Как изобрели современный искусственный интеллект. История изнутри.
Trading PhronesisОни встретились, увлеклись одной идеей и написали статью, давшую старт, возможно, самому значительному технологическому прорыву в новейшей истории.
Как и многие научные открытия это произошло по счастливой случайности.

В начале 2017 года два сотрудника Google, Ашиш Васвани и Якоб Ушкорейт, находились в коридоре кампуса компании в Маунтин-Вью и обсуждали новую идею по улучшению машинного перевода, технологии искусственного интеллекта, лежащей в основе Google Translate.
Исследователи ИИ работали с другим коллегой, Ильей Полосухиным, над концепцией, которую они назвали «самовниманием» (self-attention), которая могла бы радикально ускорить и улучшить понимание языка компьютерами.

Полосухин, фанат научной фантастики из Харькова, считал, что “самовнимание” немного напоминает язык пришельцев в фильме "Прибытие". Вымышленный язык инопланетян не содержал линейных последовательностей слов. Вместо этого они генерировали целые предложения, используя один символ, обозначающий идею или концепцию, которую лингвисты-люди должны были расшифровать как единое целое.
Современные методы машинного перевода на тот момент включали сканирование каждого слова в предложении и его последовательный перевод. Идея «самовнимания» заключалась в том, чтобы прочитать всё предложение сразу, анализируя все его части одновременно, а не только отдельные слова.
Трое ученых из Google предположили, что такой подход позволит переводить намного быстрее и точнее. Они начали экспериментировать с ранними прототипами англо-немецких переводов и обнаружили, что это работает.
Во время беседы в коридоре их услышал Ноам Шазир, ветеран Google, который пришел в компанию еще в 2000 году, когда в Google работало примерно 200 сотрудников.
Шазир, который помог создать функцию проверки орфографии "Did You Mean?" для Google Search, помимо нескольких других инноваций в области искусственного интеллекта, был разочарован существующими методами генерации языка и искал новые идеи. Поэтому, услышав разговор своих коллег об идее “самовнимания”, он решил присоединиться к ним.
Случайный разговор в коридоре стал началом многомесячного сотрудничества, которое в конечном итоге привело к созданию архитектуры для обработки языка, известной просто как "трансформер".
Восемь человек, которые в итоге приняли участие в его создании, описали свою идею в короткой статье с названием: "Внимание – это все, что вам нужно".

Один из авторов, Ллайон Джонс, выросший в крошечной валлийской деревне, говорит, что название было отсылкой к песне Битлз «All You Need Is Love». Статья была впервые опубликована в июне 2017 года и положила начало совершенно новой эре искусственного интеллекта: развитию генеративного ИИ.
Сегодня трансформер лежит в основе большинства передовых приложений искусственного интеллекта в разработке. Он встроен не только в Google Search и Translate, для которых он изначально и создавался, но и приводит в движение все большие языковые модели, включая те, что стоят за ChatGPT и Bard. Он обеспечивает автозаполнение наших мобильных клавиатур и распознавание речи умных динамиков.
(«Трансформер» – буква «Т» в ChatGPT – Generative Pre-trained Transformer или «генеративный предварительно обученный трансформер»)
Стоит отметить, его настоящая сила заключается в том, что он работает в областях, далеких от языка. Он может генерировать что угодно с повторяющимися мотивами или шаблонами, от изображений с использованием инструментов, таких как Dall-E, Midjourney и Stable Diffusion, до компьютерного кода с помощью генераторов, таких как GitHub CoPilot, или даже ДНК.
Один из членов команды, Васвани, выросший в индийской семье в Омане, увлекался музыкой и у него появился вопрос: можно ли использовать трансформер для её генерации? Он был поражен, обнаружив, что он может генерировать классическую фортепианную музыку не хуже, чем самые современные модели искусственного интеллекта того времени.
"Трансформер - это способ очень быстро зафиксировать взаимодействие между различными частями любой входящей информации с учетом всех ее особенностей. Это общий метод, который фиксирует взаимодействие между частями предложения, нотами в музыке, пикселями изображения или частями белка. Его можно использовать для любой задачи.» — говорит Васвани.
Это такой вид нейросетевой архитектуры, который хорошо подходит для обработки последовательностей данных. Пожалуй, самый популярный пример таких данных - это предложение, которое можно считать упорядоченным набором слов.
Трансформеры создают цифровое представление каждого элемента последовательности, инкапсулируют важную информацию о нём и окружающем его контексте. Создавая такие информативные представления, трансформеры помогают нейросетям лучше понять скрытые паттерны и взаимосвязи во входных данных. И поэтому они лучше синтезируют последовательные и взаимосвязанные результаты.
Главное преимущество трансформеров заключается в их способности обрабатывать длительные зависимости в последовательностях. Они очень производительны, так как могут обрабатывать последовательности параллельно. Это особенно полезно в задачах вроде машинного перевода и синтеза текста.
Зарождение трансформера и история его создателей помогает понять, как мы пришли к этому моменту в искусственном интеллекте: точке перелома, сравнимой с нашим переходом в интернет или смартфоны, которая заложила основу для нового поколения предпринимателей, создающих потребительские продукты на базе искусственного интеллекта для массового рынка.
Но это также подчеркивает, как превращение Google в крупную бюрократическую компанию подавило ее способность позволить процветать предпринимательству и быстро запускать новые потребительские продукты. Все восемь авторов исторической статьи в итоге покинули компанию. Период работы «трансформеров» в Google:
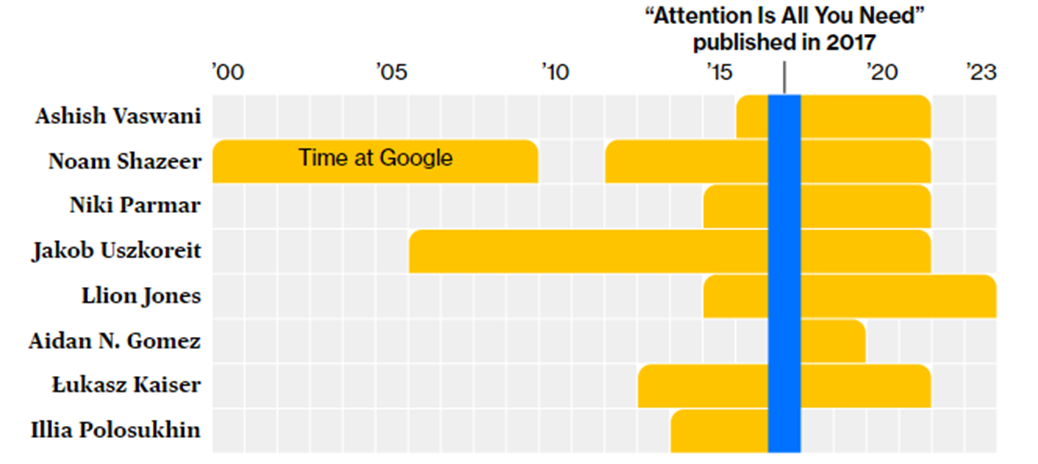
Рождение инновации
Как и все научные достижения, трансформер был создан на основе многих лет исследований, проведенных в лабораториях Google, Meta, университетов.
Но в течение 2017 года все детали сложились воедино благодаря счастливой случайной встрече группы специалистов, разбросанных по исследовательским подразделениям Google.
В финальную команду «трансформеров» вошли Васвани, Шазир, Ушкорейт, Полосухин и Джонс, а также Эйдан Гомес, стажер, тогда обучавшийся в Университете Торонто, и Ники Пармар, недавняя выпускница магистратуры в команде Ушкорейта из Пуны на западе Индии. Восьмым автором был Лукаш Кайзер, который также работал по совместительству во французском Национальном центре научных исследований.
Каждый из них был привлечен к тому, что многие считали новой областью исследований ИИ: обработке естественного языка. Образовательное, профессиональное и географическое разнообразие группы, происходящее из таких стран, как Украина, Индия, Германия, Польша, Великобритания, Канада и США, сделало их уникальными. «Наличие такого разнообразного круга людей было абсолютно необходимо для проведения этой работы» — вспоминал Ушкорейт, росший в США и Германии.
Ушкорейт изначально был против работать в области понимания языка, потому что его отец был профессором компьютерной лингвистики. Но когда он пришел в Google на стажировку, то с недовольством обнаружил, что самые интересные проблемы в области искусственного интеллекта тогда были связаны с языковым переводом. Он последовал по стопам своего отца без какого-либо желания и тоже начал сосредоточенно работать в области машинного перевода.
По воспоминаниям, изначально они работали в трех отдельных группах над различными аспектами “самовнимания”, но потом решили объединить усилия. В то время как некоторые из группы писали первоначальный код, очищали данные и тестировали их, другие отвечали за создание архитектуры вокруг моделей, интеграцию их в инфраструктуру Google для эффективной работы и, в итоге, обеспечивали простоту развертывания.
"Идея о трансформере формировалась естественным образом, когда мы работали и сотрудничали в офисе" - говорил Джонс. Яркая открытая рабочая среда Google, включая велосипеды на кампусе, оказалась плодотворной. "Я помню, как Йакоб Ушкорейт подъезжал к моему столу на велосипеде и чертил модель на белой доске позади меня, обсуждая свои мысли с теми, кто был рядом".
Связующими силами между группой было их увлечение языком и мотивация использовать искусственный интеллект для его лучшего понимания. Как вспоминал Шазир: "Текст действительно является нашей самой концентрированной формой абстрактного мышления. Я всегда чувствовал, что, если вы хотите создать что-то действительно умное, вам следует делать это с помощью текста".
Модель, опубликованная в статье, была упрощенной версией исходной идеи “cамовнимания”. Шазир обнаружил, что она работает даже лучше, когда избавлена от всех наворотов. Код модели послужил отправной точкой, но потребовалась обширная тонкая настройка, чтобы заставить его работать на графических процессорах, оборудовании, которое лучше всего подходит для технологий глубокого обучения, таких как трансформер.
"В глубоком обучении ничего никогда не сводится только к уравнениям. Это то, как вы... помещаете их на аппаратное обеспечение, это гигантский мешок чёрной магии, который действительно освоили только немногие люди" - говорит Ушкорейт.
Когда они были применены, в основном Шазиром, которого один из его соавторов называет "волшебником", трансформер начал улучшать каждую задачу, брошенную в него, быстрыми рывками.
Его преимущество заключается в том, что он позволяет выполнять вычисления параллельно и упаковывать их в гораздо меньшее количество математических операций, чем это было до него, что делает его быстрее и эффективнее. "Это просто, очень просто, и в целом модель очень компактна", - говорит Полосухин.
Одобренная рецензией версия статьи была опубликована в декабре 2017 года, как раз ко времени для NeurIPS, одной из самых престижных конференций по машинному обучению. Многие из авторов трансформера помнят, как их обступали на мероприятии, когда они представляли плакат со своей работы. Скоро ученые из организаций вне Google начали использовать трансформеры в приложениях от перевода до ИИ-генерированных ответов, маркировки и распознавания изображений.

«Произошёл кембрийский взрыв как в исследованиях, так и в практическом применении трансформера» — говорил позже Васвани, имея в виду момент 530 миллионов лет назад, когда жизнь стала быстро развиваться на планете. «Мы видели, как он развивает нейронный машинный перевод, появилась языковая модель BERT — это был очень важный момент для практического применения ИИ, когда трансформер вошел в Поиск Google».
После публикации статьи Пармар обнаружила, что трансформер может генерировать длинные страницы текста, подобные Википедии, где предыдущие модели сталкивались с трудностями. «Мы уже знали тогда, что до этого никто не мог сделать ничего подобного», — говорит она.
Пармар также заметила одно из ключевых свойств трансформера: когда вы масштабируете, предоставляя все больше и больше данных, «он способен учить намного лучше». Все это привело к появлению больших моделей, таких как GPT-4, которые обладают гораздо лучшими логическими и языковыми возможностями, чем их предшественники.
«Общая тема заключалась в том, что трансформер, казалось, работал намного лучше, чем предыдущие модели, независимо от того, для чего и где его применяли» — говорит Джонс. «Я думаю, именно это и вызвало эффект снежного кома».
Жизнь за пределами Google
Трансформеры не мгновенно захватили мир и даже Google. Кайзер вспоминает, что примерно во время публикации статьи Шазир предложил руководству Google отказаться от поискового индекса и обучить огромную сеть трансформером - в общем, изменить способ организации информации в Google.
Но стартап под названием OpenAI оказался гораздо быстрее Google. Результатом стали первые продукты GPT. Как сказал Сэм Альтман (OpenAI), "когда вышла статья о трансформере, я не думаю, что кто-то в Google понял, что она означает".

Внутри компании картина была более сложной.
"Для нас было совершенно очевидно, что трансформер может делать действительно волшебные вещи" - вспоминал Ушкорейт. "Теперь вы можете задать вопрос, почему в 2018 году Google не создал ChatGPT? Реально, мы могли бы получить GPT-3 или даже 3.5, возможно, в 2019, может быть, в 2020 году. Главный вопрос не в том, видели ли они это? Вопрос в том, почему мы ничего не сделали с тем, что увидели сами?".
Многие критики указывают на то, что Google превратилась из площадки, ориентированной на инновации, в бюрократическую структуру. Но может быть для гигантской компании, чьи технологии лидировали в отрасли и приносили огромные прибыли на протяжении десятилетий, идеи трансформеров были очень смелыми. В 2018 году Google все же начала внедрять трансформеры в свои продукты, начиная c переводчика. В том же году компания представила новую языковую модель на основе трансформера под названием BERT.
Но эти внутренние изменения в Google кажутся робкими по сравнению с квантовым скачком OpenAI и смелой интеграцией систем на основе трансформеров в линейку продуктов Microsoft. Когда Google спросили, почему компания не запустила первой такую крупную языковую модель, как ChatGPT, ее представители ответили, что они считают выгодным позволить другим быть лидерами. "Нам не совсем понятно, что могло бы получиться. Дело в том, что мы можем сделать больше после того, как люди увидят, как это работает".
В итоге, как и говорилось выше, все восемь авторов статьи покинули Google.

Полосухин ушел в 2017 году, чтобы основать стартап под названием Near, первоначальная идея которого заключалась в использовании ИИ для обучения компьютеров кодированию, но с тех пор перешел на платежи на блокчейне. Компания Полосухина, Near, создала блокчейн, рыночная капитализация токенов которого составляет около 4 миллиардов долларов.
Следующим забеспокоился Гомес, самый младший и неопытный. Канадский студент, страстно увлекающийся модой и дизайном, прошел стажировку у Кайзера (который с тех пор ушел, чтобы присоединиться к OpenAI), и оказался в авангарде новых захватывающих исследований в области понимания языка.
«Причина, по которой я покинул Google, заключалась в том, что на самом деле я не видел достаточного внедрения в продуктах, которые я использовал. Они не менялись. Они не модернизировались. Они не принимали эту технологию. Я просто не видел, чтобы эта технология большой языковой модели действительно достигла тех мест, которых ей нужно было достичь» — говорит он.
В 2019 году он покинул Google, чтобы основать Cohere, стартап в области генеративного искусственного интеллекта, стоимость которого оценивается более чем в 2 миллиарда долларов, с инвестициями, среди прочего, от Nvidia, Oracle и Salesforce. Гомес заинтересован в применении больших языковых моделей для решения бизнес-задач — от банковского дела и розничной торговли до обслуживания клиентов. «Для нас речь идет о снижении барьера доступа», — говорит он. «Каждый разработчик должен уметь работать с этим материалом».
Ушкорейт решил использовать трансформер в совершенно другой области. Его стартап Inceptive — биотехнологическая компания, которая разрабатывает «биологическое программное обеспечение» с использованием методов глубокого обучения. «Если вы думаете о компьютерном программном обеспечении, то это программирование чего-то исполняемого. . . есть программа, которая затем преобразуется в программное обеспечение, которое работает на вашем компьютере» — говорит он. «Мы хотим сделать то же самое, но с клетками вашего тела».
Компания уже поставила разработанные с помощью искусственного интеллекта молекулы для вакцин от инфекционных заболеваний крупной фармацевтической компании. «Я убежден, что это, безусловно, лучший способ развить то, над чем я работал в течение последнего десятилетия, чтобы улучшить и, возможно, даже спасти жизни людей» — говорит Ушкорейт.
Биотехнологическая компания Якоба Ушкорейта Inceptive оценивается в 300 миллионов долларов.
Токийская компания Ллиона Джонса Sakana AI оценивается в 200 миллионов долларов.
В 2021 году Пармар и Васвани объединились как бизнес-партнеры, чтобы основать компанию Adept (оценка - 1 миллиард долларов. См. ниже), а сейчас занимаются второй компанией под названием Essential AI (финансирование - 8 миллионов долларов, в том числе от Thrive Capital, раннего инвестора в Instagram, Slack и Stripe).
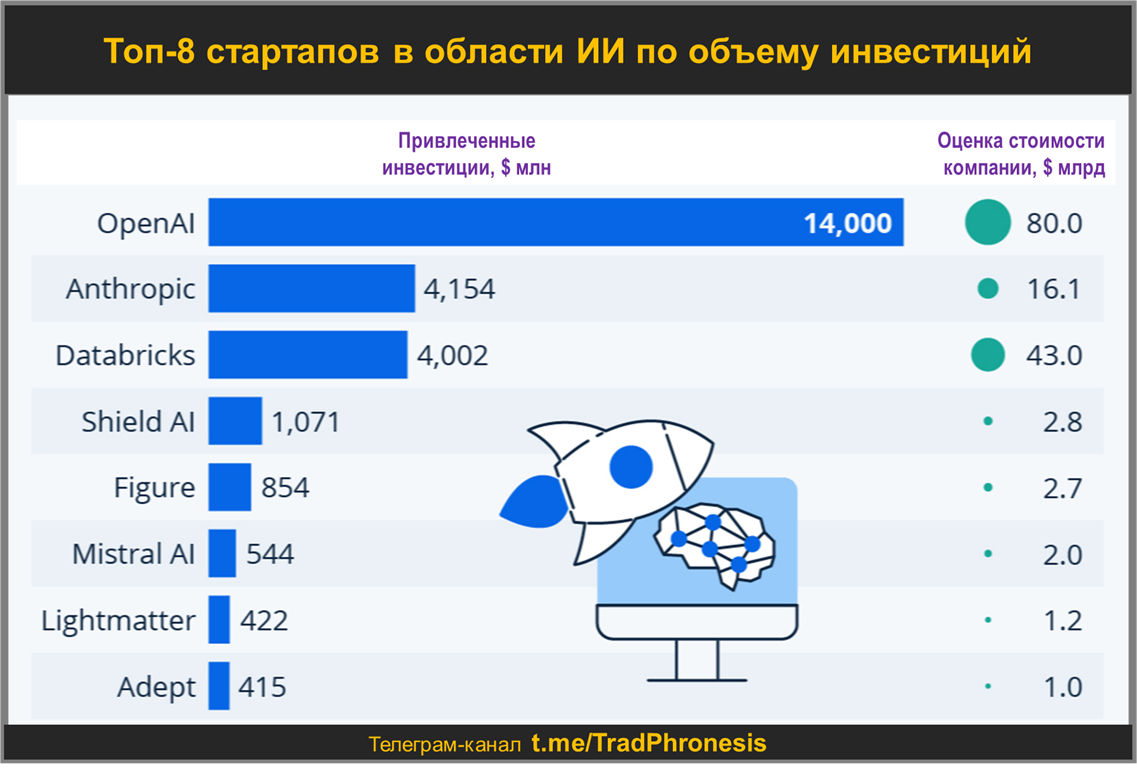
«Google был удивительным местом, но они хотели оптимизировать существующие продукты. . . поэтому дела продвигались очень медленно» — вспоминает Пармар. «Я хотела взять эту очень мощную технологию и создать на ее основе новые продукты. И это было большой мотивацией уйти».
Шазир ушел из Google в 2021 году, спустя два десятилетия, и стал соучредителем Feature.ai, компании, которая позволяет пользователям создавать чат-ботов из своих собственных персонажей, от Будды до Юлия Цезаря или японского аниме. «Похоже, что запускать продукты в крупной компании довольно сложно. . . стартапы могут развиваться быстрее», — говорит он. Компания, генеральным директором которой он является, недавно была оценена в $1 млрд.
Все эти компании (кроме Near) основаны на технологии трансформера.

Многие из соавторов до сих пор часто общаются, празднуя успехи друг друга и поддерживая друг друга в преодолении уникальных трудностей начинающего предпринимателя.
Если трансформер был моментом большого взрыва, то теперь вокруг него расширяется вселенная: от AlphaFold компании DeepMind, который предсказал структуру почти каждого известного белка, до ChatGPT, который Васвани называет «событием черного лебедя».
Это привело к периоду, который инсайдеры Кремниевой долины называют технологическим избытком — время, которое отрасли будут тратить на интеграцию новейших имеющихся разработок искусственного интеллекта в продукты, даже если исследования в области ИИ вообще не будут продвигаться вперед.
«Вы видите последствия: ИИ привлекает исследователей, технологов, строителей и специалистов по продуктам. Теперь мы считаем, что существует технологический избыток. . . и в различных продуктах можно реализовать огромную ценность» — говорит Васвани. «В каком-то смысле именно поэтому мы все разошлись и попытались передать эту технологию непосредственно в руки людей».
Что остается Google, потерявшему такую команду… Он может похвастаться тем, что создал среду, которая поддерживает стремление к нестандартным идеям.
"Во многих отношениях Google был далеко впереди - он инвестировал в нужные умы и создал среду, в которой мы могли исследовать и расширять границы" - вспоминает Пармар. "Нет ничего удивительного в том, что потребовалось время, чтобы принять это. У Google на кону было гораздо больше".
Google отметил, что "гордится революционной работой с трансформерами и вдохновлена экосистемой искусственного интеллекта, которую это создало". Компания признала горькую реальность того, что в такой динамичной среде талантливые сотрудники могут сами выбирать, как им двигаться дальше.
По мнению Джилл Чейз, партнера CapitalG, фонда роста Alphabet/Google, где она специализируется на инвестициях в ИИ: «Созданный интеллектуальный капитал привел к взрыву инноваций. То, что вышло из статьи «Внимание — это все, что вам нужно», является основой для компаний, занимающихся генеративным ИИ. Все их продукты теперь существуют благодаря трансформеру».
Без среды Google не было бы и трансформеров. Мало того, что все авторы были сотрудниками Google, они еще и работали в одних и тех же офисах. Встречи в коридорах и подслушанные разговоры за обедом привели к важным открытиям. Группа также отличалась культурным разнообразием. Шесть из восьми авторов родились за пределами США; двое других - дети немцев, получивших грин-карту и временно проживавших в Калифорнии, и американца в первом поколении, чья семья бежала от преследований.
Ушкорейт убежден, что инновации зависят от правильных условий.
"Это привлечение людей, которые очень заинтересованы в чем-то, и которые находятся на правильном этапе своей жизни. Если у вас это есть, и вы получаете от этого удовольствие, и вы работаете над правильными проблемами, и вам повезло, то происходит волшебство."
Дилемма инноватора
Вся история про трансформеров является прекрасной иллюстрацией «дилеммы инноватора» — термина, придуманного профессором Гарвардской школы бизнеса Клейтоном Кристенсеном, который исследовал вопрос, почему лидеров отрасли обгоняют мелкие, новые игроки.
Исторически сложилось так, что конкуренция заставляет исчезать даже великие компании. Так было и так будет. Они не обязательно обанкротятся. Потеряют лидерство. Возможны слияния, поглощения или разделения.
Только 52 компании остались в списке Fortune 500, начиная с 1955 года. Другими словами, чуть более 10% компаний из списка Fortune 500 в 1955 году оставались в списке в течение 69 лет до 2024 года.

Инновации (особенно прорывные) меняют рынки и отрасли, создавая новые технологии и продукты. Наряду с этим, лидерство на фондовом рынке также имеет тенденцию меняться. Этот процесс иногда ускоряется или замедляется, но, например, с 1980 года более 35% компаний, входящих в индекс S&P 500, сменялись на новые в среднем за 10-летний период.
Было бы разумно предположить, когда список Fortune 500 будет опубликован лет через 50, в 2070-х годах, почти все сегодняшние ведущие компании, включая Google, больше не будут существовать в том виде, в каком мы их знаем. Они будут заменены новыми компаниями в новых отраслях, которых мы сегодня даже не можем себе представить. И, кто знает, возможно, среди них будут компании, созданные кем-то из «трансформеров».
_________________________________________________________
ПРИЛОЖЕНИЕ. Как работает модель трансформера - упрощенное руководство
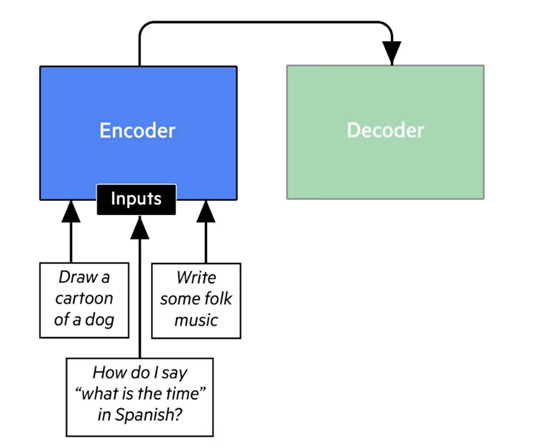
Трансформер разделен на две основные части - кодировщик, который обрабатывает и учится понимать входную последовательность, которая может быть любым повторяющимся шаблоном (слова, музыкальные ноты, пиксели).
И декодер, который производит выходную последовательность (предложение, музыкальный фрагмент, изображение).
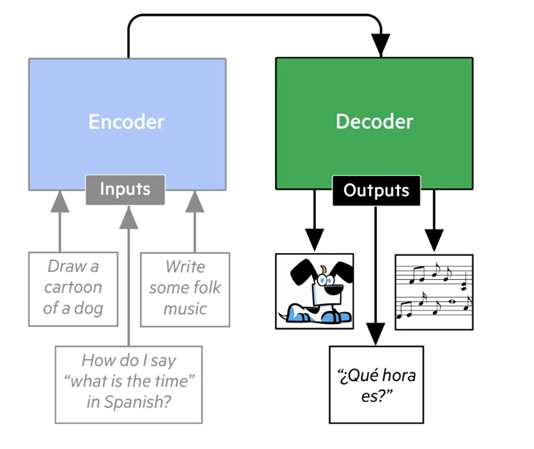
Ввод: берется предложение. Оно разбивается на отдельные токены или части слова. Каждое слово представлено в виде числового вектора, называемого вложением. Можно представить это как уникальный код, который захватывает значение и контекст.
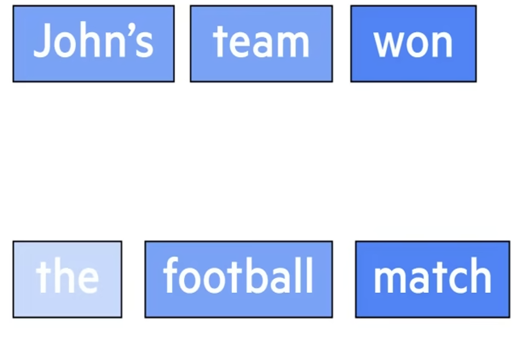
Кодировщик трансформера обращает внимание на каждое слово в предложении, определяя, какие из них необходимы для понимания всего предложения и где они находятся, присваивая им более высокие оценки внимания. Но он также использует “Самовнимание”, когда модель смотрит на все слова в предложении одновременно, захватывая их связи и зависимости. Он определяет значение на основе контекста в предложении.

Это ускоряет процесс. Также понимание длинных фрагментов текста становится лучше, по сравнению с более ранними моделями, которые могли обрабатывать слова только последовательно.
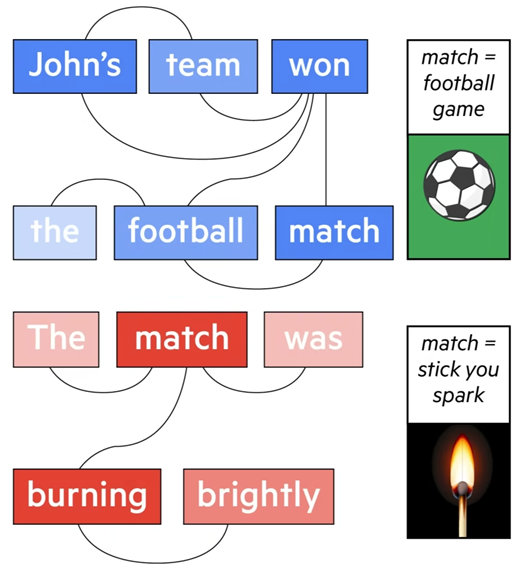
Генерация ответа: Декодер предсказывает следующее слово в предложении пошагово, используя то, что он узнал от кодировщика и обращая внимание на контекст предыдущих сгенерированных слов для улучшения прогнозов. Чем на большем объеме данных он обучен, тем лучше его выводы и прогнозы, основанные на предыдущих шаблонах.
