Как пропатчить LLVM за один день с видимым перформансом
Danila KuteninПрошло достаточно много времени, статья про асинхронное программирование у меня не удалась -- она получилась слишком сложной. Это связано с тем, что у меня нет очень большого опыта работы в этом в C++, поэтому простыми и понятными словами объяснить не получилось. Оставлю немного на потом. Также я был занят разработкой и (о божечки) написанием статьи по нашей файловой системе в Google. Драфт статьи про файловую систему общего назначения с миллиардами файлов для сотни тысяч людей с доступом по всему миру за миллисекунды уже готов, мы будем её полировать (и допиливать фичи) и подаваться на OSDI или что-то похожее. Хотим посмотреть на реакцию людей, вдруг это то, что людям прям не хватает. И если реакция будет бурной, не исключено, что и покажем что-то миру. Stay tuned.
LLVM в народе является хорошим проектом для достаточно продвинутой аудитории компиляторостроения. Я бы даже сказал, что LLVM уже сейчас лидер, потому что в нём очень много хороших оптимизаций, правильной расширяемой архитектуры, много тулинга типа санитайзеров, clang-tidy, AST parsers. Может быть, для некоторых проектов сейчас GCC всё ещё быстрее, но я думаю, что это вопрос времени и конкуренции, у меня был и тот и тот опыт и я скажу, что Clang и LLVM сейчас намного приятнее пользоваться. GCC тоже работает неплохо, особенно они очень хорошо поработали в последнем релизе над показом ошибок.
Я буду использовать Clang и LLVM эквивалентно в этой заметке.
LLVM состоит из трёх частей: frontend, optimizer, backend.
Если попытаться объяснить картинкой, то выглядеть это будет так:
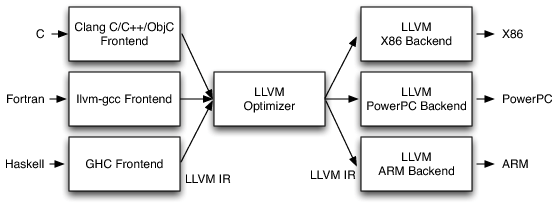
То есть, если вы хотите написать свой язык программирования, просто напишите ковертацию в LLVM IR, а дальше получите свой оптимизированный assembler. Но не всё так просто :)
Frontend
Frontend в LLVM состоит из парсинга и семантики верхнеуровеного языка в так называемое Intermediate Representation (IR). Часто эта задача является очень сложной, так как задействованы в огромном количестве всякие нюансы, как написать функции в IR. IR является аналогом ассемблера, но с некоторыми очень важными математическими инвариантами. О них чуть позже.
Самым важным на этом этапе является понятие AST (Abstract Syntax Tree).
На уровне Frontend LLVM пытается построить AST (у всех популярных языков типа C/C++, Rust и т.д), происходит диагностика ошибок языка, можно делать всякие прикольные вещи типа рефакторингов и замены одной функции на другую (например, замены функции Get у определённого одного класса, когда обычные sed и grep не помогут).
Рассмотрим пример какого-нибудь AST C++ кода.
class A {
public:
A() { a = 1; }
~A() { a = 0; }
private:
int a = 0;
};
using B = A;
Это превращается в
TranslationUnitDecl |-CXXRecordDecl <line:1:1, line:7:1> line:1:7 referenced class A definition | |-DefinitionData standard_layout has_user_declared_ctor can_const_default_init | | |-DefaultConstructor exists non_trivial user_provided defaulted_is_constexpr | | |-CopyConstructor simple trivial has_const_param needs_implicit implicit_has_const_param | | |-MoveConstructor | | |-CopyAssignment trivial has_const_param needs_implicit implicit_has_const_param | | |-MoveAssignment | | `-Destructor non_trivial user_declared | |-CXXRecordDecl <col:1, col:7> col:7 implicit referenced class A | |-AccessSpecDecl <line:2:1, col:7> col:1 public | |-CXXConstructorDecl <line:3:5, col:17> col:5 A 'void ()' | | |-CXXCtorInitializer Field 0x556ce3533ee0 'a' 'int' | | | `-CXXDefaultInitExpr <col:5> 'int' | | `-CompoundStmt <col:9, col:17> | | `-BinaryOperator <col:11, col:15> 'int' lvalue '=' | | |-MemberExpr <col:11> 'int' lvalue ->a 0x556ce3533ee0 | | | `-CXXThisExpr <col:11> 'A *' implicit this | | `-IntegerLiteral <col:15> 'int' 1 | |-CXXDestructorDecl <line:4:5, col:19> col:5 ~A 'void () noexcept' | | `-CompoundStmt <col:10, col:19> | | `-BinaryOperator <col:12, col:16> 'int' lvalue '=' | | |-MemberExpr <col:12> 'int' lvalue ->a 0x556ce3533ee0 | | | `-CXXThisExpr <col:12> 'A *' implicit this | | `-IntegerLiteral <col:16> 'int' 0 | |-AccessSpecDecl <line:5:1, col:8> col:1 private | `-FieldDecl <line:6:5, col:13> col:9 referenced a 'int' | `-IntegerLiteral <col:13> 'int' 0 `-TypeAliasDecl <line:9:1, col:11> col:7 B 'A' `-RecordType 'A' `-CXXRecord 'A'
Получается достаточно много, но очень выразительно. Поиграться можно, например, тут. Читая AST, можно хорошо узнать, как действительно работает C++ и делать рефакторинги, указывать Warning'и, например, так работает clang-tidy, clang-modernize -- строится AST, предлагается эквивалентная/лучше конструкция какие-то узлов, производится замена, если это возможно.
IR
Intermediate representation это аналог ассемблера, только лучше. IR строго типизирован, имеет полную документацию (1700 страниц примерно всё занимает, на сайте облегчённая версия) и имеет несколько инвариантов. Давайте посмотрим какой-нибудь пример
define i32 @square_unsigned(i32 %a) {
%1 = mul i32 %a, %a
ret i32 %1
}
Каждая переменная имеет тип, каждое вхождение переменной сопровождается её типом, который определяется либо операцией mul i32, либо statement ret i32 %1. Типы бывают целочисленные любой битности i1, i8, i123, указатели на любые типы, float, double, бывают структуры вложенные друг в друга, например
%class.A = type { %struct.C, i32, %class.A* }
%struct.C = type { i8 }
Также бывают пустые структуры для совместимости с C и Rust.
Ещё бывают векторные типы, это очень хорошо вырождается в SIMD, операции применяются поточечно, переполнения происходят по two complement rule, но это уже детали.
define <4 x i32> @multiply_four(<4 x i32> %a, <4 x i32> %b) {
%1 = mul <4 x i32> %a, %b
ret <4 x i32> %1
}
Это превращается при
llc-8 A.ll -O3 -march=x86-64 -mcpu=haswell -o A.s
В
vpmulld %xmm1, %xmm0, %xmm0 retq
Поэтому часто frontend старается делать такие оптимизации, чтобы бэкенду было больше известно.
Одно важное свойство IR это то, что переменную нельзя переприсвоить -- инициализация происходит один раз. Это важно, потому что так можно доказывать инварианты, например, что если переменная ненулевая, значит она никогда не станет нулём, в отличие от верхнеуровневых языков. Это немного усложняет жизнь бэкенду, потому что в идеале в ассемблере хочется переиспользовать регистры и не сильно углубляться в стек (но в итоге в больших приложениях почти всегда приходится идти достаточно глубоко), но с таким инвариантом можно много доказывать важных вещей, как инварианты, векторизации циклов и так далее. Об этом хорошо написано в книге Драконов (которую я так и не осилил до конца прочитать), если очень интересно, почему SSA (Static Single Assignment) так важен при оптимизациях. Верхнеуровневое понимание заключается в том, что при компиляторных оптимизациях важно иметь какую-то математическую модель, с использованием которой можно доказывать, что преобразования кода корректны.
IR также используются при LTO и ThinLTO -- специальный код мёржит модули и смотрит, где можно заинлайнить, сэкономить ещё циклов, обычно оптимизации доходят до 7-8%.
Кстати, о преобразованиях.
C/C++/Rust/Go не были бы таким быстрыми, если бы не компиляторные оптимизации, которые инлайнят функции, используют свойства констант (умножение/деление на 2 это лишь правильный сдвиг на 1), собирают условия в одни, используют инварианты и прочие вещи.
Попробую показать, что компиляторы умеют хорошо, а где проблемы, которые очень сложно решать в общем случае.
Рассмотрим цикл:
for (int i = 0; i < 100; ++i) {
func(i * 1234);
}
Все компиляторы это раскрывают в
for (int iTimes1234 = 0; iTimes1234 < 100 * 1234; i += 1234) {
func(iTimes1234);
}
Они так делают, потому что умножение достаточно дорогая операция. К сожалению, это не происходит на уровне IR, а только уже на code-generation после вычисления cost model. Это связано с тем, что такая оптимизация не может сказать, дешевле ли умножение на архитектуре, чем сложение, но я думаю, что это также отчасти, потому что не доходили руки ни у кого это сделать (тут начинается философское размышление, что в optimization IR у LLVM очень мало контрибьютеров, я насчитал около 4 постоянных человек, а также несколько которые раз в месяц/два коммитят).
define dso_local void @_Z12countSetBitsv() local_unnamed_addr #0 {
br label %2 ; Пустой label. Не знаю, зачем, видимо для лучшего inline и схлопывания блоков
; <label>:1: ; preds = %2. Label для выхода из функции
ret void
; <label>:2: ; preds = %2, %0
%3 = phi i32 [ 0, %0 ], [ %5, %2 ] ; ноль, если пришли из нулевого блока и %5, если пришли из <label>2
%4 = mul nuw nsw i32 %3, 1234 ; Умножаем на 1234
tail call void @_Z4funci(i32 %4) ; Вызываем функцию
%5 = add nuw nsw i32 %3, 1 ; Добавляем единицу
%6 = icmp eq i32 %5, 100 ; Сравниванием с 100
br i1 %6, label %1, label %2 ; Прыгаем либо на метку 1, либо на 2 в зависимости от сравнения
}
Векторизация циклов
#include <vector>
int sumSquared(const std::vector<int>& v) {
int res = 0;
for (auto i : v) {
res += i * i;
}
return res;
}
Ой, да сами посмотрите, что там происходит https://gcc.godbolt.org/z/0B6Dqf
Раскрываются в огромные и страшные инструкции -- это уже происходит на уровне IR, если вы посмотрите, там много <8 x i32> типов и тд.
Одна из оптимизаций, которая меня в своё время впечатлила это loop removal. Рассмотрим следующий цикл
int sum(int count) {
int result = 0;
for (int j = 0; j < count; ++j)
result += j*j;
return result;
}
https://gcc.godbolt.org/z/_TDmNJ -- clang оптимизирует это так, что нет никакого цикла. Как мы знаем из курса матанализа, это просто формула. Также эта оптимизация делает намного больше, например, она умеет работать с любыми многочленами
int sum(int count, int k) {
int result = 0;
for (int j = 0; j < count; ++j)
result += j*j*j*j - k*j*j*j + 5*j*j - j + 7;
return result;
}
https://godbolt.org/z/WYmdUC. Как это работает? На самом деле внутри себя LLVM применяет индукцию и доказывает, что это вычислимо через формулу.
Это является конструктивным способом доказывания формул сумм многочлена одной переменной. Я не видел, чтобы этому учили даже в продвинутых университетах на курсах дискретной математики/анализа, а схема максимально крутая.
Если углубляться в детали, пусть f_0(i)-- значение переменной в цикле на итерации i, тогда попытаемся представить цепочку преобразований через каскадные функции, где j -- индекс j-й каскадной функции, а остальное понятно из формулы.
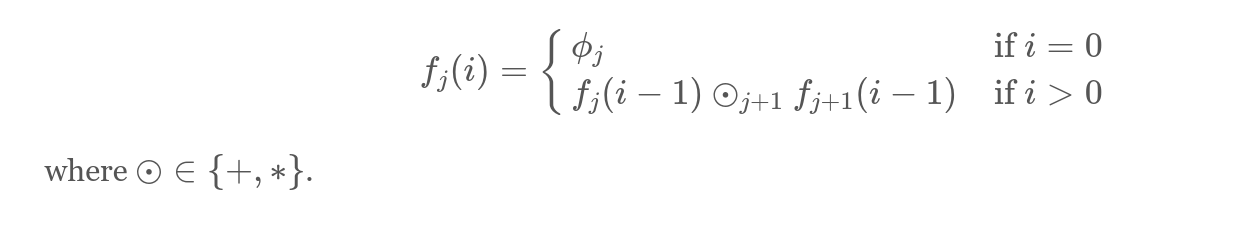
Чтобы было понятнее, приведём примеры:
Пример 1
void foo(int m, int *p) {
for (int j = 0; j < m; j++)
*p++ = j;
}
Тогда формула представима в виде
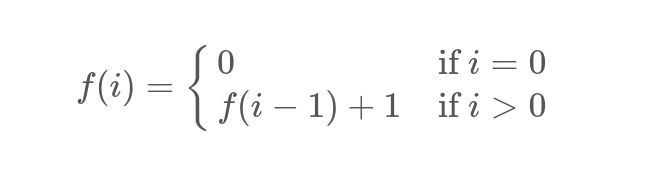
Пример 2
Рассмотрим пример посложнее
void foo(int m, int k, int *p) {
for (int j = 0; j < m; j++)
*p++ = j*j*j - 2*j*j + k*j + 7;
}
Тогда формула представима в виде:
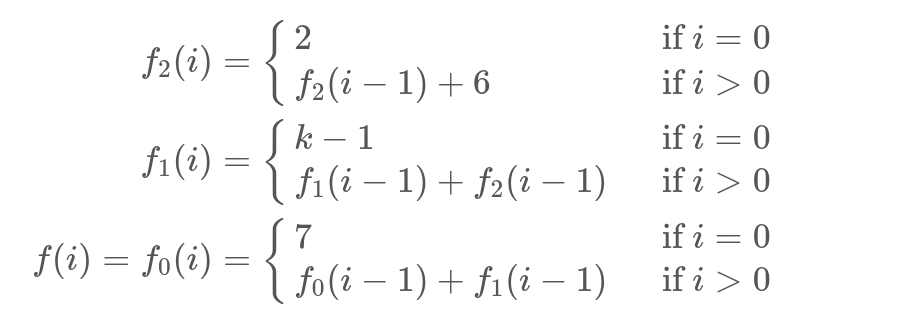
Как её найти? Мы будем писать Chain of Recurrences. К примеру, каждое из выражений записано как {constant, operator, function/constant}
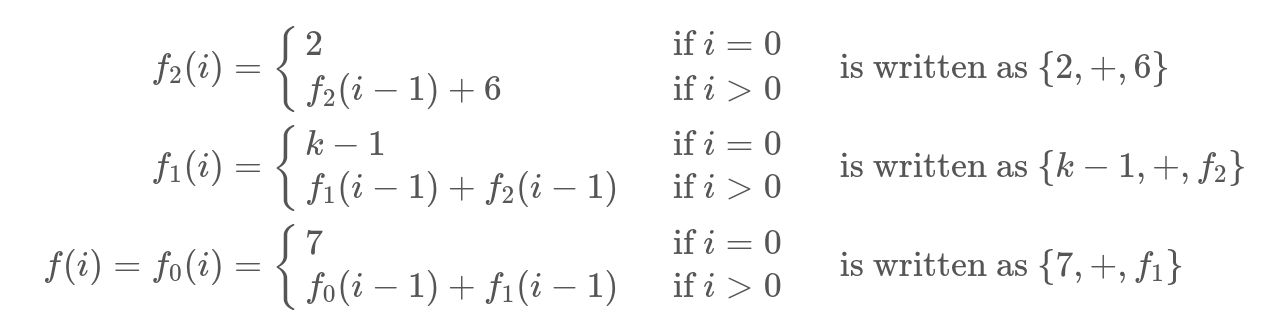
При складывании цепочки получим что-то типа {7, +, k - 1, +, 2, +, 6}
Преобразования над цепочками достаточно тривиальны:
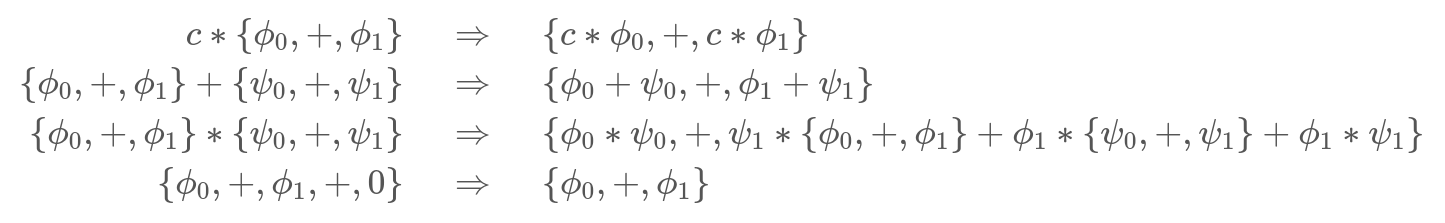
Теперь попробуем раскрыть наш полином по этим преобразованиям.
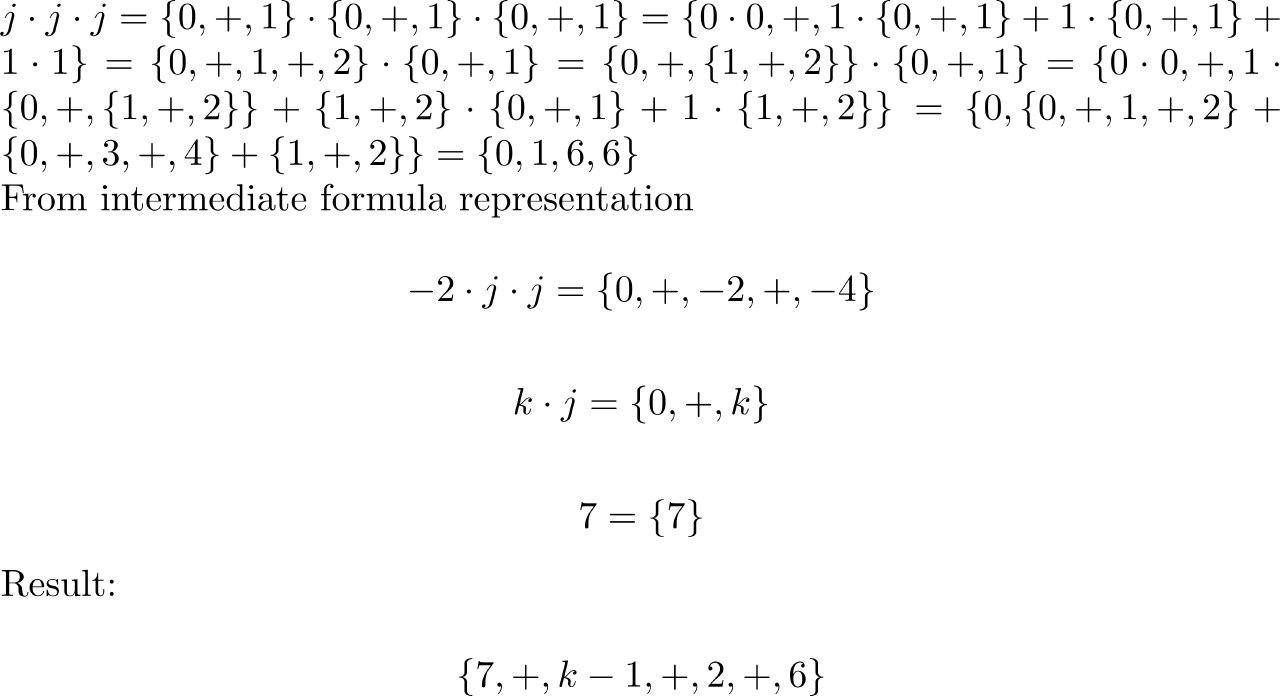
Значит это можно раскрыть в следующий код:
void foo(int m, int k, int *p)
{
int t0 = 7;
int t1 = k-1;
int t2 = 2;
for (int j = 0; j < m; j++) {
*p++ = t0;
t0 = t0 + t1;
t1 = t1 + t2;
t2 = t2 + 6;
}
}
Отлично, мы избавились от умножений в цикле! Так не всегда происходит в конечном итоге в ассемблере, потому что такие выражения сложнее векторизовать, но если CostModel инструкций поняла, что умножения очень дорогие, то может применить эту методику.
Например, сумма в сумме квадратов как раз складывается в {0, +, 0, +, 1, +, 2}(убедитесь сами, ноль в начале как раз сказывается на сумме). При добавлении j * j получится Chain of Recurrence равный {0, +, 1, +, 3, +, 2}.
LLVM IR получается таким:
define i32 @sum(i32) {
%2 = icmp sgt i32 %0, 0
br i1 %2, label %3, label %6
; <label>:3:
br label %8
; <label>:4:
%5 = phi i32 [ %12, %8 ]
br label %6
; <label>:6:
%7 = phi i32 [ 0, %1 ], [ %5, %4 ]
ret i32 %7
; <label>:8:
%9 = phi i32 [ %13, %8 ], [ 0, %3 ] ; {0,+,1}
%10 = phi i32 [ %12, %8 ], [ 0, %3 ] ; {0,+,0,+,1,+,2}
%11 = mul nsw i32 %9, %9 ; {0,+,1,+,2}
%12 = add nuw nsw i32 %11, %10 ; {0,+,1,+,3,+,2}
%13 = add nuw nsw i32 %9, 1 ; {1,+,1}
%14 = icmp slt i32 %13, %0
br i1 %14, label %8, label %4
}
Очень простая лемма (докажите по индукции, что биномиальные коэффициенты будут как раз именно такими) если у нас есть цепочка {a_1, +, a_2, +, ..., +, a_n}, то i-й элемент равен
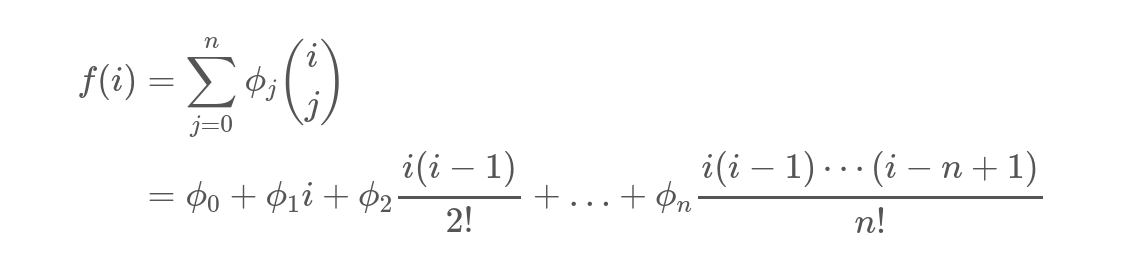
А теперь подставим сумму квадратов и получим
Именно так и стоит выводить суммы полиномов в цикле. Ну и clang решает использовать эту формулу и вообще эту методику. Я лично в восторге.
После гугления, первые такие упоминания в чистой математике этих самых цепочек я нашёл в https://bohr.wlu.ca/ezima/papers/ISSAC94_p242-bachmann.pdf , там в авторах есть и наш соотечественник.
Из самых полулярных оптимизаций являются.
- Constant folding. Если значение известно/можно за какой-то разумный лимит вычислить на этапе компиляции, то его можно подставить. Пример: https://godbolt.org/z/pc4wQf
- Constant propagation. Если есть какие-то инварианты на переменную, clang пытается их применить где возможно. Пример: https://godbolt.org/z/aGagaE
- Common subexpression elimination. Если есть дублирующийся код без side effect, то его можно убрать. Пример: https://godbolt.org/z/fBFeQj -- убрано второе разыменовывание указателя
- Dead code removal. Если можно доказать, что код никогда не будет выполнен, то проверки просто удаляются. Пример: https://godbolt.org/z/fDTwiK
- Loop invariant code movement. Показал выше. Тут, кстати, есть проблемы. А именно, если кто-то пишет код
for ()
x += sqrt(loopinvariant);
То так как sqrt изменяет errno, вынести во вне цикла нельзя, потому что sqrt не является функцией без side effect. Возможно я возьму этот проект сам, но такой код пока идиоматически не может быть соптимизирован.
6. Peephole optimizations. Компилятор смотрит на инструкции рядом и если их можно переставить удобным образом/склеить, то он их убирает. Пример: https://gcc.godbolt.org/z/aWTT9U -- используется инструкция fmadd, которая умножает и складывает одновременно, хотя в IR её нет.
Если интересно, Matt Godbolt достаточно популярно описал много оптимизаций и привёл кодогенерацию своих любимых https://queue.acm.org/detail.cfm?id=3372264.
Мораль: в LLVM порой происходят очень страшные и интересные вещи.
Как эти оптимизация применяются? Оптимизации называются на самом деле passes, каждый pass как-то трансформирует код. Дальше в зависимости от уровня оптимизаций, они применяются в определённом порядке, который зашит в коде. Это правда, что после оптимизации мы можем найти ещё какие-то оптимизации, но практика показывает, что это происходит меньше, чем в 0.1% случаев (а ускорения от этого ещё меньше), и поэтому все pass проходятся один раз.
Backend
В этом месте из оптимизированного IR представления, выходит сам ассемблер. Применяются CostModels на регистры, пытаются распихать всё по правильным регистрам, переиспользовать их, выбирать нужные инструкции под данную платформу. Эту часть я не знаю так хорошо, но возможно как-нибудь покоммичу туда, если найду упячку в выборе инструкций.
Что LLVM не может
LLVM не умеет в очень сильные инварианты, и это глобальная проблема. Если вы сортируете массив и потом складываете числа, то LLVM никогда в жизни не догадается, что массив можно не сортировать, потому что std::sort это просто функция, которая что-то делает с массивом, притом функция большая и доказать, что она сортирует все последовательности правильно сложно и невозможно в общем случае из-за проблемы останова. Поэтому в clang есть много атрибутов (атрибута сортированности нет), например вы можете написать
__attribute__((nonnull(1, 3))) int f(char* a, char* b, char* c);
То компилятор будет знать, что указатели a и c никогда не нулевые и будет пользоваться этим предположением.
Мой опыт контрибьюта
Теперь расскажу, как я стал контрибьютером в LLVM примерно за несколько часов.
Я заметил, что LLVM не всегда убирает проверки нулевых указателей после его разыменовывания, например
По C++ и LLVM LangRef если указатель разыменовывается в нулевом (стандартном) адресном пространстве, то он обязан быть ненулевым.
Почему я это заметил?
Давайте рассмотрим пример чуть более реальный. Google Code Style требует, чтобы выходные значения передавались в конце функции по указателю.
void calc(int a, int b, int* c); calc(a, b, &c); // Сразу видно, что c выходной, а и b входные параметры.
Многие функции пользуются свойством, что указатель не нулевой и спокойно его разыменовывают. А когда происходит передача указателя в другую менее агрессивную функцию (или макрос), которая проверяет, что указатель не нулевой, то проверка срабатывает и мы получаем как минимум 2 лишних инстукции, как максимум мы не удаляем мёртвый код при inline фукнции, пример: https://gcc.godbolt.org/z/PUzPL4 (GCC убирает одну проверку на нулевой указатель и в итоге генерирует меньше кода).
#include <memory>
int f(int k);
int g(int k);
int less_agressive(std::unique_ptr<int> p) {
if (p) {
return f(*p);
} else { // Мёртвый код при вызове f(p);, стоит удалить
return g(10);
}
}
int f(std::unique_ptr<int> p) {
int value = *p;
return less_agressive(std::move(p)) + value;
}
По факту, если приглядеться к IR, то вот такой код
define i32 @null_after_load(i32* %0) {
%2 = load i32, i32* %0, align 4
%3 = icmp eq i32* %0, null
%4 = select i1 %3, i32 %2, i32 1
ret i32 %4
}
Не оптимизируется до одной ret инструкции. Что ж, это очевидно недоработка и давайте попробуем её починить. В LLVM очень простое тестирование, вам главное найти контрпример и посмотреть что происходит и почему что-то не схлопывается, во многих местах стоит debug output, каждая структура может быть напечатана в человеко-читаемом виде.
Если написать у функции __attribute__((nonnull(1))), то clang начинает это оптимизировать до аналогичного GCC кода.
Для того, чтобы понять, на каком шаге LLVM пытается убрать проверку на null, можно использовать опцию, которая запускает первые num оптимизаций.
-mllvm -opt-bisect-limit=num
Бинарным поиском можно выяснить, что при атрибуте nonnull инструкция убирается при оптимизации EarlyCSEPass. Этот pass пытается каким-то очень простым образом избавиться от ненужных инструкций, тем более он один из самых первых и вполне логично сделать там проверки. После включения дебаг мода, мы понимаем, что инструкция убирается в SimplifyICmpInst.
Дальше стоит потыкаться gdb и посмотреть, когда оно 0 возвращает. В итоге всё сводится к функции isKnownNonZero -- это нам как раз и нужно. На момент написания заметки, код выглядит примерно так:
// Check for pointer simplifications.
if (V->getType()->isPointerTy()) {
// Alloca never returns null, malloc might.
if (isa<AllocaInst>(V) && Q.DL.getAllocaAddrSpace() == 0)
return true;
// A byval, inalloca, or nonnull argument is never null.
if (const Argument *A = dyn_cast<Argument>(V))
if (A->hasByValOrInAllocaAttr() || A->hasNonNullAttr()) // <- ВОТ ТУТ nonnull attr СРАБАТЫВАЕТ.
return true;
// A Load tagged with nonnull metadata is never null.
if (const LoadInst *LI = dyn_cast<LoadInst>(V))
if (Q.IIQ.getMetadata(LI, LLVMContext::MD_nonnull))
return true;
if (const auto *Call = dyn_cast<CallBase>(V)) {
if (Call->isReturnNonNull())
return true;
if (const auto *RP = getArgumentAliasingToReturnedPointer(Call, true))
return isKnownNonZero(RP, Depth, Q);
}
}
// Check for recursive pointer simplifications.
if (V->getType()->isPointerTy()) {
if (isKnownNonNullFromDominatingCondition(V, Q.CxtI, Q.DT))
return true;
...
Последние 3 строки как раз очень подозрительные, они скорее всего пытаются понять, а можно ли из контекста вывести, что указатель ненулевой. Dominating Tree, если грубо, из документации является контекстом инструкции, которые точно достижимы или будут достижимы из данной инструкции. Нам как раз это и нужно, посмотреть, а были ли из достижимой области load/store инструкции.
В итоге код получается очень простым в isKnownNonNullFromDominatingCondition.
for (auto *U : V->users()) { // Проходимся по всем видимым инструкциям.
...
// If the value is used as a load/store, then the pointer must be non null.
// Если был load, store в этой инструкции.
if (V == getLoadStorePointerOperand(U)) {
const Instruction *I = cast<Instruction>(U);
// И мы точно знаем, что это Undefined behaviour в этой функции и адресном пространстве.
if (!NullPointerIsDefined(I->getFunction(),
V->getType()->getPointerAddressSpace()) &&
// И инструкция является предшественником нашей
DT->dominates(I, CtxI))
// То указатель не может быть нулевым
return true;
}
....
}
В итоге ревью, немного обсуждения/непонимания процессов и сабмит в транк LLVM https://reviews.llvm.org/D71177. Скорее всего не откатят, так как я проверил на достаточно больших проектах, что оно не падает.
Оптимизация, может, немного игрушечная, но в кодовой базе, где работаю я, это сэкономило 30кб выходного кода (из 124MB, конечно), не очень много, но очень приятно. Потенциально оно может лучше анализировать передаваемые ненулевые указатели в другие функции.
Что дальше? Ну на самом деле, если разыменовать первый элемент, то clang уже сдаётся:
Почему так происходит? Потому что IR другой, он вычисляет указатель и потом загружает (делает load) в него. Казалось бы, фикс очень простой, надо просто добавить обработку getelementptr inbounds, но из-за сложной структуры, у меня пока это не получилось, но и такой пример намного более редкий. В LLVM inbound арифметика с нулевым указателем разрешена в редких случаях, мне надо ещё немного подумать и потестировать.
%4 = getelementptr inbounds i32, i32* %0, i64 1, !dbg !20 %5 = load i32, i32* %4, align 4, !dbg !20, !tbaa !21
Но в один момент можно и GCC обмануть легко.
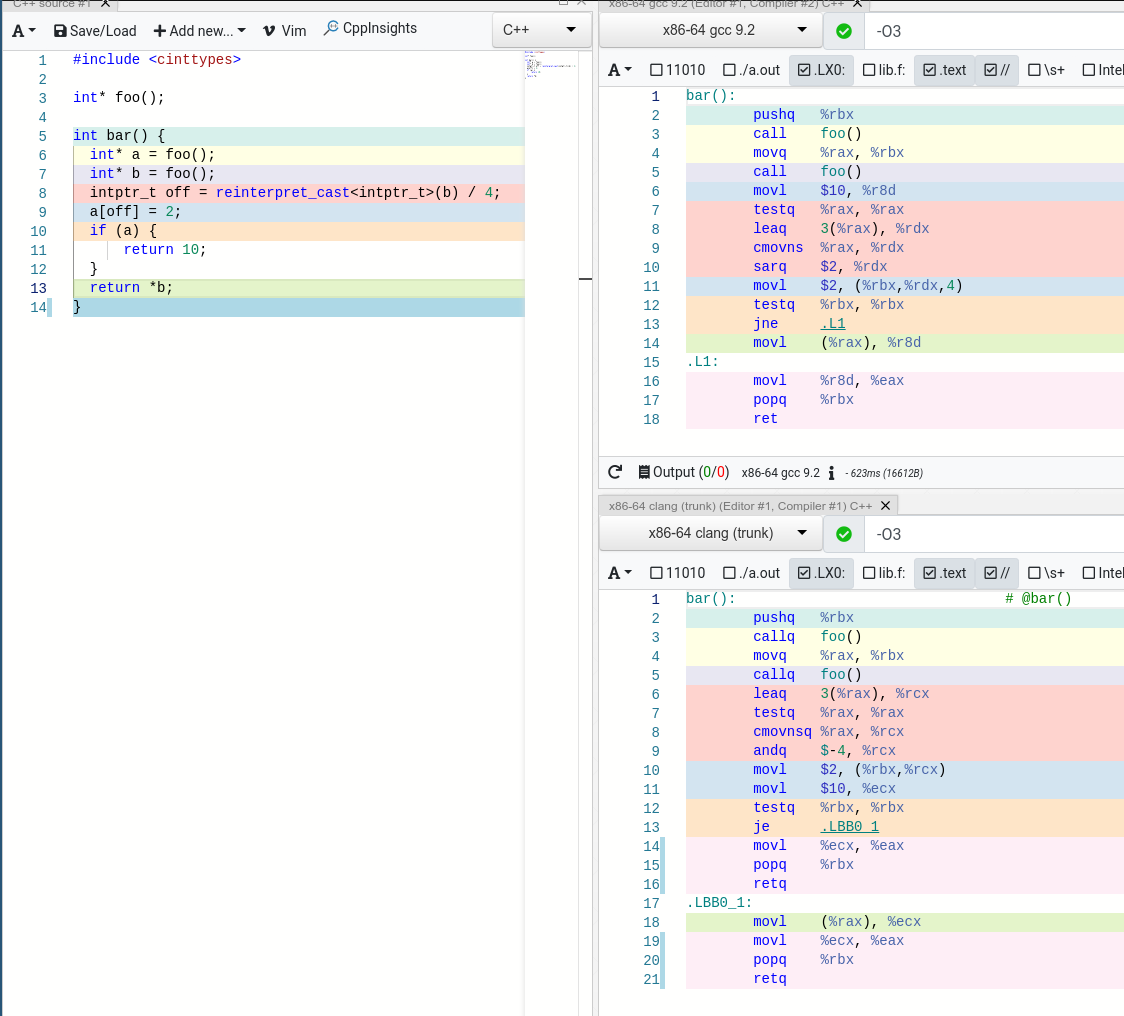
В данном случае a не может быть нулевым, потому что на него применили арифметику в a[off] выражении. К сожалению, ни clang, ни gcc не могут этого понять. Clang генерирует код чуть лучше, потому что прыжка не будет и следующие инструкции быстрее загрузятся, в GCC будет всегда прыжок через инструкцию.
Мораль -- компиляторы очень аккуратны с вашим кодом, поэтому в один момент они сдаются и не делают оптимизации, чтобы ни дай бог не разрушить кодогенерацию.
Новые выученные уроки
- Пишите маленькие функции. В огромном количестве мест в LLVM стоят небольшие ограничения на просмотр инструкций вокруг (около 30-40). Если функции большие, будет меньше информации компилятору. Маленькие функции хорошо инлайнятся, имеют понятный контекст вокруг и всё такое.
- Не полагайтесь на компиляторы, если вы хотите абсолютно максимальный перформанс, смотрите, можно ли сделать лучше самому и делайте. Но как хороший baseline, компиляторы сделают за вас 99% работы. Работайте вместе с ним, и не оправдывайтесь, что компиляторы всё умеют. Нет, не умеют.
- Понимайте, какие инварианты компилятор может понять легко, а какие даются с огромным трудом и помогайте упрощать инварианты, ставьте иногда __builtin_unreachable, если точно знаете, что код не может быть достигнут.
- Не бойтесь коммитить в опен сорс, даже если вам проект кажется очень сложным (например, Linux или LLVM). Комьюнити может помочь, и оно не всегда сложно, как кажется в первый раз.
- Уважайте математику, она пригождается в перформансе.