Как обмануть нейронную сеть
Давайте познакомимся с одной из атак на нейросети, которая приводит к ошибкам классификации при минимальных внешних воздействиях. Представьте на минуту, что нейросеть это вы. И в данный момент, попивая чашечку ароматного кофе, вы классифицируете изображения котиков с точностью более 90 процентов даже не подозревая, что "атака одного пикселя" превратила всех ваших "котеек" в грузовики.
А теперь поставим на паузу, отодвинем кофе в сторону и разберем как работают подобные атаки (one pixel attack).
Цель данной атаки заставить алгоритм (нейросеть) выдать некорректный ответ.
Ниже увидим это с несколькими различными моделями сверточных нейронных сетей. Используя один из методов многомерной математической оптимизации - дифференциальную эволюцию, найдем особенный пиксель, способный изменить изображение так, чтобы нейросеть стала неправильно классифицировать это изображение (несмотря на то, что ранее алгоритм "узнавал" это же изображение корректно и с высокой точностью).
Все подобные атаки можно разделить на два класса: WhiteBox и BlackBox. Разница между ними в том, что в первом случае нам все достоверно известно об алгоритме, модели с которой имеем дело. В случае с BlackBox все что нам нужно это входные данные (изображение) и выходные данные (вероятности отнесения к одному из классов). Атака одного пикселя (one pixel attack) относится к BlackBox.
Но как же найти те самые пиксели, изменение которых приведет к изменению класса изображения? Как найти пиксель, поменяв который one pixel attack станет возможна и успешна? Давайте попробуем сформулировать эту проблему как задачу оптимизации, но только очень простыми словами: при untargeted attack мы должны минимизировать доверие к нужному классу, а при targeted - максимизировать доверие к целевому классу.
Пришло время поделиться результатами исследования (проведенной атаки) и посмотреть как изменение лишь одного пикселя превратит лягушку в собаку, кота в лягушку, а автомобиль в самолет. А ведь чем больше точек изображения позволено изменять, тем выше вероятность успешной атаки на любое изображение.

Это были примеры untargeted attack, а теперь проведем targeted attack и выберем к какому классу мы бы хотели, чтобы модель отнесла (классифицировала) изображение. Задача намного сложнее предыдущей, ведь мы заставим нейросеть классифицировать изображение корабля как автомобиля, а лошадь как кота.


Для этой уязвимости есть библиотека one-pixel-attack-keras, которая делает эксплуатацию тривиальной. Для уверенного результата необходим не один, а несколько (три или пять) пикселей. Но качество этого метода и так превзошло ожидания ученых: около 30% изображений было превращено в подделки изменением одного пикселя, а изменением трех — уже 80%.
К чему приводит ложь
Увы, способ обмануть робота может заинтересовать не одних только ученых. Тем более, что с каждым годом задачи нейронных сетей становятся все богаче. Представьте себе умный банкомат, который примет нарисованные от руки купюры за настоящие. Или онлайн-сервис, позволяющий пользователям загружать недопустимый контент. Или систему видеораспознавания, которая посчитает одного человека за другого или вовсе проигнорирует постороннего на закрытой территории. Последний пример — это реальный пример из опыта очередных исследователей. Они соорудили специальную маску, позволяющую проходить неузнанным мимо интеллектуальных камер.

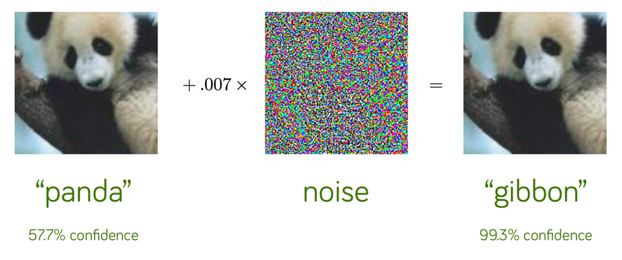
Умные автомобили тоже в зоне риска. Их автопилот можно обмануть, наклеив специальные метки на дорожные знаки или разметку. В результате машина проигнорирует «СТОП» перед оживленным перекрестком, подвергнув риску жизнь своего водителя и других участников движения. Как и в случае с пандой-гиббоном, человеческий глаз не заметит в таком знаке ничего необычного.
