Как устроены GPT чат-боты. Часть 2
@QuantValerianИтак, мы примерно поняли, как запихать в нейросеть текст, как из неё вытащить новый текст, что примерно происходит между входом и выходом и как превратить это что-то в нечто осмысленное и полезное.
Теперь давайте попробуем ковырнуть чуть глубже, поймем, как бы так устроить нейросеть, чтобы выдаваемый результат стал получше. Для этого снова посмотрим на кодирование текста.
Эмбеддинги
Давайте нарисуем нейросеть, внутри которой просто перемножим две матрицы. То есть у нас будет вектор длины 33 с одной единичкой и тридцатью двумя нулями. Этот вектор мы умножим на матрицу, скажем, 33 на 5, я рандомно выбираю число, меньшее размера алфавита, чтобы места поменьше занимало. Это всё хозяйство умножим на матрицу 5 на 33. На выходе получится вектор длины 33 из всяких там дробных чисел.
Умножение на матрицу это перевод из одного векторного пространства (букв) в другое (вообще говоря не понятно какое, но размерности 5). Вот это вот другое пространство оказывается удивительным образом смысловым пространством!
Мы можем взять первую матрицу и выбрать там строку с номером интересующей нас буквы. Это будет вектор длины пять. Этот вектор будет кодировать нашу букву в пространстве размерности пять. А вся матрица, получается, это просто таблица таких векторов для каждой буквы. Такая таблица называется эмбеддинг.
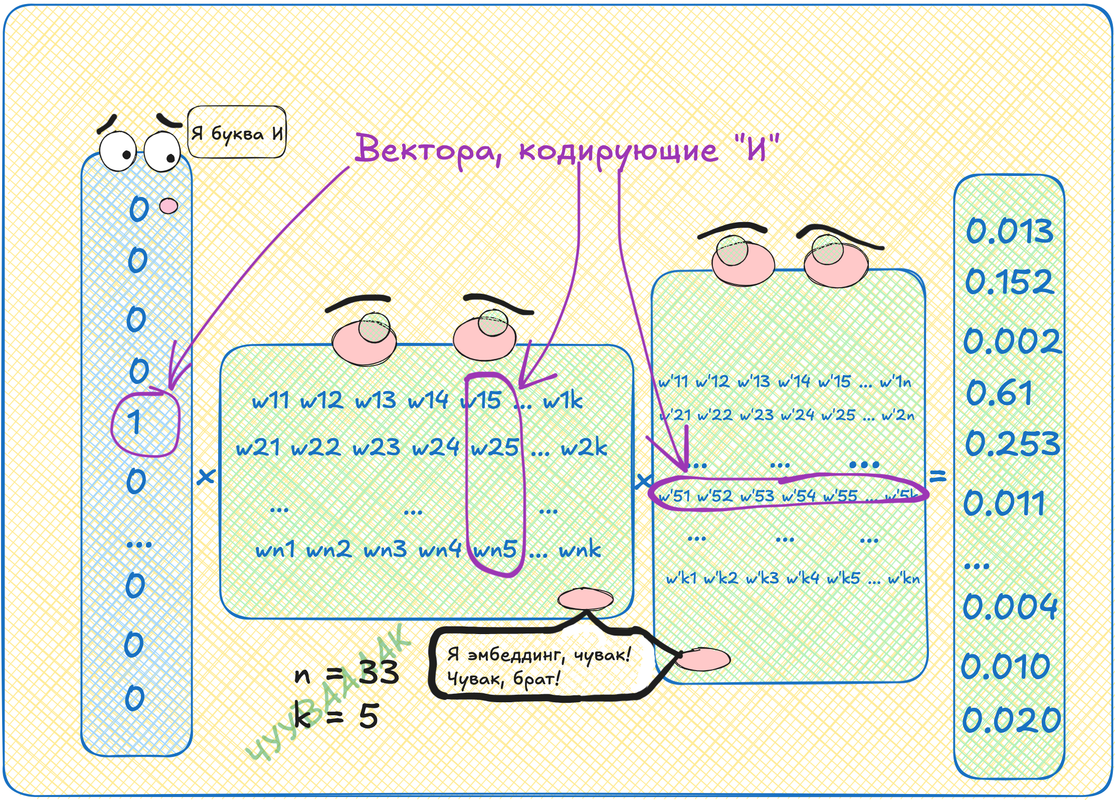
Кстати, можно взять и вторую матрицу, но там нужно будет брать не строки, а столбцы. Значения там будут другими, но смысл примерно такой же.
Самое крутое в этих векторах то, почему я называю их векторами в смысловом пространстве! Если собрать такую табличку для слов, а не для букв (напомню, это значит просто выбрать другой словарь), то можно получить удивительный результат. Берем вектор слова King, вычитаем из него вектор слова Man и добавляем вектор слова Woman. Декодируем получившийся вектор обратно в слово. Получаем Queen! И таких примеров в интернете куча.
Однако, если попробуете сделать по схеме, описанной мной выше, нифига не получится! Потому что для добавления векторам смысла необходимо закодировать в них контекст!
Контекст
Контекст -- это набор токенов, которые встречаются в текстах рядышком с нашим. Мы берем окно размером, например, пять токенов. Накладываем это окно на случайный участок текста. Получаем контекст. Теперь возьмем наш токен (пусть будет последним, пятым в окне) -- его нужно научиться предсказывать по контексту, это таргет. Возьмем оставшиеся четыре токена -- это вход. Их нужно как-то скормить нейросети. Но пока мы умеем подавать на вход только один токен! Что же делать?
А давайте возьмём нашу табличку эмбеддингов. Но теперь возьмем не одну, а четыре такие таблички! Для каждого токена своя табличка. Теперь скажем, что для первого токена в контексте будет использоваться первая табличка, для второго -- вторая и так далее.
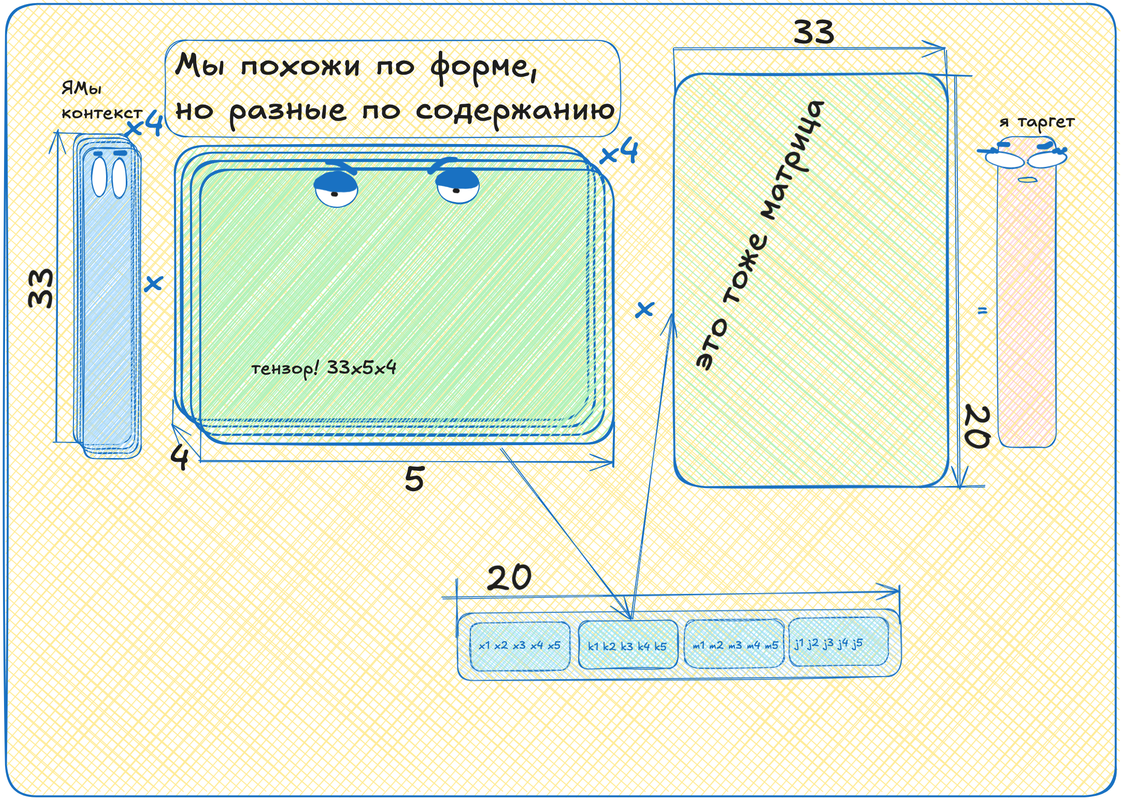
Если сложить эти таблички в стопку, то получится тензор! В нашем случае это будет такая трехмерная "матрица" размером 33 (размер алфавита) на 5 (размерность "смыслового" пространства) на 4 (сколько токенов на входе).
Это всё круто, конечно, но теперь у нас четыре вектора после умножения входа на тензор, а нам нужен один -- кодирующий таргетный токен! Что ж, давайте мы эти четыре вектора просто поставим друг на друга. Было четыре вектора длины пять, а стал один вектор длины двадцать! Тогда вторая матрица должна быть уже не 5 на 33, а 20 на 33, чтобы перевести наш длинный вектор в нужную размерность.
Теперь, если вы такую хитрую конструкцию из т
ензоров, векторов и матриц станете учить:
- закодируете четыре токена
- подадите на вход сети
- там умножите их на тензор
- склеите результаты в один вектор
- который умножите еще на матрицу
- декодируете получившийся вектор в токен
- сравните результат с пятым токеном из контекста
- посчитаете градиент от разницы
- сдвинете веса матрицы вдоль градиента
- повторите кучу раз
Вот после такого обучения ваши эмбеддинги действительно начнут кодировать смыслы и творить чудеса линейной алгебры! Такая штука, кстати, называется word2vec. Чтобы чуть лучше понять, что это и как, рекомендую посмотреть вот это видео:
В следующий раз уже поговорим про трансформеры, про главный их механизм -- аттеншен.