Как устроены GPT чат-боты
@QuantValerianМне внезапно стало интересно, как устроены внутри все эти ChatGPT штуки, которые прям волшебно как-то работают. Поэтому я немного нырнул в тему (и сразу вынырнул, там бескрайняя бездна какая-то, может засосать) и здесь хочу буквально крупными ламерскими мазками расписать, что я там увидел. Ботал я в основном по видосам Andrej Karpathy (далее Андрей), их и буду вставлять в текст.
В первую очередь текст пишу для тех, кто захочет пройти по моему пути. Я крайне рекомендую сделать это, если хочется действительно что-то понять. Ну а я здесь суммирую штуки, над которыми больше всего пришлось думать, гуглить отдельно и которые хотелось бы сначала увидеть в более крупном масштабе, если бы я изучал это заново.
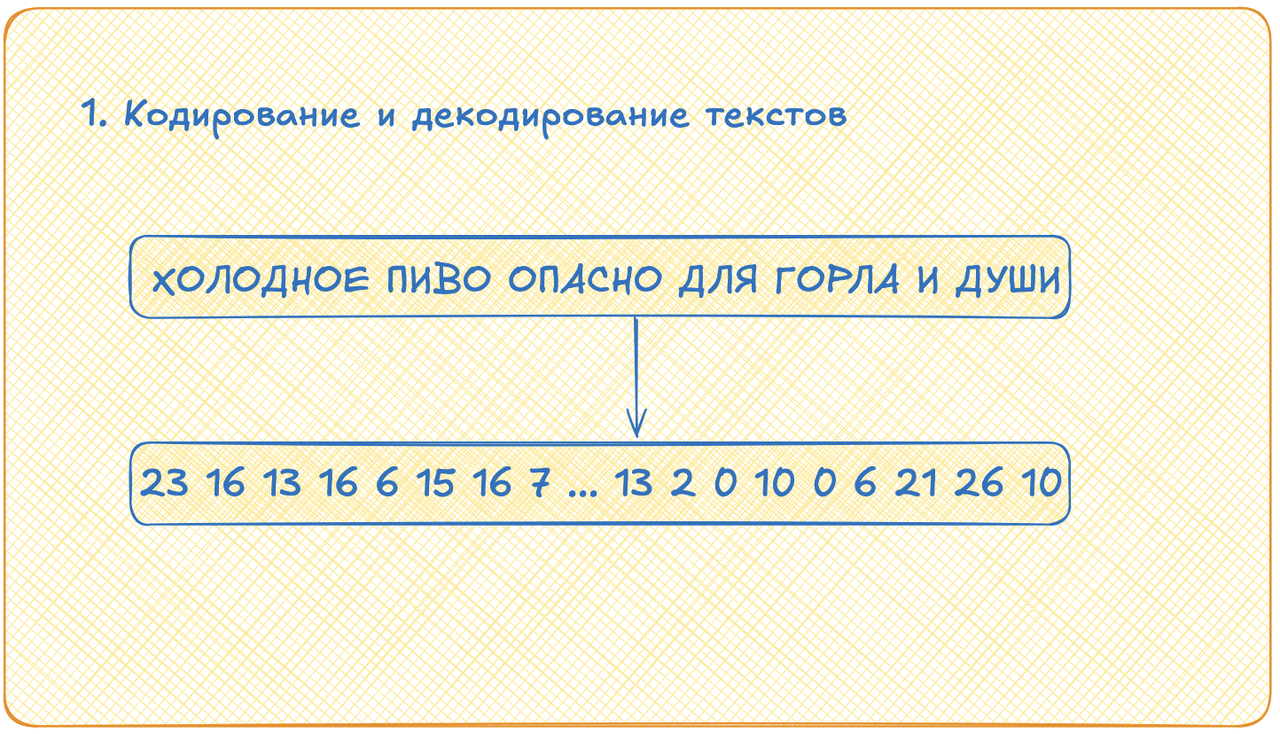
Кодирование и декодирование текста
Первое, что надо разобрать это кодирование и декодирование текста. Здесь всё просто, но меня напугал размер и масштаб! Мы берём все наши тексты, разрезаем их на токены (например, на буквы), все эти токены складываем в отсортированный список. Теперь каждый токен кодируется индексом в этом списке. Всё. Декодируется текст из индексов аналогично: берём число, смотрим, что лежит в списке по индексу, равному этому числу, получаем токен.
Теперь чуть глубже. Каждое такое число будет внутри нейросети кодироваться вектором из нулей и единицы (sic!). Например, буква А будет иметь индекс 1 и кодироваться вектором, где на первом месте единичка, а на остальных нули. Это называется one-hot encoding. Размерность каждого такого вектора равна размерности нашего алфавита токенов. И если для кириллического алфавита нам хватило бы 33 букв, то словари токенов из видосиков, которые я смотрел, имеют более внушительный размер: тысяч пятьдесят, например. Большие такие, длинные векторы нужны, короче.
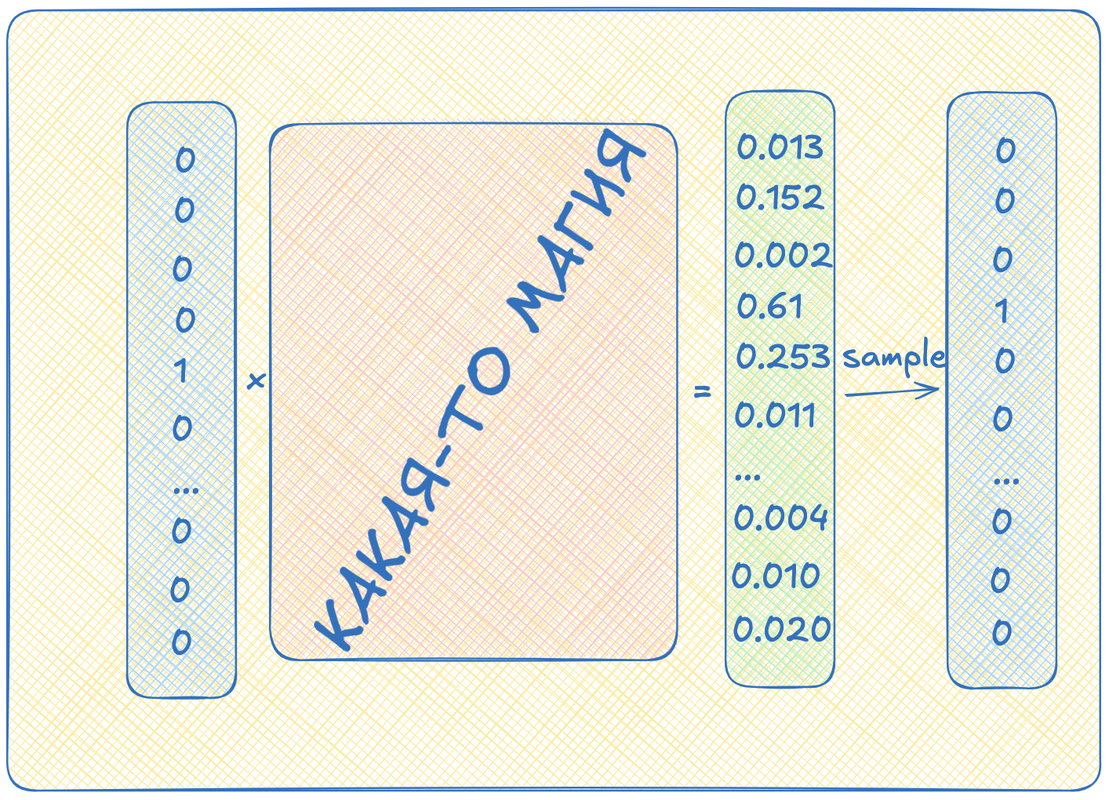
Следующий прикол состоит в том, что нейросеть нам будет выдавать вектор той же размерности, что мы ей дали на вход, но вот содержание там будет совсем другое. На выходе из нейронок мы будем получать вектор вещественных чисел от 0 до 1. Сумма всех чисел в векторе будет равна единице. Мы будем интерпретировать эти числа, как вероятности. Например, если на третьем месте в векторе будет число 0.65, мы будем считать, что с вероятностью 65% нам нужно выбрать число три. А если на пятом месте будет, например 0.03, то с вероятностью 3% будем выбирать число пять.
По сути, выход нейросети будет выдавать нам некоторое распределение, из которого мы будем делать выборку, состоящую из одного элемента. Вот получившееся, выбранное число мы и будем декодировать!
Нейросеть
Теперь настало время посмотреть, что такое сферическая нейросеть в вакууме. Для этого сначала посмотрим на один её узел -- перцептрон. Это штука, которая принимает вектор, собирает взвешенную сумму элементов этого вектора, отображает каким-нибудь образом эту сумму в отрезок от 0 до 1 и выдает результат нуружу. Это, кстати, называется "функция активации".
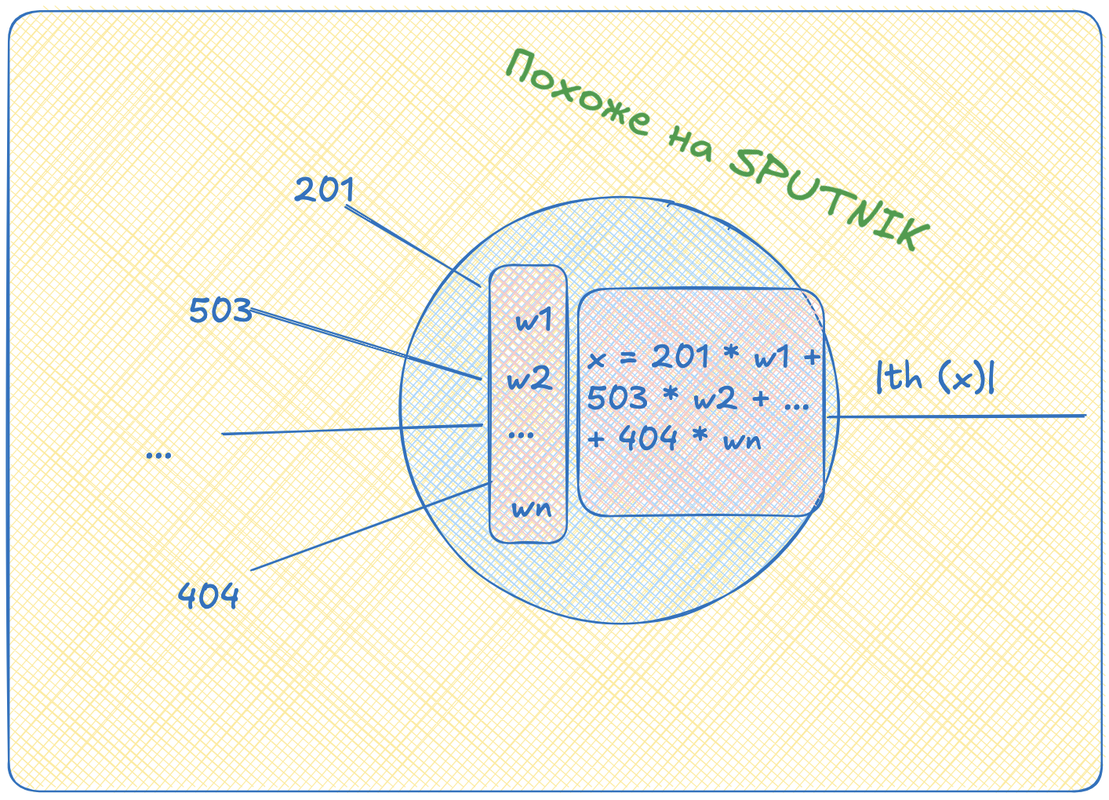
Здесь сразу стоит отослать вас вот к этому видосику
А теперь представьте, что мы такие круглешочки повтыкали друг в друга каким-то образом. Можно выход одного круглешочка воткнуть на вход нескольким другим, например.
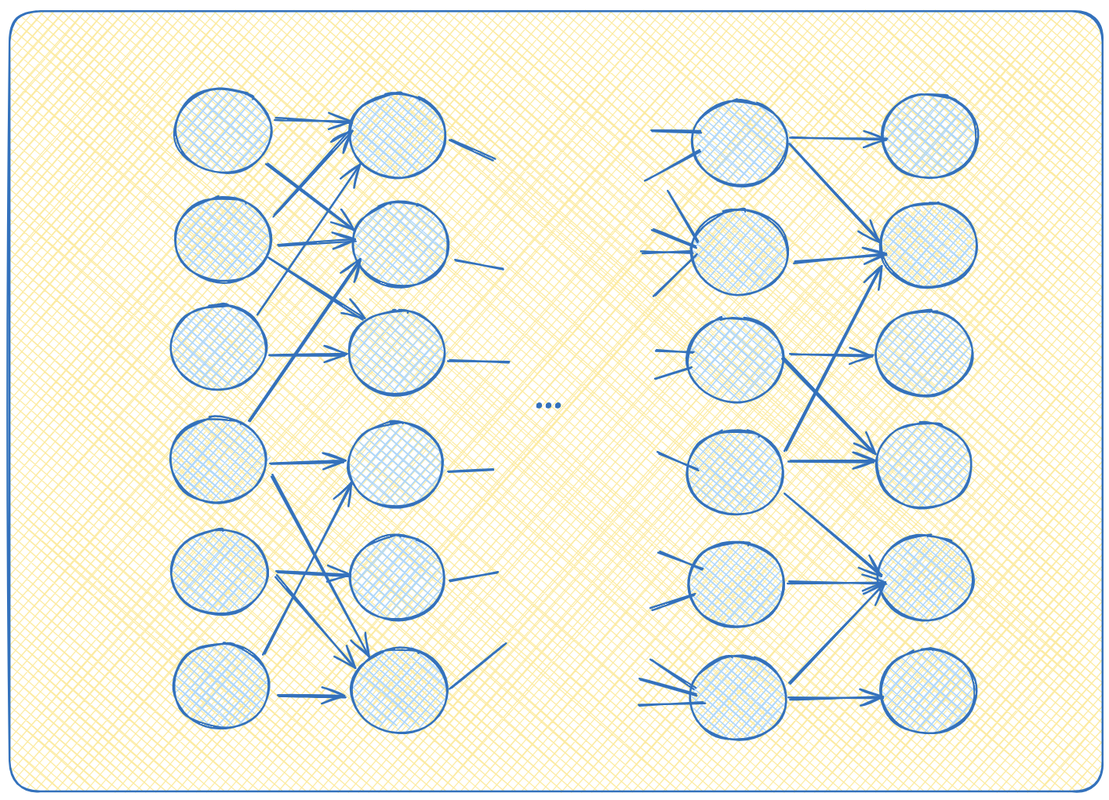
Давайте начнем думать, как появились значения на выходах самых правых перцептронов. Это какие-то th(w1*x1 + w2*x2 + ... + wn*xn). А сами иксы это в свою очередь что-то типа x1 = th (w'1*x'1 + w'2*x'2 + ... + w'n*x'n). И так далее. То есть довольно однообразные вложенные функции. Сильно и глубоко вложенные функции. Если разматывать этот клубок до самого конца, то можно в конце концов явно выписать уравнение: как вычисляются выходы, как функции от входов. Что-то типа y = th(w1*th(w'1*x1+...w'n*xn) + w2*th(....) + ...).
Можно заметить, что взвешенные суммы легко получаются при умножении вектора-строки на вектор-столбец. Ну или просто строки на столбец матрицы. И действительно, оказывается, что нейросеть описывается, как набор матриц, на которые мы умножаем входной вектор. А вот эти вот веса, w, это и есть параметры, веса нейросети. Именно они и записаны в матрицах. После всех этапов перемножений на выходе мы тоже получаем вектор. Вот и вся нейросеть. А я линейную алгебру на первом курсе учить не хотел!
Смотрим Андрея дальше
Обучение
Теперь от этой штуки очень удобно брать производную. Берем вот просто по каждой переменной на входе производную от вот этой длинной функции и получаем градиент. Причем, кто помнит из старших классов правила дифференцирования сложных функций (chain rule), тот может здесь увидеть, что у нас будет много одинаковых вычислений. Запоминая результаты таких повторяющихся вычислений, можно знатно сэкономить вычислительных ресурсов. Эта фишка называется back propagation и подробно с примерами нужно смотреть в этом видео. Есть более общий термин, differentiable programming.
Теперь давайте научим нейронку прогнозировать следующий токен по текущему. Возьмем кусок текста, в нем выберем токен для входа и запомним следующий за ним токен -- правильный выход.
Скормим входной токен в нейросеть, получим какой-то выход. Теперь сравним, насколько сильно этот выход отличается от того, что идет в тексте на самом деле. Вообще не обязательно понимать, как именно считать эту разницу, но для любителей статистики можно взять, например, (negative) log likelihood, а для любителей питона cross entropy (это примерно одно и то же).
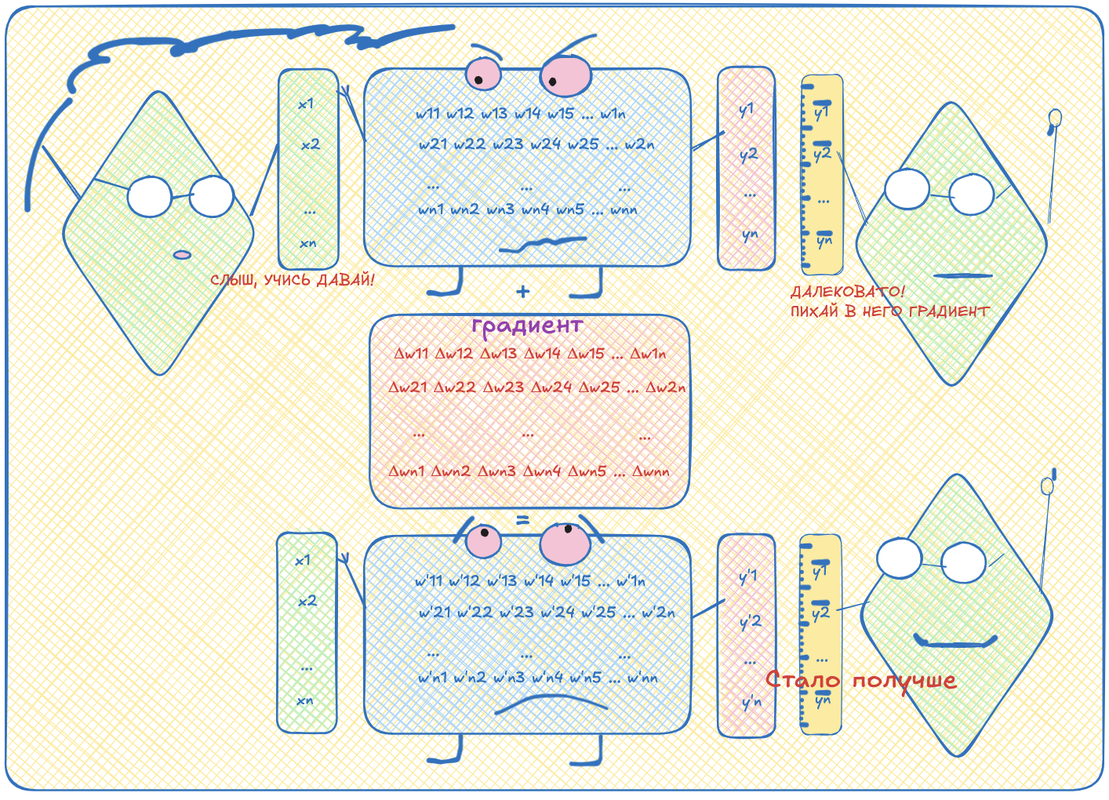
Вот эта разница -- это тоже математическая функция. Её тоже можно продифференцировать. Но давайте её дифференцировать не по переменным входа, а по переменным весам (которые w в формулах были). Тогда мы сможем изменять веса так, чтобы при прогоне нейронки с этими новыми весами, получаемое значение стало больше похоже на ожидаемое. Повторяя процедуру много раз, можно подогнать веся нейронки так, что она будет довольно точно прогнозировать, какой токен должен идти следующим. Статистически, конечно.
В целом, этого достаточно, чтобы примерно представлять себе, как работают нейросети вообще, и как их обучают. В общих чертах. Говорю же, я не эксперт, но даже после просмотра всего-то нескольких видосиков узнал десятки мест, где могут быть какие-то тонкости и различия. От функций активации и топологии сети до методов оптимизации и размерностей матриц внутри.
Итак, мы примерно поняли, как запихать в нейросеть текст, как из неё вытащить новый текст, что примерно происходит между входом и выходом и как превратить это что-то в нечто осмысленное и полезное.
Теперь давайте попробуем ковырнуть чуть глубже, поймем, как бы так устроить нейросеть, чтобы выдаваемый результат стал получше. Для этого снова посмотрим на кодирование текста.
Эмбеддинги
Давайте нарисуем нейросеть, внутри которой просто перемножим две матрицы. То есть у нас будет вектор длины 33 с одной единичкой и тридцатью двумя нулями. Этот вектор мы умножим на матрицу, скажем, 33 на 5, я рандомно выбираю число, меньшее размера алфавита, чтобы места поменьше занимало. Это всё хозяйство умножим на матрицу 5 на 33. На выходе получится вектор длины 33 из всяких там дробных чисел.
Умножение на матрицу это перевод из одного векторного пространства (букв) в другое (вообще говоря не понятно какое, но размерности 5). Вот это вот другое пространство оказывается удивительным образом смысловым пространством!
Мы можем взять первую матрицу и выбрать там строку с номером интересующей нас буквы. Это будет вектор длины пять. Этот вектор будет кодировать нашу букву в пространстве размерности пять. А вся матрица, получается, это просто таблица таких векторов для каждой буквы. Такая таблица называется эмбеддинг.
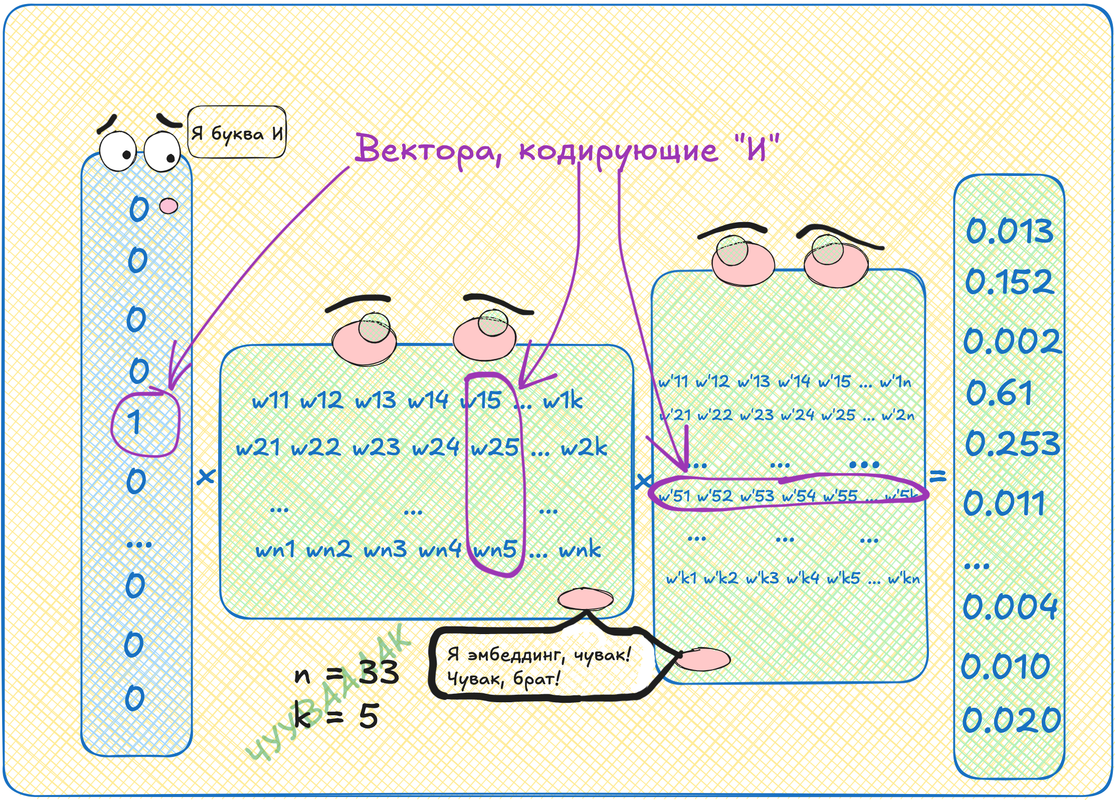
Кстати, можно взять и вторую матрицу, но там нужно будет брать не строки, а столбцы. Значения там будут другими, но смысл примерно такой же.
Самое крутое в этих векторах то, почему я называю их векторами в смысловом пространстве! Если собрать такую табличку для слов, а не для букв (напомню, это значит просто выбрать другой словарь), то можно получить удивительный результат. Берем вектор слова King, вычитаем из него вектор слова Man и добавляем вектор слова Woman. Декодируем получившийся вектор обратно в слово. Получаем Queen! И таких примеров в интернете куча.
Однако, если попробуете сделать по схеме, описанной мной выше, нифига не получится! Потому что для добавления векторам смысла необходимо закодировать в них контекст!
Контекст
Контекст -- это набор токенов, которые встречаются в текстах рядышком с нашим. Мы берем окно размером, например, пять токенов. Накладываем это окно на случайный участок текста. Получаем контекст. Теперь возьмем наш токен (пусть будет последним, пятым в окне) -- его нужно научиться предсказывать по контексту, это таргет. Возьмем оставшиеся четыре токена -- это вход. Их нужно как-то скормить нейросети. Но пока мы умеем подавать на вход только один токен! Что же делать?
А давайте возьмём нашу табличку эмбеддингов. Но теперь возьмем не одну, а четыре такие таблички! Для каждого токена своя табличка. Теперь скажем, что для первого токена в контексте будет использоваться первая табличка, для второго -- вторая и так далее.
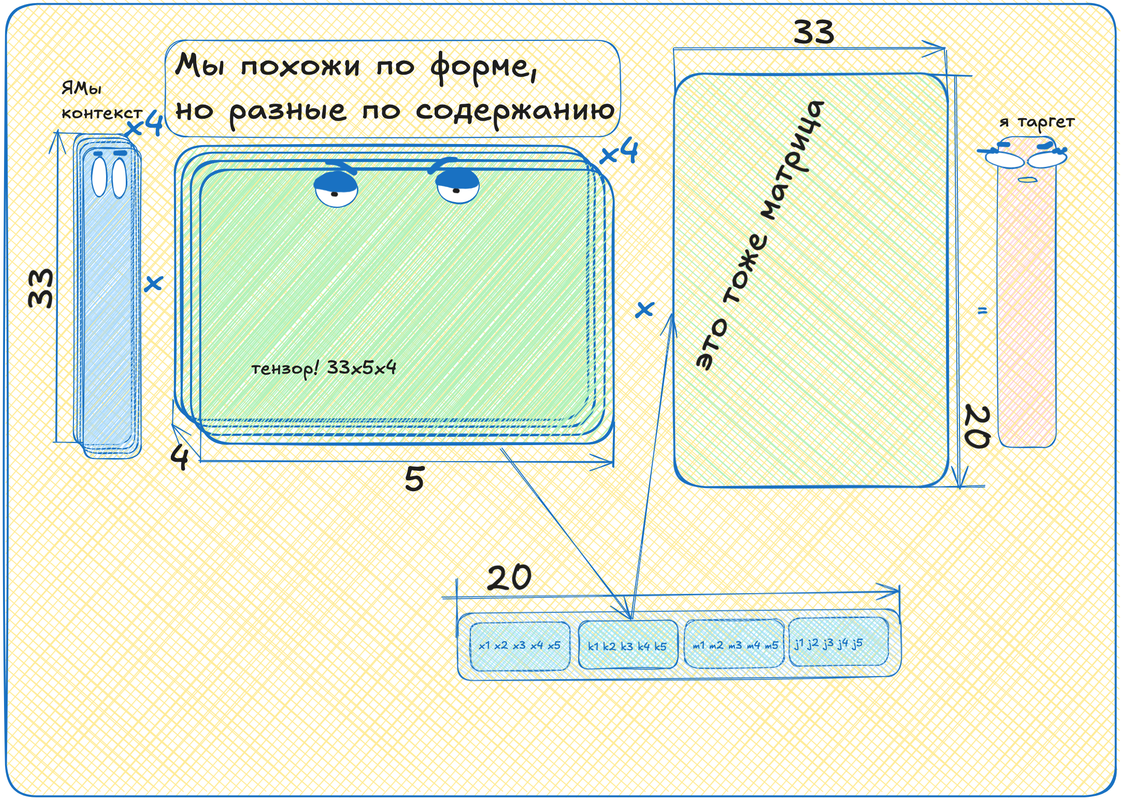
Если сложить эти таблички в стопку, то получится тензор! В нашем случае это будет такая трехмерная "матрица" размером 33 (размер алфавита) на 5 (размерность "смыслового" пространства) на 4 (сколько токенов на входе).
Это всё круто, конечно, но теперь у нас четыре вектора после умножения входа на тензор, а нам нужен один -- кодирующий таргетный токен! Что ж, давайте мы эти четыре вектора просто поставим друг на друга. Было четыре вектора длины пять, а стал один вектор длины двадцать! Тогда вторая матрица должна быть уже не 5 на 33, а 20 на 33, чтобы перевести наш длинный вектор в нужную размерность.
Теперь, если вы такую хитрую конструкцию из т
ензоров, векторов и матриц станете учить:
- закодируете четыре токена
- подадите на вход сети
- там умножите их на тензор
- склеите результаты в один вектор
- который умножите еще на матрицу
- декодируете получившийся вектор в токен
- сравните результат с пятым токеном из контекста
- посчитаете градиент от разницы
- сдвинете веса матрицы вдоль градиента
- повторите кучу раз
Вот после такого обучения ваши эмбеддинги действительно начнут кодировать смыслы и творить чудеса линейной алгебры! Такая штука, кстати, называется word2vec. Чтобы чуть лучше понять, что это и как, рекомендую посмотреть вот это видео:
Мы уже разобрались с тем, что такое нейросеть, эмбеддинг, контекст, как кодировать и декодировать тексты и контекст, как обучать нейросеть. Давайте теперь попробуем выучить согласование токенов между собой в тексте.
Например, прилагательное будет иметь разные окончания в зависимости от рода существительного, а сам смысл существительного может зависеть от наречия перед ним. Кроме того, во многих языках порядок слов в предложении определяет, где там подлежащее, сказуемое, объект и субъект, а артикли могут подсказывать число и род.
Кодируем порядок токенов
До этого момента мы с вами кодировали только состав контекста. Теперь ясно, что порядок токенов тоже несет полезную информацию. Закодировать его достаточно просто. Берем эмбеддигновую таблицу для наших контекстов, размерности AxCxB (A -- размер алфавита, C -- размер контекста). Создаём такую же таблицу, но в размерности CxB. Считаем, что вторая таблица хранит вектора, кодирующие место токена в контексте.
Складываем эти таблицы вместе (для каждого A добавляем одну и ту же позиционную таблицу) -- получаем эмбеддинг, в котором и сами токены и их положение в контексте. Дальше мы будем работать именно с этими эмбеддингами. Более подробно можно посмотреть вот в этом кусочке видео:
Собираем аттеншен
Query
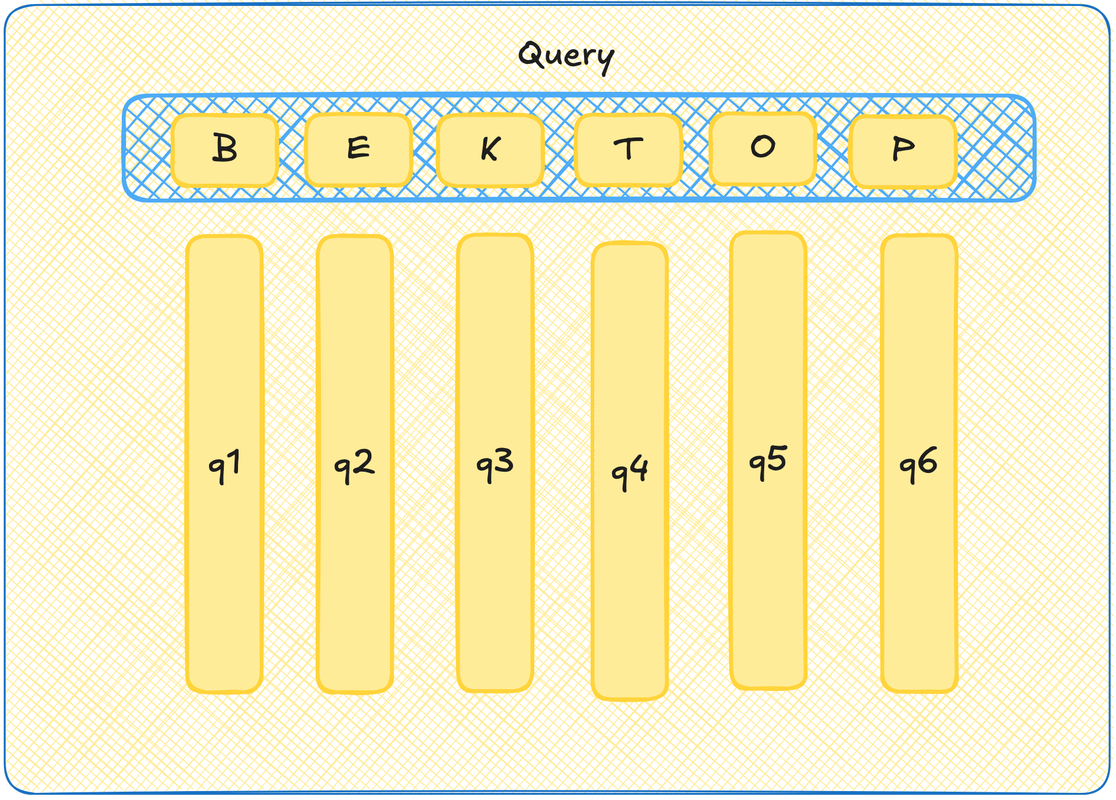
Давайте представим, что каждый токен из нашего контекста отправляет вопрос во вселенную. Например, а есть ли в контексте молодые спортивные прилагательные с зависимостью от курения и любовью к античным текстам? На самом деле, мы, как обычно, не знаем, что там за вопрос, мы вообще всё случайными числами заполняем, но пусть для примера сойдет. Вот у каждого токена тогда пусть будет вектор-вопрос -- query.
Чтобы было красиво и видеокарточно, давайте еще скажем, что на самом деле есть матрица Query, при умножении ембеддинга токена на которую, мы получим вот этот вектор вопрос. Тогда все вектора вопросы хранятся в матрице Query, а чтобы получить любой из них, достаточно взять эмбеддинг токена и с этой матрицей перемножить.
Key
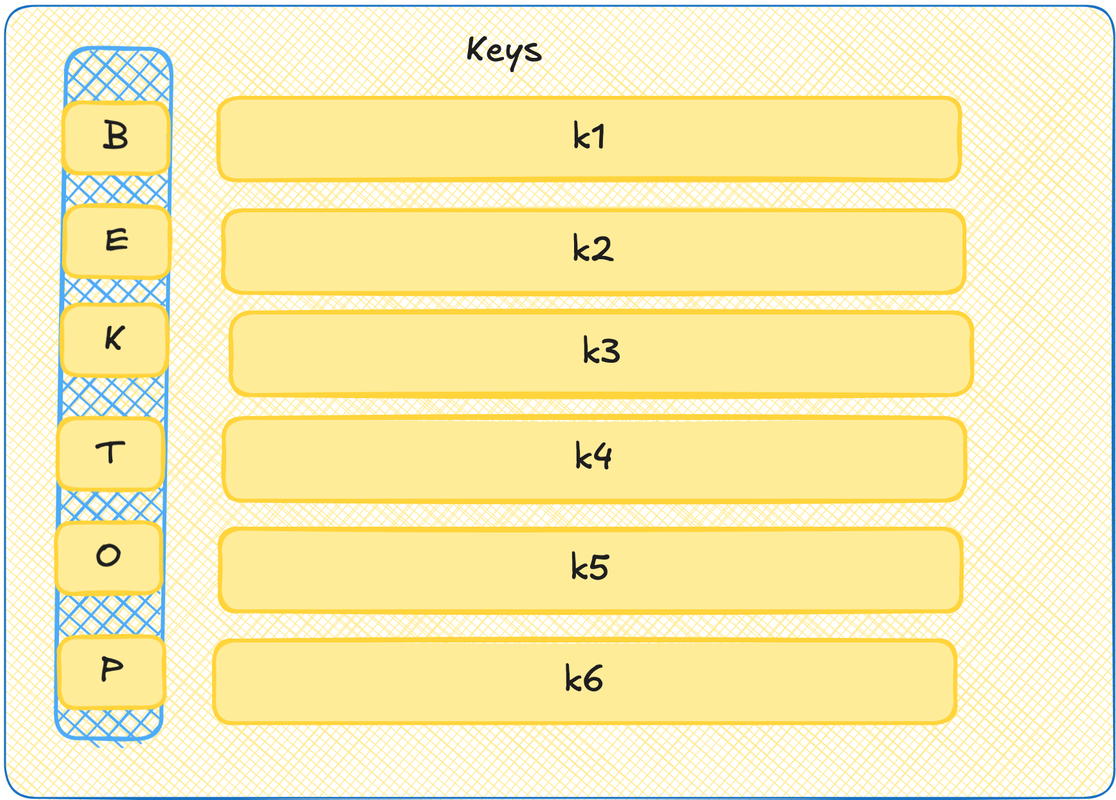
Теперь давайте представим ещё, что каждый токен умеет рассказывать о себе. Ну то есть вот если query выше -- это поиск по анкетам на сайте знакомств, то тут у нас будут сами анкеты. Давайте тоже скажем, что это такие векторы. И давайте эти векторы тоже закодируем в матрице. Такая матрица будет называться Key.
А теперь давайте мэтчить! Если query это вектор, и key это вектор, то можно их перемножить скалярно и узнать степень их сонаправленности. Получается, подбираем наиболее подходящие пары!
Value
Это круто, что мы нашли самых подходящих, но что с этим теперь делать? Теперь мы хотим поменять наш изначальный эмбеддинг! Мы хотим повернуть вектор нашего токена в "смысловом" пространстве так, чтобы он лучше соответствовал контексту, в котором находится. Повернуть вектор можно добавив к нему другой вектор в том же пространстве. С помощью Query x Key мы определили, какие токены влияют на текущий сильно, а какие слабее. То есть длины этих добавочных векторов нам уже ясны. А вот чтобы задать их направления мы возьмем ещё одну матрицу - Value. Она также поставит в соответствие каждому токену из контекста вектор.
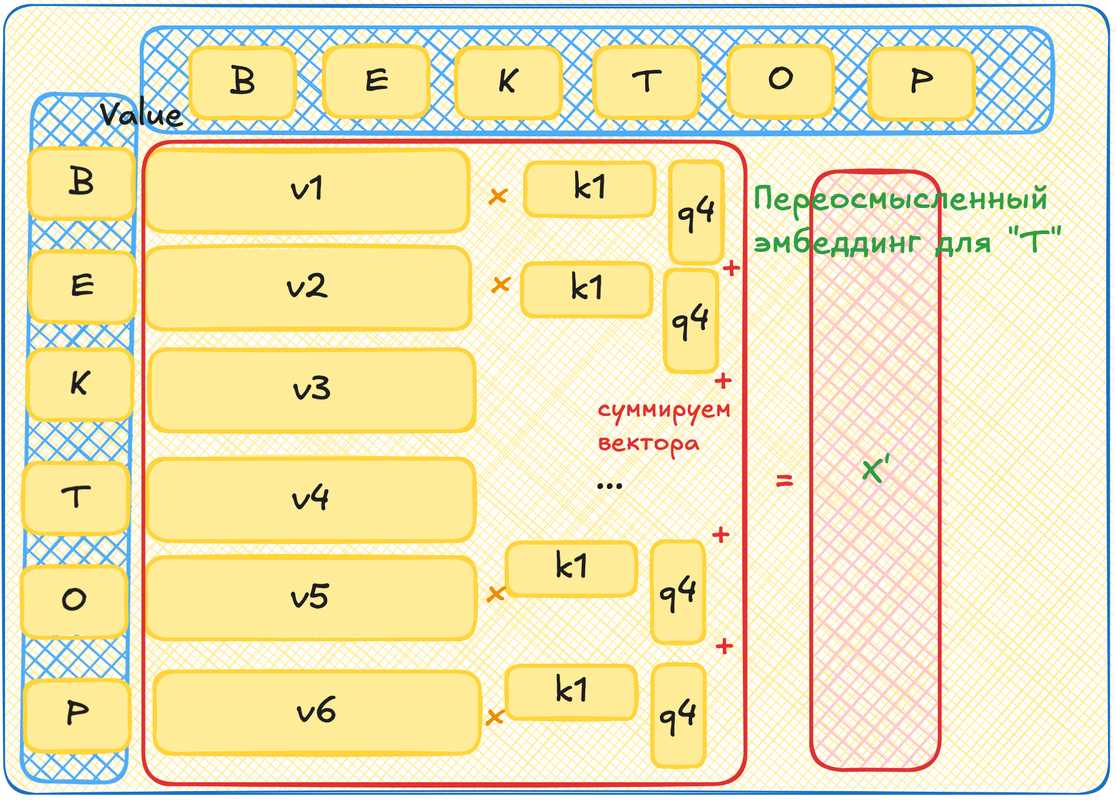
Теперь мы выбираем любой токен из контекста. Генерим для него query вектор. Для всех остальных генерим key вектора и value вектора. Умножаем query на key. Теперь для каждого value вектора умножаем его на получившееся произведение. Теперь складываем все эти вектора, мы можем, они в одном пространстве. Это получился вектор, на который нужно повернуть эмбеддинг нашего первого токена, чтобы он учел окружающий его контекст.
Multi-head attention
Этот механизм и называется голова аттеншена. А теперь, если мы для каждого слова сгенерируем по несколько таких "анкет" query, key и value, то сможем зацепить повороты в разных пространствах! То есть сможем учесть больше разных смыслов. У нас будет профиль не только по тиндеру, но и по линкедин. Использование сразу нескольких наборов таких матриц (с учетом магии линейной алгебры для более эффективных вычислений) называется многоголовым аттеншеном.
Гораздо понятнее станет, если посмотреть вот это видео в с красивыми картинками:
Feed Forward
Значит, повернули мы ембеддинги в самые правильные места, казалось бы, всё! Но не так быстро! Я, честно, не очень понимаю, зачем нужен конкретно вот этот кусок в трансформере. Мои ожидания были, что он никакого качества не добавит. И он (по чистому совпадению) в видео Андрея нифига и не добавил (или добавил, но я запомнил иначе!). Однако, Андрей объясняет, что после аттеншена слова узнали что-то про соседей, но полученную информацию ещё не переварили. Вот, чтобы её как-то обратботать, нужен еще один просто Multi-Layer Perceptron из первой части поста. Он и называется Feed Forward. Про него эпизод здесь:
Add & Norm
Add
Вот мы эмбеддинги наши повернули куда-то. Потом ещё поворачивать будем. Так можно далеко уехать! Поэтому мы возьмём эмбеддинги до аттеншена и прибавим к эмбеддингам после аттеншена. Если задуматься, то у нас был для токена вектор X. Мы к нему добавили аттеншен, какой-то ΔX. А теперь снова добавляем изначальный X. То есть мы как бы удваиваем силу изначального направления вектора! X' = X + ΔX + X = 2X + ΔX
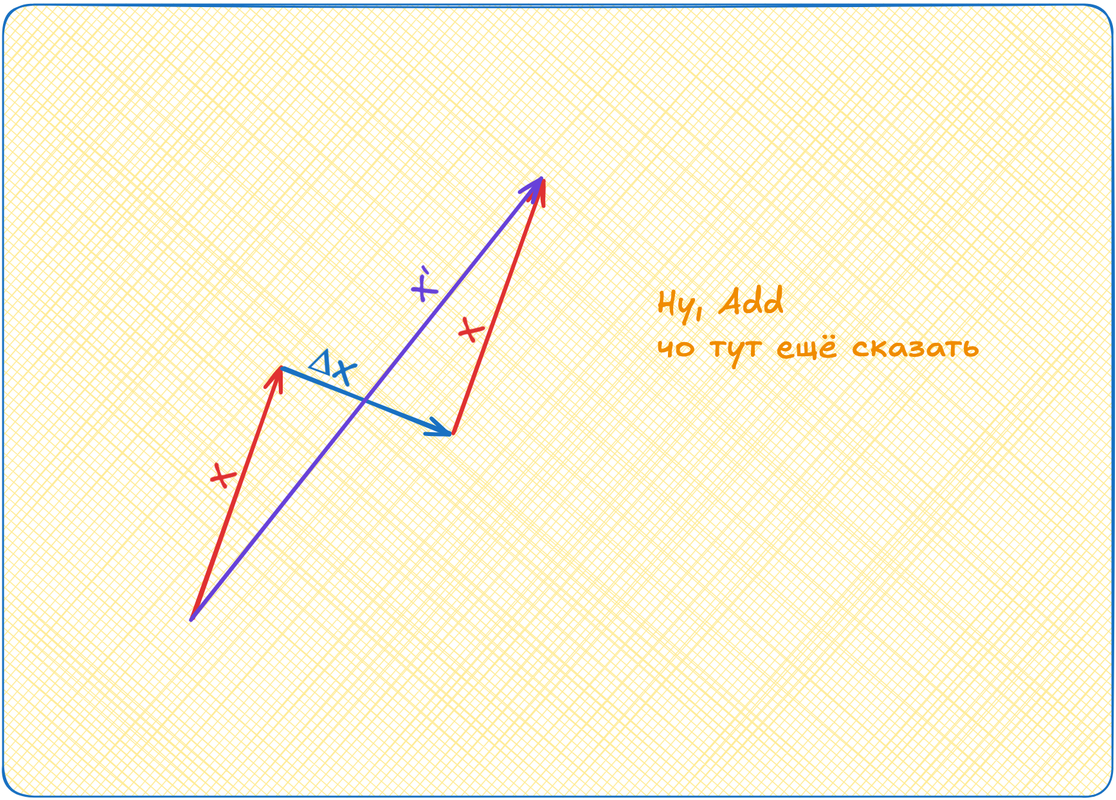
Эта штука добавляет стабильности работе модели и называется Add.
Norm
Кто позвал Осетинскую? Показалось!
Так вот, параметры разъезжаются, числа достигают девятизначных значений и всё такое. Поэтому добавляют этап layer norm. Это процедура, когда мы берем выходы слоя нейросети и делаем трансформацию значений в нём так, чтобы среднее стало ноль, а дисперсия один. Андрей ещё говорит, что Norm сейчас принято делать перед аттеншен, перед фид форвард и т.д., а не после, как на картинке выше.
Повторить всё сто тыщ мильонов раз
Повторяем блок Attention -> Feed Forward, Add&Norm между ними -- кучу раз. Радуемся, что обучение находит в наших случайно инициализированных матрицах разные оптимумы. Жжём процессорное время видеокарт.
Делаем из Т9 бота-ассистента
Fine tuning
Всё, что я описывал тут три части подряд -- это претрейн! Мы с вами обучили очень крутой, очень тяжелый и медленный Т9. Наша модель сейчас умеет прогнозировать продолжение любого текста на основе того, что сама модель когда-либо видела.
Чтобы превратить её в чатбот-ассистента, нужно теперь тренировать её на данных в формате вопрос-ответ. На большом количестве данных. Её ведь надо переучить с рандомных форматов из интернета, на формат форума или стековерфлоу.
Но этого мало! Скорее всего качество ответов будет так себе! Поэтому мы нанимаем ML-тренеров, которые составляют размеченную базу вопросов-ответов, в которой качество ответов оценено. Этих данных мало и они дорогие. Поэтому на них мы обучим небольшую модель классификации. Она будет смотреть на вопрос и ответ, а выдавать некоторый штраф или поощрение, в зависимости от качества ответа.
С помощью этой небольшой модели нужно доучить нашу большую модель отвечать хорошо.
Но и этого ещё не достаточно! Нужно же всё зацензурировать! Для этого мы возьмем еще модель, которая будет оценивать соответствие ответа правилам. Для этой модели мы задаим правила и еще сделаем тоже модель поощрений и штрафов. Примерно где-то здесь живет этот ваш AI alignment!
Retrieval‑Augmented Generation
Наконец, самое вкусное, что можно добавить своему ассистенту это RAG. Это по-сути база данных с интернетом, в которую может ходить модель. Модель обучается валидировать свои ответы об такую базу, а в выдаче пользователю подкреплять ответы ссылками на эти ресурсы. Типа как нейропоиск у Яндекса. Но тут я уже совсем больше ничего не знаю, поэтому пора закругляться.
Спасибо, что были с нами все эти много букв!