Как мы решили повеселиться и случайно заняли призовое место на хакатоне
Михаил Михайлов для UniLecs
Валяясь на кровати после пар и листая ленту Вконтакте, я наткнулся на объявление о том, что будет проводится онлайн-хакатон. С учетом того, что идея поучаствовать в чем-нибудь таком-этаком назревала у меня с момента поступления, я позвал друзей и мы подали заявку. Кому интересно, что из этого вышло, − добро пожаловать под кат :)
Организаторы
21-22 ноября 2020 года проходил Online Hackathon в рамках Кружкового движения. На нём были представлены задачи от Газпром нефти, НТИ и Проектной мастерской.
Online Hackathon был организован Проектной мастерской и Профбюро ПМ-ПУ СПбГу в рамках Кружкового движения 2020 при поддержке Росмолодежи.
- Проектная мастерская — команда людей, которые помогают ребятам реализовывать свои проекты и выигрывать конкурсы.
- Профбюро ПМ-ПУ — это часть Профсоюза СПбГУ, команда студентов и аспирантов, занимающихся организацией различных мероприятий: от недели факультета до хакатонов.
Тематики
- Data Science
- Цифровой университет (Университет 2035)
- Цифровая экономика
- Свой стартап
Мы собрались командой из пятерых человек, все с матмеха СПбГУ — я, два моих одногруппника (Данил Ельцов и Данил Евдокимов) и еще двое ребят со второго курса (Илья Гущин и Андрей Пантелеймонов), и выбрали кейс Data Science.
Пятница. Кейс и подготовка
В пятницу днём нам пришло следующее описание кейса:
В компании вводятся так называемые “барьеры безопасности”, анализ которых сможет предотвратить негативные происшествия. Однако аналитика сопряжена с рядом проблем:
- 16-20 тысяч сообщений на естественном языке в месяц. Объем регистрируемых сообщений об опасных действиях/опасных условиях с производственных площадок по компании;
- 5 рабочих дней затрачивается на сбор, обработку сообщений сотрудниками блоков и ДО. Длительный процесс не даёт возможности оперативно реагировать на сообщения о работоспособности производственных барьеров;
- Человеческий фактор при классификации. Субъективный результат классификации сообщений и, как результат, – отсутствие сквозной аналитики (между ДО).
Сейчас существует цифровой проект «Определение барьеров производственной безопасности из сообщений об опасных условиях-опасных действиях».
В рамках проекта разрабатывается инструмент для классификации записей об опасных действиях и условиях, поступающих от ДО и подрядных организаций в различных информационных системах (контур безопасности, ОУ ОД БРД, АЗИМУТ и других).
Решение позволит повысить достоверность данных, на основании которых принимаются решения о работоспособности барьеров и проводится оценка рисков ПБ. Появление новой аналитики позволит сфокусировать усилия сотрудников на предупреждение «пробоя» барьера промышленной безопасности. Сократятся трудозатраты на обработку заявки и создание аналитики с 5 дней до нескольких часов.
Замечания по данным:
- Иногда в графу прецеденты респонденты заносят сразу несколько опасных действий и условий;
- Данные содержат аббревиатуры, термины, неточные выражения, опечатки и сленг.
Необходимо:
- Построить модель кластеризации. В дальнейшем эти кластеры помогут провести аналитику для сопоставления прецедентов с классификацией опасных действий и условий — с барьерами безопасности.
- Объяснить получившиеся кластеры: почему они такие. Сделать вывод, можно ли с помощью них упростить какую-либо полуавтоматическую разметку данных по классам.
Глобально можно выделить несколько возможных кластеров:
- Прецеденты, связанные с вождением, и управлением транспортным средством (ТС);
- Прецеденты, связанные с использованием исправного инструмента;
- Прецеденты, связанные с работой на высоте и с подъёмом грузов;
- Прецеденты, связанные с защитой (СИЗ (средства индивидуальной защиты), СИЗОД (средства индивидуальной защиты органов дыхания), перчатки, куртки и тп);
- Все остальное"
Мы прочитали и... ничего не поняли. Ну, что-то поняли, это задача про обработку естественного языка, но суть задания сначала мы не уловили. Вечером я и наш главный программист собрались обсуждать кейс (остальные ребята не смогли подтянуться).
Первое, с чего мы начали − поиск в интернете. Случайно мы нашли заказ на проект, в рамках которого надо было решить эту задачу. Так мы поняли, что от нас хотят:
Написать приложение, которое по описанию нарушения техники безопасности относит это нарушение к какому-либо кластеру.
После этого мы решили продумать, как именно решать задачу: с помощью mindmap-инга мы нагенерировали кучу идей, из которых выбрали несколько вариантов.
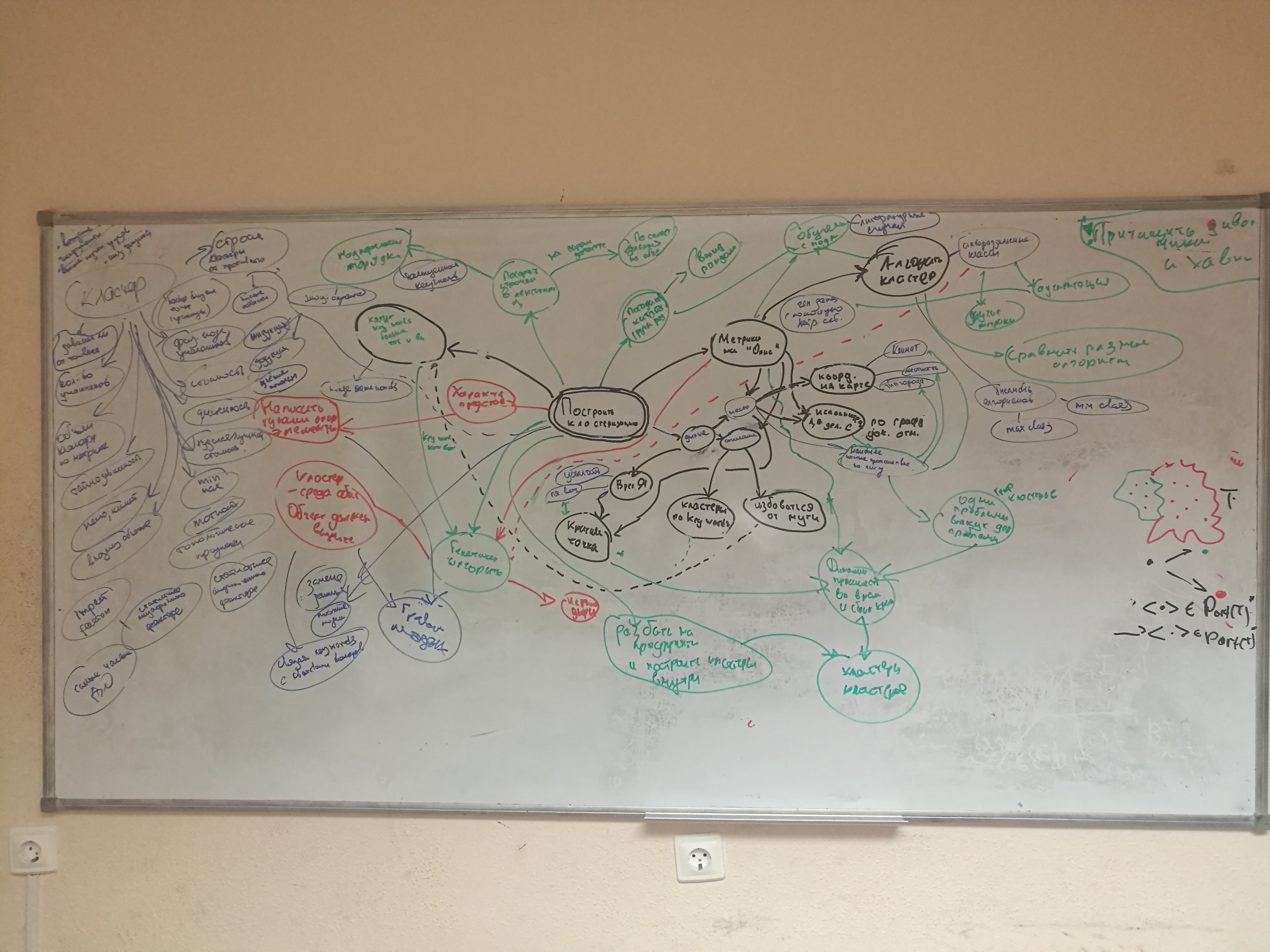
Мы не могли наверняка знать, какая информация о нарушениях у нас будет, поэтому выстроили такие модели:
- Ручная кластеризация. Просто смотрим на данные, сами находим кластеры и ставим каждому кластеру в соответствие какие-то ключевые слова. Потом считаем в описании нарушения ключевые слова и выбираем кластер, к которому можно отнести нарушение:
- Ансамбль Word2Vec + K-means. Word2Vec ставим каждому слово вектор в пространстве. Чтобы посчитать вектор предложения, мы просто брали среднее всех слов в предложении. Потом с помощью K-means делали кластеризацию.
Однако реальность была куда суровее...
Суббота
День X настал. Мы решили, что собраться всей командой будет лучше, чем сидеть каждый у себя. Поэтому, собравшись у электрички, отправились в сторону нашего сокомандника, у которого писали хакатон.
В субботу должны были прислать данные. До этого момента мы ходили по магазинам и затаривались кофе/едой и всем, что должно помочь не спать по ночам.

После того, как покупки были завершены, мы ещё раз проговорили результаты брейншторминга, настроили гитхаб и стали ждать данных.
Когда данные пришли, мы − люди, никогда до этого не работавшие с "сырыми" данными, были слегка в шоке. По факту, всё, что у нас было − описание инцидента и следующая информация об объекте: дочернее общество; подрядчик; направление деятельности; производственный объект; описание сообщения.
Никаких географических/временных данных. Да и то, что имелось, было плохого качества − местами ASCII спецсимволы "\r", "\n", местами вместо названия объекта, где произошло нарушение, было "null". Вечер субботы мы потратили на очистку и подготовку данных.
Мы всё ещё не отступали от идеи проанализировать какую-то метаинформацию, надеясь найти в ней что-то интересное. Например, у каких подрядчиков чаще всего происходят нарушения.
Ночь и второй день
В целом, мы решили попробовать сделать ручную кластеризацию и ансамбль алгоритмов Word2Vec. Товарищей, которые не умели программировать, мы отправили играться с KNIME.
Поначалу всё шло хорошо, однако к 4 утра усталость дала о себе знать. Наш докладчик отправился спать вместе с ещё одним человеком, а у меня и оставшегося главного программиста начались тупняки. Мы хотели к утру выкатить готовые модели и потратить оставшееся время воскресенья на приведение кода в порядок и подготовку презентации, однако к утру у нас были готовы только самые-самые сырые решения. Я написал ручную кластеризацию, которая просто считала ключевые слова, параллельно сделав какую-то аналитику. Модель на основе Word2Vec работала так себе, так как мы не подготовились и не нашли специальные корпусы и расшифровки аббревиатур.

В воскресенье днём мы дообучивали модели и копались в данных, пытаясь найти что-то интересное. Найти удалось − был отдельный спектр прецедентов, связанных с ковидом. Вместе с этим нашёлся корпус текстов по сфере нефтегазовой промышленности и словарь аббревиатур. Запустив обучаться на нём нашу модель, мы отправились готовить презентацию. В процессе работы мы не общались между собой, каждый использовал свой инструмент, и нам надо было обсудить получившиеся результаты и скомпилировать их во что-то цельное.
Мы не успели доделать презентацию к моменту нашего выступления, поэтому выступали последними. Было несколько очень хороших команд, и мы, в общем-то, уже расстроились, выступили и разошлись.

А что в итоге?
А в итоге мы заняли второе место. Почему − сами до конца не понимаем. Возможно, из-за хорошей презентации. Возможно, из-за того, что на чекпоинтах мы очень подробно описывали всё, что сделали и что хотим делать дальше. Ясно несколько вещей:
- Разобраться с инструментами и библиотеками следовало до начала хакатона;
- Стоило также подыскать имеющие отношение к теме датасеты. Имея их, мы бы сразу сэкономили кучу времени;
- Стоило посмотреть best-practice по задачам NLP;
- Брейншторм перед хакатоном определённо помог, однако следовало собраться всей командой. Вдвоём мы не обратили внимания на некоторые детали, те же аббревиатуры в текстах.
Что получилось? Получилось три модельки, каждая из которых выдала примерно одинаковые кластеры (по содержанию; математический анализ мы не делали). Одна была совсем сырой, ещё одна обучалась, и поэтому на презентации мы не смогли её продемонстрировать, ещё одна была No Code. У каждой модели были свои преимущества (одна − наглядная, другая − простая, третья − точная).
У команды победителей была одна модель, которая брала лучшие качества от наших трех. Как-то так.