среднее стало ноль, а дисперсия один. Андрей ещё говорит, что Norm сейчас принято делать перед аттеншен, перед фид форвард и т.д., а не после, как на картинке выше.
Повторить всё сто тыщ мильонов раз
Повторяем блок Attention -> Feed Forward, Add&Norm между ними -- кучу раз. Радуемся, что обучение находит в наших случайно инициализированных матрицах разные оптимумы. Жжём процессорное время видеокарт.
Делаем из Т9 бота-ассистента
Fine tuning
Всё, что я описывал тут три части подряд -- это претрейн! Мы с вами обучили очень крутой, очень тяжелый и медленный Т9. Наша модель сейчас умеет прогнозировать продолжение любого текста на основе того, что сама модель когда-либо видела.
Чтобы превратить её в чатбот-ассистента, нужно теперь тренировать её на данных в формате вопрос-ответ. На большом количестве данных. Её ведь надо переучить с рандомных форматов из интернета, на формат форума или стековерфлоу.
Но этого мало! Скорее всего качество ответов будет так себе! Поэтому мы нанимаем ML-тренеров, которые составляют размеченную базу вопросов-ответов, в которой качество ответов оценено. Этих данных мало и они дорогие. Поэтому на них мы обучим небольшую модель классификации. Она будет смотреть на вопрос и ответ, а выдавать некоторый штраф или поощрение, в зависимости от качества ответа.
С помощью этой небольшой модели нужно доучить нашу большую модель отвечать хорошо.
Но и этого ещё не достаточно! Нужно же всё зацензурировать! Для этого мы возьмем еще модель, которая будет оценивать соответствие ответа правилам. Для этой модели мы задаим правила и еще сделаем тоже модель поощрений и штрафов. Примерно где-то здесь живет этот ваш AI alignment!
Retrieval‑Augmented Generation
Наконец, самое вкусное, что можно добавить своему ассистенту это RAG. Это по-сути база данных с интернетом, в которую может ходить модель. Модель обучается валидировать свои ответы об такую базу, а в выдаче пользователю подкреплять ответы ссылками на эти ресурсы. Типа как нейропоиск у Яндекса. Но тут я уже совсем больше ничего не знаю, поэтому пора закругляться. Спасибо, что были с нами все эти много букв!