Как развивались современные LLM: от рекуррентных нейронных сетей до механизма внимания
БиомолекулаЧтобы разобраться, как работают современные языковые модели, обсудим различия между изображениями и текстами и посмотрим на эту разницу с точки зрения человеческого восприятия. Изображения мы видим сразу целиком: что происходит в центре, справа и слева. Текст же, особенно на слух, мы воспринимаем последовательно — слово за словом. Ученые решили воспользоваться этим свойством для более эффективной обработки языка и стали применять специальные модели для работы с последовательностями — рекуррентные нейронные сети, или RNN.
Идея до элегантности простая. Раз мы воспринимаем речь слово за словом, давайте и входные данные для языковой модели передавать последовательно. При этом мы не будем «забывать» все уже обработанные слова, а, как и наш мозг, будем хранить в модели всю уже считанную информацию. Для этого на каждом шаге модель получает в качестве входных данных два объекта: новое слово и «историю», или совокупное представление о всех предыдущих словах. Схематичная работа RNN показана на схеме ниже.
Главная проблема RNN — забывание контекста. Чем дальше слова находятся друг от друга, тем меньший контекстный вклад они вносят — и это приводит к ошибкам. Например, в предложении «Мяч уплывал все дальше и дальше, и, несмотря на все усилия, Таня никак не могла его догнать», слово «его» однозначно относится к объекту «мяч». Но, так как эти слова разделяет больше десяти других слов, из-за забывания контекста простая RNN такую связь не уловит. Справиться с этой проблемой позволяют более сложные версии рекуррентных сетей — например, модель с долгой краткосрочной памятью (LSTM; рисунок ниже).
1. Пример работы RNN, обрабатывающей слова одно за другим. Изначально о тексте ничего не известно, то есть контекст отсутствует. После обработки первого слова у модели уже появляется «история», и эмбеддинг второго слова рассчитывается с ее учетом. Процесс многократно повторяется до конца предложения — и в этот момент модель уже практически потеряет информацию о его начале. Если бы в следующем предложении мы хотели спросить у модели, поет ли в саду соловей или ворона, модель не смогла бы ответить, потому что она уже забыла про контекст «красивого пения».
2. Пример работы LSTM, в которую добавлен вектор контекста и возможность ограничивать влияние текущего слова на контекст, а контекста — на слово. Такой механизм позволяет находить связи между словами на довольно большом расстоянии. Поэтому в эмбеддинге слова «птица» накопится больше информации о том, что она пела красиво, а в эмбеддинге контекста сохранится вся важная информация о нашем предложении.
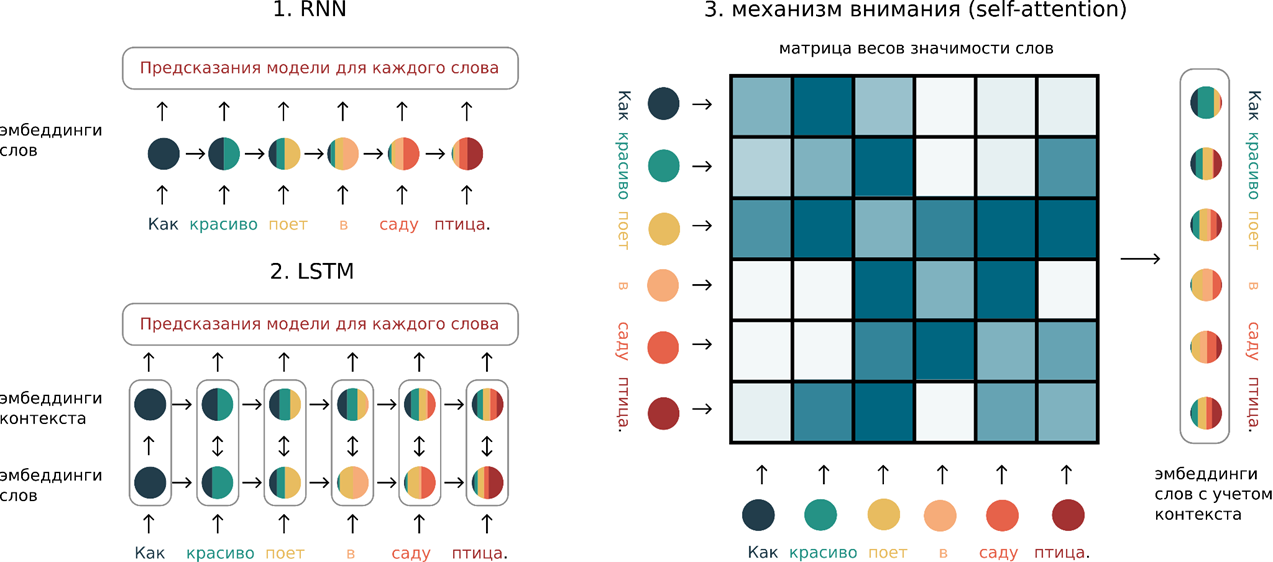
3. Пример работы простейшего блока «внимания» (self-attention). Чтобы параллельно обрабатывать разные слова из текста, необходимо эффективно учитывать контекст и влияние слов друг на друга. Перебор «в лоб» здесь не подойдет: мы захлебнемся от избытка информации. Блок внимания сравнивает исходные эмбеддинги слов друг с другом и предсказывает значимость каждого слова в контексте других. Это изображает матрица весов значимости слов: чем ярче цвет ячейки, тем важнее слово из столбца для слова из строки. С помощью этой матрицы и рассчитываются финальные эмбеддинги слов с учетом контекста. Возможности одного блока внимания не безграничны: в тексте, где переплетены разные смыслы на разных уровнях выразительности языка, такой блок сможет уловить лишь малую толику контекста. Поэтому в современных трансформерах используют множество параллельных блоков внимания, а чтобы учесть еще и порядок слов, информацию об нем прямо добавляют в эмбеддинг.
Одна из проблем RNN и LSTM — это передача информации о контексте только в одном направлении (от первого слова к последнему). Справиться с этим просто — можно использовать модель одновременно в двух направлениях. Комбинация прямого и обратного эмбеддингов слов учитывает контекст слова с обеих сторон, поэтому такие двунаправленные RNN фиксируют все важные взаимосвязи в предложении. Обучают RNN, кстати, тоже последовательно.
Применяют RNN, например, для задачи классификации текстов (ее постоянно решает ваш email-клиент, решая, какие письма отправить в папку со спамом, а какие нет): текст прогоняется через блок RNN, а эмбеддинг последнего слова, учитывающий весь контекст целиком, используется другой нейронной сетью для предсказания класса. Если оно не совпадает с реальностью, параметры каждого рекуррентного блока обновляются так, чтобы минимизировать ошибки.
Подобное обучение требует заранее размеченной обучающей выборки, однако подготовить ее бывает трудно. Обойти эту проблему помогает обучение без учителя (см. глоссарий к первой статье спецпроекта “Искусственный интеллект в биологии”) или обучение на неаннотированных данных, которых у нас в разы больше. В случае RNN модель обучают угадывать следующее слово по уже обработанным предыдущим. Этот подход очень напоминает работу нашего мозга: наверняка вы замечали, что иногда в разговоре можете угадать, что дальше скажет ваш собеседник. Чтобы правильно предсказать следующее слово, модель должна выучить правила формирования текстов и научиться кодировать всю содержащуюся в них важную информацию в эмбеддингах.
Последовательная работа RNN, хоть и является красивой аналогией человеческому восприятию, одновременно является и главной проблемой данной архитектуры. Посчитать эмбеддинг слова не получится, не обработав все предыдущие слова в тексте (а в случае двунаправленных RNN — еще и все последующие). Из-за этого модель никогда не сможет использовать всю мощь параллельных вычислений современных суперкомпьютеров.
Справиться с этой проблемой помогла концепция внимания — а точнее, один из ее подвидов под названием self-attention, который стал широко использоваться после выхода статьи Attention is all you need. Механизм внимания — центральный для архитектуры трансформеров, а именно она лежит в основе BERT, ChatGPT и многих других больших языковых моделей. Схематично его работа изображена на схеме выше. В отличие от рекуррентных нейросетей, внимание позволяет посчитать учитывающие контекст эмбеддинги одновременно для всех слов. Благодаря этому трансформеры можно обучать на многопроцессорных системах, что в наше время не просто актуально, а необходимо.
Трансформеры можно обучать так же, как и RNN, но можно пойти еще дальше, заставляя восстанавливать скрытые или намеренно испорченные участки текста. Именно так обучали многие белковые языковые модели, о которых мы подробно расскажем в следующей главе .
Впрочем, оказалось, что для некоторых задач предсказание исключительно следующего слова работает лучше. Этот принцип называется авторегрессией, и на нем основаны многие генеративные модели — например, архитектура GPT, на которой работает тот самый чат-бот.
Мы надеемся, что наше сильно упрощенное объяснение архитектур RNN и трансформеров позволит читателю понять базовые идеи, которые стоят за этими моделями. Во второй статье спецпроекта “Искусственный интеллект в биологии” мы подробно рассказываем о том, как и какие языковые модели внедряются в биологию и помогают нам работать с данными.