Как работает машинное обучение?
rafanalyticsЛюдей постоянно волнует вопрос "А что будет завтра?", ведь имея возможность прогнозировать будущее мы бы могли:
- знать, когда нужно закупить и продать валюту, а значит мы можем легко разбогатеть 🤑
- понимать, где произойдёт следующее землетрясение/наводнение, а значит могли бы спасти человеческие жизни 🤕
- не совершать глупых ошибок сегодня, чтобы изменить свою судьбу в лучшую сторону 🙏
- и сделать ещё много чего полезного...
Причём интересно отметить, что если бы мы имели информацию обо всём, что происходит в мире на данный момент (т.е. буквально знали положение каждого атома, а также скорость и направление его движения в текущую секунду), то мы бы могли очень точно предсказать будущее по формулам. Именно поэтому, кстати, качественную информацию можно считать самым дорогим ресурсом 21-го века.
Увы, у нас просто нет такого огромного объёма информации обо всём, да и вычислительные ресурсы не были бы способны работать с таким объёмом данных. Поэтому люди научились добывать самые важные и доступные данные, а затем научили компьютеры предсказывать по этим данным интересующее их значение - всё это получило название "машинное обучение" или же "искусственный интеллект" (в более широких кругах).
Немного математики
А давай представим, что ты продаёшь квартиру и хочешь получить за неё как можно больше денег. Но ты не знаешь, какую оптимальную цену стоило бы выставить за эту квартиру, а значит есть риск:
- риск поставить слишком высокую цену и не получить предложений;
- риск поставить слишком низкую цену, продать и жалеть об упущенных деньгах.
Но тут ты вспоминаешь, что есть такая чудесная сфера, как Data Science, и начинаешь анализировать данные о продажах квартир с Авито, Циана и других доступных сайтов...
Затем ты выделяешь самые важные данные об этих продажах. Например, площадь квартиры, количество комнат, расстояние до центра города и так далее. Все эти параметры принято называть признаками или фичами (от англ. feature). Имея такие данные, мы бы могли попытаться установить искомую зависимость между признаками и оптимальной ценой продажи квартиры, которую мы пытаемся спрогнозировать. К слову, величину, которую мы пытаемся спрогнозировать, принято называть целевой переменной или таргетом (от англ. target). Давай обозначим все имеющиеся у нас признаки как X1, X2, X3,..., Xn, а целевую переменную, т.е. оптимальную стоимость квартиры, обозначим как Y. Тогда вся наша задача заключается в том, чтобы найти такую функцию, что f(X1, X2, X3,..., Xn) = Y
Но теперь вспомним, что у нас нет абсолютно всех данных о квартире, поэтому мы можем лишь попытаться максимально точно предсказывать значение оптимальной цены квартиры. Таким образом, мы хотим, чтобы ошибка нашей модели (моделью можно называть ту самую функцию) была минимальна. Тогда мы можем задать какую-нибудь функцию ошибки. Например, это может быть модуль разности нашего прогноза и фактического значения. Записываться такая функция будет примерно так:
error(X1, X2, X3,..., Xn, Y) = | f(X1, X2, X3,..., Xn) - Y |
И вот такую вот функцию потерь мы хотим минимизировать, т.е. мы буквально хотим добиться, чтобы разность между прогнозами нашей модели и фактическими значениями была минимальна - именно это и значит, что наша модель ошибается совсем незначительно.
А теперь вспомни: как можно найти минимум у функции?
Ответ: производные! Если ты не забивал на математику в 11 классе, то ты знаешь, что вычислив производные для функции мы можем понять, в какую сторону в конкретно данной точке функция растёт сильнее всего. Но так как мы хотим найти минимум у нашей функции ошибок, то мы можем взять противоположное направление - именно оно будет соответствовать направлению самого быстрого падения значения функции ошибки.
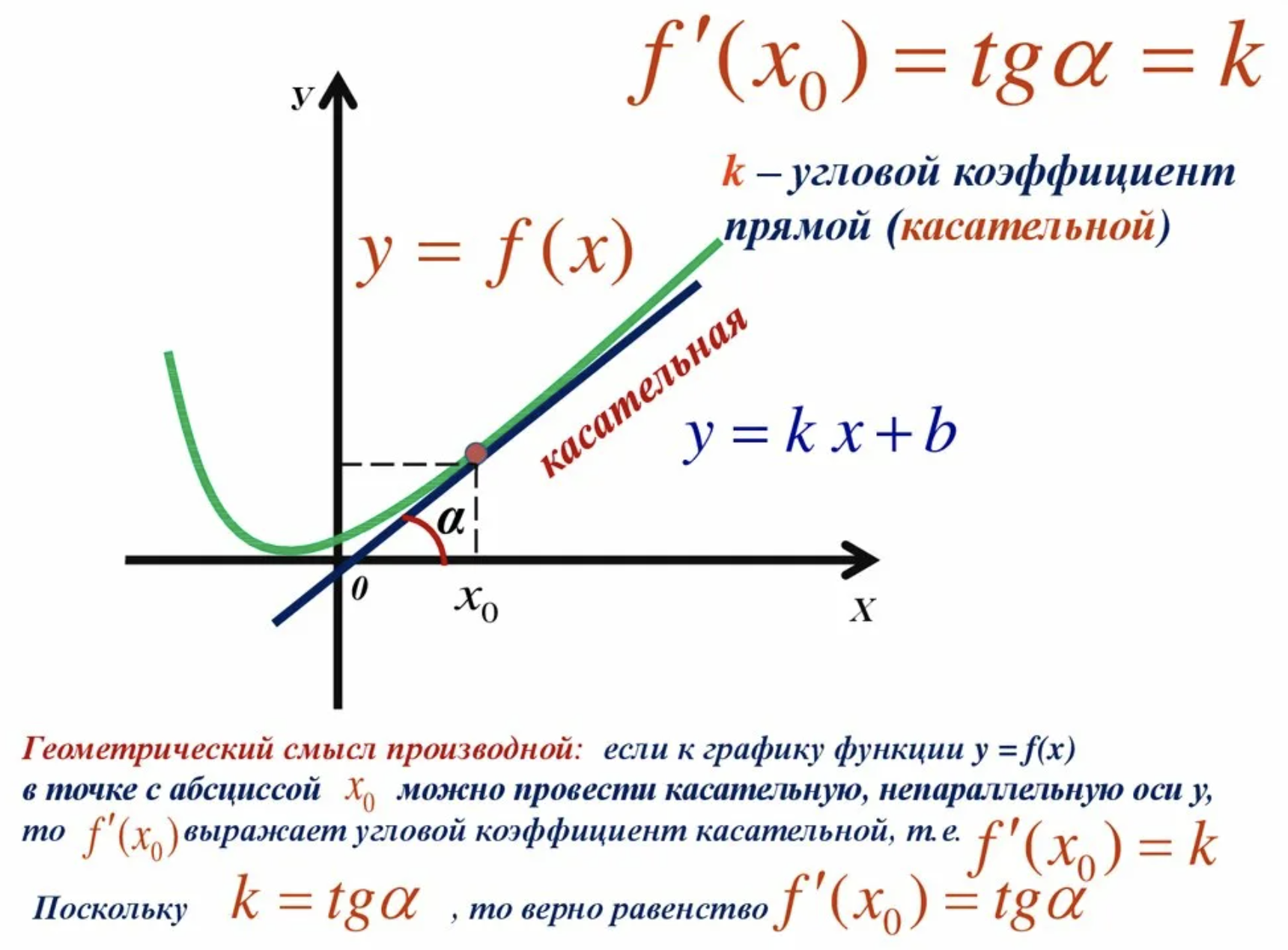
Вот такими маленькими "шагами" на каждом этапе мы можем как будто "спускаться" по функции ошибки вниз, пока не дойдём до какого-нибудь минимума функции. А в этом минимуме мы уже можем восстановить и саму функцию f(x) - это будет значить, что мы подобрали такую функцию f(x), которая ошибается меньше всего.
Таким образом, имея данные признаки и значения целевой переменной, мы можем попытаться выявить зависимость между этими фичами и таргетами. И самое крутое, что так мы можем восстановить самые неочевидные зависимости. Например, в качестве признаков могут быть цвета пикселей изображения, а в качестве предсказываемой переменной - количество собачек на этом изображении (это уже пример задачи из компьютерного зрения).
Конечно, в этой статье я опустил очень много важных моментов, но цель этой статьи в другом: я хочу вдохновить тебя машинным обучением и показать, что все формулки, которым ты возмущался(-лась) в школе, нашли применение в самой передовой технологии, благодаря которой Chat-GPT отвечает на твои вопросы, а FaceID распознаёт твоё чудесное личико 😘
Не забудь поделиться статьей с друзьями - пусть они тоже развиваются! :)