Как использовать GraphQL Federation для инкрементальной миграции с монолита (Python) на микросервисы (Go)
Твой программистGraphQL Federation
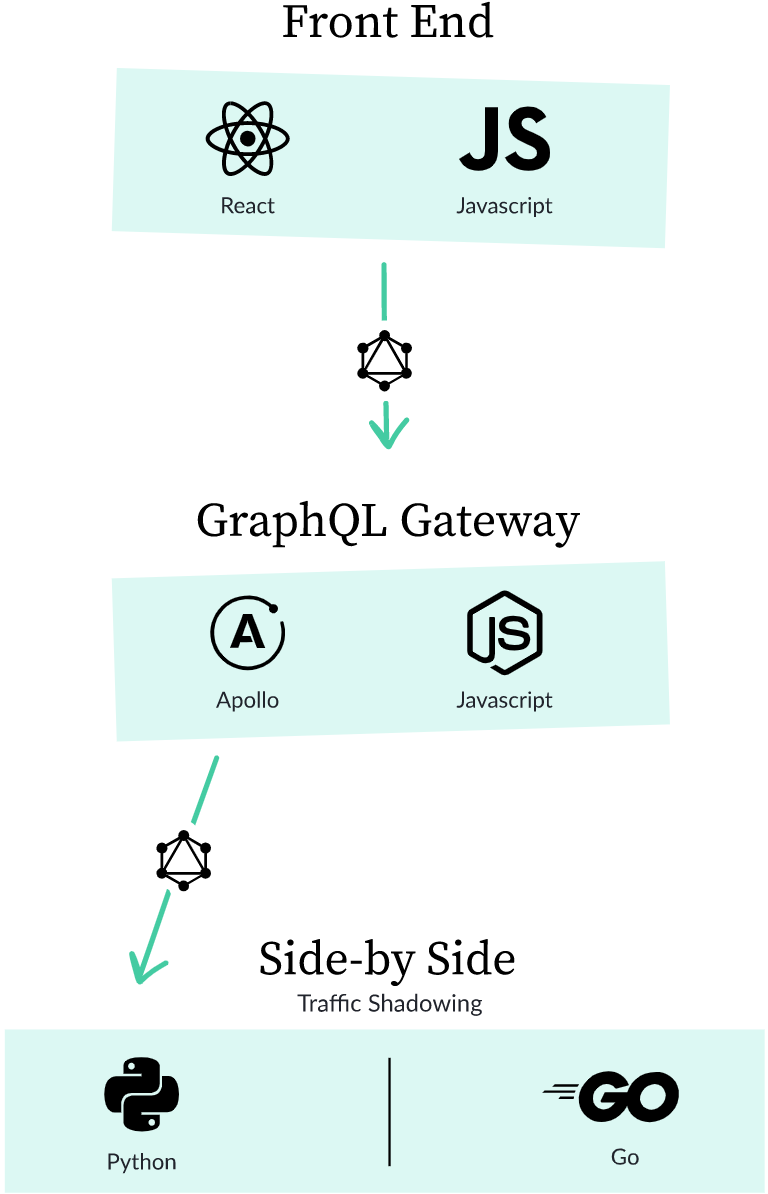
Мы решили построить нашу новую архитектуру вокруг GraphQL Apollo Federation. GraphQL был создан разработчиками Facebook как альтернатива REST API. Федерация — это построение единого шлюза для нескольких сервисов. Каждый сервис может иметь свою GraphQL-схему. Общий шлюз объединяет их схемы, генерирует единое API и позволяет выполнять запросы для нескольких сервисов одновременно.
Прежде чем, пойдём дальше, хотелось бы особо отметить следующее:
- В отличие от REST API, у каждого GraphQL-сервера есть собственная типизированная схема данных. Она позволяет получить любые комбинации именно тех данных с произвольными полями, которые вам нужны.
- Шлюз REST API позволяет отправить запрос только одному бэкенд-сервису; шлюз GraphQL генерирует план запросов для произвольного количества бэкенд-сервисов и позволяет вернуть выборки из них в одном общем ответе.
Итак, включив шлюз GraphQL в нашу систему, получим примерно такую картину:

Шлюз (он же сервис graphql-gateway) отвечает за создание плана запросов и отправки GraphQL-запросов другим нашим сервисам — не только монолиту. Наши сервисы, написанные на Go, имеют свои собственные GraphQL-схемы. Для формирования ответов на запросы мы используем gqlgen (это GraphQL-библиотека для Go).
Так как GraphQL Federation предоставляет общую GraphQL-схему, а шлюз объединяет все отдельные схемы сервисов в одну, наш монолит будет взаимодействовать с ним так же, как и любой другой сервис. Это принципиальный момент.
Далее пойдёт речь о том, как мы кастомизировали сервер Apollo GraphQL, чтобы безопасно перелезть с нашего монолита (Python) на микросервисную архитектуру (Go).
Side-by-side тестирование
GraphQL «мыслит» наборами объектов и полей определённых типов. Код, который знает, что делать с входящим запросом, как и какие данные извлечь из полей, называется распознавателем (resolver).
Рассмотрим процесс миграции на примере типа данных для assignments:

Понятно, что в реальности у нас гораздо больше полей, но для каждого поля всё будет выглядеть аналогично.
Допустим, мы хотим, чтобы это поле из монолита было представлено и в нашем новом сервисе, написанном на Go. Как мы можем быть уверены, что новый сервис по запросу вернёт те же данные, что и монолит? Для этого используем подход, аналогичный библиотеке Scientist: запрашиваем данные и у монолита, и у нового сервиса, но затем сравниваем результаты и возвращаем только один из них.
Шаг 1: Режим manual
Когда пользователь запрашивает значение поля createdDate, наш GraphQL-шлюз обращается сначала к монолиту (который, напоминаю, написан на Python).
На первом шаге нам нужно обеспечить возможность добавления поля в новый сервис assignments, уже написанный на Go. В файле с расширением .graphql должен лежать следующий код распознавателя (resolver):

Здесь мы используем Федерацию, чтобы сказать, что сервис добавляет поле createdDate к типу Assignment. Доступ к полю происходит по id. Мы также добавляем «секретный ингредиент» — директиву migrate. Мы написали код, который понимает эти директивы и создаёт несколько схем, которые GraphQL-шлюз будет использовать при принятии решения о маршрутизации запроса.
В режиме manual запрос будет адресован только коду монолита. Мы должны предусмотреть эту возможность при разработке нового сервиса. Чтобы получить значение поля createdDate, мы по-прежнему можем обращаться к монолиту напрямую (в режиме primary), а можем запрашивать у GraphQL-шлюза схему в режиме manual. Оба варианта должны работать.
Шаг 2: Режим side-by-side
После того, как мы написали код распознавателя (resolver) для поля createdDate, мы переключаем его в режим side-by-side:
12345extend type Assignment key(fields: «id») { id: ID! external createdDate: Time @migrate(from: «python», state: «side-by-side»)}
И вот теперь шлюз будет обращаться и к монолиту (Python), и к новому сервису (Go). Он будет сравнивать результаты, регистрировать случаи, в которых есть различия, и возвращать пользователю результат, полученный от монолита.
Этот режим действительно вселяет большую уверенность в том, что наша система в процессе миграции не будет глючить. За годы через наш фронтенд и бэкенд прошли миллионы пользователей и «килотонны» данных. Наблюдая за тем, как этот код работает в реальных условиях, мы можем убедиться, что даже редкие кейсы и случайные выбросы отлавливаются, а затем обрабатываются стабильно и корректно.
В процессе тестирования мы получаем вот такие отчёты.

Эту картинку при вёрстке попытайся увеличить как-то без сильной потери качества.
В них акцент сделан на случаи, когда в работе монолита и нового сервиса обнаруживаются расхождения.
Поначалу мы часто сталкивались с такими случаями. Со временем мы научились выявлять такого рода проблемы, оценивать их на критичность и при необходимости устранять.
При работе с нашими dev-серверами мы используем инструменты, которые выделяют различия цветом. Так легче анализировать проблемы и тестировать их решения.
А что по мутациям?
Возможно, у вас возник вопрос: если мы запускаем одинаковую логику и в Python, и в Go, что произойдет с кодом, который изменяет данные, а не просто запрашивает их? В терминах GraphQL это называется мутациями (mutation).
Наши side-by-side тесты не учитывают мутации. Мы рассмотрели некоторые подходы, позволяющие это сделать — они оказались более сложными, чем мы думали. Но мы разработали подход, который помогает решить саму проблему мутаций.
Шаг 2.5: Режим сanary
Если у нас есть поле или мутация, которые успешно дожили до стадии продакшна, мы включаем режим canary (канареечный деплой).
12345extend type Assignment key(fields: «id») { id: ID! external createdDate: Time @migrate(from: «python», state: «canary»)}
Поля и мутации в режиме canary будут добавлены в сервис Go для небольшого процента наших пользователей. Кроме того, канареечную схему тестируют и внутренние пользователи платформы. Это достаточно безопасный способ тестирования сложных изменений. Мы можем быстро отключить канареечную схему, если что-то не работает должным образом.
Мы используем только одну канареечную схему за раз. На практике не так много полей и мутаций одновременно находятся в канареечном режиме. Так что, я думаю, проблем не будет и дальше. Это хороший компромисс, потому что схема довольно велика (более 5000 полей), а экземпляры шлюза должны хранить в памяти три схемы — primary, manual и canary.
Шаг 3: Режим migrated
На этом шаге поле createdDate должно перейти в режим migrated:
12345extend type Assignment key(fields: «id») { id: ID! external createdDate: Time @migrate(from: «python», state: «migrated»)}
В этом режиме GraphQL-шлюз отправляет запросы только новому сервису, написанному на Go. Но в любой момент мы можем посмотреть, как обработает то же запрос монолит. Так намного легче делать деплой и откатывать изменения, если что-то пойдёт не так.
Шаг 4: Завершение миграции
После успешного деплоя нам больше не нужен код монолита для этого поля, и мы удаляем из кода распознавателя (resolver) директиву @migrate:

С этого момента выражение Assignment.createdDate шлюз будет воспринимать как получение значения поля из нового сервиса, написанного на Go.
Вот такая она — инкрементальная миграция!
И как далеко шагнули мы?
Мы завершили работу над нашей инфраструктурой side-by-side тестирования только в этом году. Это позволило нам безопасно, медленно, но верно переписать кучу кода на Go. В течение года мы поддерживали высокую доступность платформы на фоне роста объёма трафика в нашей системе. На момент написания этой статьи ~ 40% наших полей GraphQL вынесены в сервисы Go. Так что, описанный нами подход хорошо зарекомендовал себя в процессе миграции.
Даже после того, как проект будет завершен, мы сможем продолжать использовать этот подход для других задач, связанных с изменением нашей архитектуры.
P.S. Стив Коффман делал доклад на эту тему (на Google Open Source Live). Вы можете посмотреть запись этого выступления на YouTube (или просто глянуть презентацию).