Как фронтир-стартап сделал Magistral
aschensektЗнаете, я когда-то писал статьи и самое сложное для меня было придумать вступление. Сейчас я тоже натолкнулся на эту проблему: начать можно множеством разных способов, но правильно ли вы интерпретируете такое начало и смогу ли я развить тему дальше? Я могу начать с того, что Mistral объективно сделала не очень хорошую модель, галлюцинирующую на простых вопросах, странно ее позиционирует и именно об этом, мол, мы и поговорим. А могу начать с того, что когда-то в 2023 году три французских эксперта собрали стартап Mistral и создали сначала 7б модель, которая на бенчмарках показывала себя как 34б модель, потом собрали MoE LLM, которая умудрялась обходить заведомо более крупные проприетарные модели при меньшем количестве активных параметров. Все это - очевидная правда, но вот только суть статьи не в этом и для правильного понимания вопроса нужно рассмотреть и одну сторону медали, и другую.
Дисклеймер
Жирнющий такой, да. Я отдаю себе отчет в том, что больша́я часть моих подписчиков не то, чтобы хорошо разбиралась в нейросетях. Поэтому я постараюсь соблюсти некоторый баланс - первая глава, например, это сугубо исторические сведения, подкрепленные такой же, ставшей уже исторической, теорией для тех, кто по каким-то причинам этого не знал. Если вы хотите только увидеть обзор самого Magistral, читать все подряд совсем не обязательно. При этом некоторые концепции, вроде параметров, я здесь не объясняю, но объясню когда-нибудь в будущем.
Глава 1. О том, как стартап проприетарные модели обгонял
На самом деле начало звучит как анекдот. В апреле 2023 года в Париже собираются три исследователя, Артур Менш, Гийом Тампль и Тимоте Лакруа. Первый работал в Google DeepMind, второй и третий занимались разработкой LLaMA, передовой модели на то время, не будем говорить от кого, ибо та компания признана экстремистской на территории РФ. Ученые основывают свой собственный стартап, Mistral - и уже через несколько месяцев появляется Mistral 7B. Если что, циферка 7 и буковка B обозначают, что в модели 7 миллиардов параметров, и это мало, вот только модель на бенчмарках обходила ВСЕ конкурирующие открытые модели до 13 миллиардов параметров. Модель выложили в открытый доступ, причем под лицензией Apache 2.0, что значит, что ее можно было использовать без каких бы то ни было лицензионных ограничений где угодно. При этом моделька распространялась через торрент и huggingface.
Не нужно думать при этом, что у них не было денег. В июне того же года стартап получает инвестиций на 105 миллионов евро, компания оценивалась в 240 миллионов евро. В декабре 2023 стартап получает еще 385 миллионов евро от тех же инвесторов, оценивается в 2 миллиарда евро и позиционируется как соперник для ChatGPT и Bard от Google. За день до привлечения новых инвестиций компания выложила MoE-модель Mixtral 8x7B, снова через торрент, ссылку на который выложили в Твиттере стартапа. Вайб бунтарства против крупных моделей почувствовали?
Paper с моделью релизнулся на следующий день после привлечения суммы и вообще-то на нем, да и в целом на модели и ее архитектуре было бы неплохо остановиться, чтобы лучше понять, как себя позиционировал стартап в начале своего пути. Первое, что вам нужно понимать и на что нужно обратить внимание в первую очередь, это загадочная аббревиатура "MoE". MoE расшифровывается как Mixture-of-Experts, это так называемая "разреженая" архитектура модели - в противовес так называемым "плотным" моделям, которые используются обычно. Если обычную модель представить как, скажем, офис, то каждую задачу, которую делегируют этому офису будет выполнять весь офис сразу - от уборщицы, до директора. Нужно отправить один факс? Все сотрудники встали и пошли отправлять этот факс. Посчитать что-нибудь на калькуляторе? Пожалуйста, тысячи человек займутся этим. В плотных нейросетях активируются все миллиарды параметров одновременно для обработки одной задачи.
Архитектура MoE это точно такой же офис, но теперь делящийся на отделы - финансисты, программисты, лингвисты, историки. Когда в офис поступает новая задача, диспетчер (gating network) поручает ее какому-то из офисов, который специализируется именно на этой теме. Благодаря этому, работает не вся гигантская структура, а лишь небольшая ее часть.
Собственно, концепция MoE изобретена не Mistral. Ее еще в 1988 представили (и в 1991 оформили в научную статью) исследователи Роберт Джейкобс и Джеффри Хинтон. Если вы использовали году в 2016-2020 Google Translate, вы, скорее всего, видели как раз MoE, только они вставили его как отдельный слой между LSTM-слоями, развивая таким образом архитектуру GNMT (Надо бы и про эти все аббревиатуры отдельные статьи написать). Кстати, над той технологией тоже работал Джеффри Хинтон, как раз представивший в 1988 MoE.
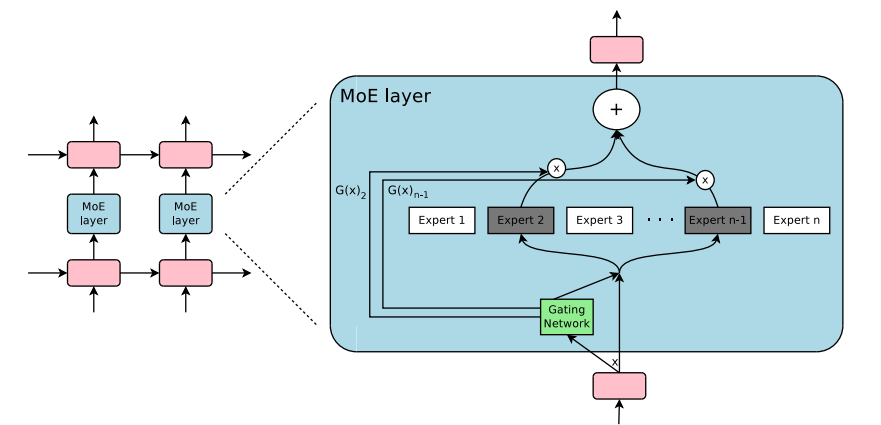
Короче, моя мысль в том, что Mistral очень хорошо популяризовали MoE. Следите за руками - у Mixtral 8x7B 8 экспертов по 7 миллиардов активных параметров, из которых Gating Network для вашей задачи выберет только двух. Это значит, что наша модель на 46.7 миллиардов параметров работает со скоростью и эффективностью модели на ~12.9 миллиардов параметров, но знаниями все на те же 46.7 миллиардов параметров. И все это обходит LLaMA 2 на 70 миллиардов параметров. А еще, я напоминаю, было выложено в твиттере.
Через два месяца после релиза происходят два интересных события. Во-первых, я начинаю увлекаться нейросетями, а во-вторых Microsoft подписывает партнерское соглашение с Mistral - инфраструктура Azure AI, уж не знаю как, но модифицируется для того, чтобы модели французского стартапа лучше работали на серверах мелкомягких. Новая модель Mistral Large показывает себя невероятно хорошо на ряде задач, включая программирование и размышления. Еще примерно через месяц выходит Mixtral 8x22B, MoE, собранная из 8 экспертов по 22 миллиарда параметров, снова релиз через твиттер, через неделю после этого Mistral подымает еще 500 миллионов евро и начинает стоить как минимум 5 миллиардов евро, через еще один месяц выходит плотная 22B модель Codestral, обученая на задачи программирования, она обходит аналогичные модели от конкурентов размерами в разы выше, через две недели после этого Mistral получает еще 600 миллионов евро и стоит теперь 5.8 миллиардов, выходит математическая модель Mathstral 7B, затем Mistral Large, которую осенью 2024 дообучают на мультимодальные задачи, что значит, что гигантская открытая модель теперь умеет воспринимать изображения.
В конце осени 2024 года Mistral нанимает своего 100 сотрудника.
Глава 2. Когда все пошло не так
На самом деле не сразу после того как Mistral наняли своего сотого сотрудника, как могло показаться, нет. Я просто решил, что это хороший способ показать, как быстро и эффективно развивался французский стартап, став реальным конкурентом лидирующих в области компаний. После этого майлстоуна были еще релизы и еще партнерства. Реальная проблема началась даже не с самой компании. Она началась, к сожалению, с политики региона, в котором стартап зародился. Задолго до того, как этот самый стартап увидел свет.
Вернемся немного назад во времени. 21 апреля 2021 года Еврокомиссия представляет новый законопроект AI Act, предназначенный для регулирования, собственно, сферы ИИ. Идея была в том, чтобы разделить рынок на сектора по рискам и ввести новые правила для них. Мы не будем разбирать каждый из уровней риска, предложенных изначально, но вспомним, что в конце 2022 начался взрывной рост популярности ChatGPT, что заставило этот самый AI Act корректировать - внести класс нейросетей General Purpose AI. Теперь, все GPAI модели обязаны предоставлять подробную техническую документацию, соблюдать закон ЕС об авторском праве, особенно в отношении обучающих данных, и публиковать краткое содержание контента, использованного для обучения. Помимо этого, самые мощные модели (критерием является вычислительная мощность, затраченная на обучение, — свыше 10^25 FLOPS) подлежат дополнительным, более строгим обязательствам. Они должны оценивать и смягчать системные риски, сообщать о серьезных инцидентах и обеспечивать высокий уровень кибербезопасности. Официально закон вступил в силу в августе 2024. В августе 2025 вступили в силу обязательства для моделей общего назначения GPAI.
11 июня 2025 года Mistral запускает Mistral Compute, собственную инфраструктурную ИИ-платформу, направленную на то, чтобы быть альтернативой провайдерам из Америки и Китая и при этом следовать регуляционным актам Евросоюза. Основная целевая аудитория - правительства стран и крупные европейские компании.
Глава 3. Magistral
Почувствовали мое умение нагонять саспенса? Вот на этом моменте вы, вероятно, задаетесь вопросом: "А причем тут вообще Magistral, мы вообще ведь про инфраструктурную платформу говорили?" На самом деле все довольно просто. Magistral стал одним из продуктов включенных в новую стратегию и направление работы бывшего стартапа. Официально, конечно, об этом никто и нигде не сообщает, но позвольте хотя бы здесь мне немного поиграть в конспирологию. Не делают так близко анонсы двух разных продуктов, если за ними не стоит единой идеи.
Magistral релизнулась в двух версиях, Small и Medium, первая на 24 миллиарда параметров, количество параметров второй не раскрывается вообще, потому что она - сугубо энтерпрайз-модель, которую локально не запустить.
Announcing Magistral — the first reasoning model by Mistral AI — excelling in domain-specific, transparent, and multilingual reasoning.
Magistral - первая CoT модель Mistral, причем еще и multilingual reasoning. Это значит, что модель должна "размышлять" на том языке, на котором ей задали вопрос.
Давайте снова разберемся в непонятных терминах и аббревиатурах. CoT значит Chain-of-Thought и ее в 2022 году предложила группа исследователей из (вы не поверите) Google. Мысль проста - если просто предложить модели немного подумать над задачей, вместо того чтобы просто требовать ответа, она дает более точные ответы. CoT-модели дообучаются на цепочках размышлений, что позволяет им думать без запроса пользователя на это. Итого, мы имеем модели, которые умеют "размышлять" и таким образом давать ответы правильнее, ценой того, что отвечать модели начинают в целом медленнее.
Побочным эффектом от этого является повышенная "прозрачность" модели. Теперь мы можем видеть цепочку рассуждений, генерируемых моделью и прикинуть, как именно она думала и где потенциально могла ошибиться. Именно "прозрачность" Magistral по-сути и афиширует своим multilingual reasoning. В этом же лично я вижу большущую проблему, но обо всем по порядку.
Давайте рассмотрим какую-нибудь небольшую CoT модель на практике - например, Qwen3 4b. Это малюсенькая reasoning-модель, которая на самом деле довольно неплохо для своего размера показывает себя в кодинге.

Прежде чем ответить, модель выстраивает цепочку рассуждений о том, каков будет ее ответ. Саму цепочку рассуждений можно скрыть, в итоге модель все равно напишет итоговый ответ.
У CoT-моделей есть два свойства, которые вам нужно понимать. Им посвящены отдельные исследования, я дам на них соответствующие ссылки. Первое - у моделей есть так называемая "оптимальная длина размышлений"
Под оптимальной длиной размышлений подразумевается количество шагов, при которых достигается пиковая производительность модели. У разных моделей оно разное, но в целом более способные модели в среднем имеют тенденцию иметь более короткую цепочку рассуждений. Так, например, Qwen2.5 1.5B имеет оптимальную цепочку в 14 шагов, версия в 72B параметров обладает оптимальной цепочкой в 4 шага. LLM склонны рассуждать заведомо более просто, предпочитая более короткие и эффективные пути рассуждения. Важно понимать, что CoT-модели демонстрируют превосходную калибровку уверенности по сравнению с обычными моделями, однако недостаточная уверенность может заставить модель пересматривать правильные шаги, что приводит к избыточным размышлениям, иногда на десятки и даже сотни шагов.

А теперь вернемся к Magistral. Мы уже увидели, как модели семейства Qwen3 в разных размерах строят цепочку рассуждений для ответа на вопрос "кто ты?" Хотите увидеть, какую цепочку построит Magistral?
Magistral заведомо более долго рассуждает, причем практически не использует информацию из рассуждений в своем ответе, вместо этого зачем-то еще и суммаризируя информацию в отдельном блоке. Эта тенденция сохраняется из ответа в ответ - цепочка размышлений модели гораздо более полезная, чем итоговый ответ.
Кстати, самое время сообщить, что я тестирую только Magistral Medium из вебморды и 4bit MLX Magistral Small, no in-between, к сожалению.
Помните, я несколькими абзацами выше рассказал, как reasoning-модели начинают очень долго думать, если они не уверены в ответе? У меня есть на такой случай тест. Есть старенький анекдот из рунета, из периода, когда еще существовал IRC, он звучит так:
— Здравствуйте, это канал об аниме?
— Да.
— Как мне пропатчить KDE2 под FreeBSD?
Шутка старая, олдфаги не помнят, ньюфаги не знают, KDE2 не существует уже очень-очень давно, поэтому модели не уверены и трясутся. Magistral, вот, натрясся аж на очень-очень много шагов:

Но это, скажете вы, не такая и важная и известная информация, и будете правы. Модель действительно не обязана знать такое. Но Magistral в целом показывает очень плохие знания о чем-то, что хоть немного выходит за рамки мейнстрима. Так, Magistral Medium из вебморды Mistral правильно ответила про имена актеров, которые играли 8, 9, 10 Докторов и Доктора-Воина из сериала Доктор Кто:

При этом, Magistral, как Small, так и Medium очень сильно любят повторять сами себя в своих рассуждениях. Например, в CoT Medium повторил актеров минимум 6 раз, а Small на момент написания этого предложения строчит фамилии уже тринадцатый раз и не планирует останавливаться. И так - абсолютно на всех задачах, как на знания, так и на логику, программирование и математику.
А еще проблема в том, что на менее популярных телешоу модель начинает галлюцинировать. Знаний у Magistral Small значительно меньше, чем у Mistral Small.
Второе свойство CoT-моделей, про которое я еще не рассказал, это то, что ризонинг у нейросетей не совсем эквивалентен рассуждениям у людей. Когда вы задаете вопрос на русском, французском или любом другом языке, модель сперва переводит его в это внутреннее, абстрактное представление. Например, при запросе "противоположность маленькому" на разных языках, внутри модели активируются одни и те же базовые нейроны, отвечающие за концепции «маленький» и «противоположность». Затем модель находит в этом пространстве концепт «большой» и только после этого переводит его обратно в нужный язык для ответа. То же самое происходит и в сложных задачах. При вопросе «Какая столица штата, в котором находится Даллас?», модель не ищет прямой ответ. Она сперва активирует концепты «Даллас находится в Техасе», а затем связывает их с концептом «столица Техаса - Остин». Эти шаги происходят в абстрактном метаязычном поле, а не на конкретном языке.
Но это не значит, что модель одинаково хорошо думает на всех языках сразу. На самом деле "метаязычное поле" это концепция, в которой превалируют высокоресурсные языки. Модели легче рассуждать на том языке, на котором она училась рассуждать и на котором в целом имеет больше знаний. Чаще всего это английский, может, китайский - но вот как модель может эффективно думать на том языке, на котором ей задают вопрос, как Magistral?
Есть такая волшебная штука, называется Cross-lingual Prompting. По сути, мы задаем модели задачу на том языке, на котором хотим, а просим построить рассуждения на другом языке. Лучшим вариантом, как мы выяснили, является любой высокоресурсный язык. Логичным продолжением такой идеи является внесение самосогласованности. Что, если заставлять модель строить не одну цепочку рассуждений, а несколько на нескольких высокоресурсных языках? Правильным ответом будем считать тот, который встречается чаще всего, а пользователю мы можем выдавать CoT на том языке, на котором он задал вопрос.
Этот подход называется Cross-lingual Self-Consistent Prompting и Magistral его не использует. Модель действительно обучали строить цепочки рассуждений на языке запроса, причем для этого аж добавили вознаграждение за языковую последовательность. Собственно, из папира:
Разработчики взяли 10% своих обучающих задач на английском и перевели их на несколько других языков, включая французский, немецкий, испанский, китайский и русский, fastText во время обучения проверял язык запроса пользователя, CoT и итогового ответа и если все сходилось, к оценке добавлялось +0.1 балл.
Что в итоге получилось? Результаты на бенчмарке AIME 2024 показывают падение производительности на неанглийских языках на 4.3–9.9% по сравнению с английской версией:
- Английский: 73.6%
- Французский: 68.5%
- Испанский: 69.3%
- Русский: 65.0%
- Китайский: 63.7%
Более того, авторы прямо предполагают, что это падение производительности может быть связано именно с тем, что они ограничили язык рассуждений.
Вообще, бенчмаркинг этой модели это отдельный прикол. Вот такие результаты бенчмарка выкладывают в релизной статье:

И это, если честно, очень плохо. Давайте обо всех показателях тут по порядку
AIME - бенчмарки с математическими задачами, у версии 24 года задания гуляют по открытым датасетам, обучить модель хорошо решать эти задания не очень сложно. У версии 25 года задания закрытые - зато есть примеры этих самых заданий. То есть Magistral-Medium (Small тут не проверяют, что забавно) показывает результат в 73,6 процента - что меньше чем у открытого Deepseek R1.
А знаете, какая открытая модель выбивает на AIME'24 результат еще выше? Ну, например, дистиллят с дипсика р1 на Qwen3 8b. Это означает, что разработчики взяли Qwen3 8b, собрали датасет на основе ответов Deepseek R1 и он дал результат в 86% на AIME'24. И эта тенденция сохраняется для AIME'25 и GPQA, на которых этот же DeepSeek-R1-0528-Qwen3-8B выбил в среднем на 10 процентов лучшие результаты, чем Magistral-Medium, который, как я напоминаю, закрытая модель, по размерам большая, чем Magistral-Small, в котором аж 24 миллиарда параметров.
Здесь разумно было бы заявить, что бенчмаркам верить не стоит, но проблема в том, что Qwen3 в меньших размерах действительно ощущается как более полезная и сбалансированная модель, чем и энтерпрайз Magistral, и локальный Magistral. Я сравнил Qwen3-4b и Magistrall Small на простейшей задаче с кодом: нужно было написать FastAPI приложение, чтобы при остановке и запуске оно писало "Привет, мир". У FastAPI для этого раньше были события startup и shutdown, но они официально признаны устаревшими. С этим у современных моделей есть проблема - они об устаревшести методов благополучно забывают и пишут так, как получается. Соответственно, запрос был такой: "Напиши мне FastAPI код который будет писать "Привет, мир" при запуске и остановке приложения. Помни, что @app.on_event() deprecated."
И знаете, Magistral Small написал код лучше. Возможно потому, что я составил не совсем верный промпт, мне нужно было упомянуть не только декоратор, но и в целом обработчики событий, но Magistral написал код согласно современному подходу:

А вот так написал Qwen3-4b:
Вот только достигнуто это было ценой цепочки размышлений из целого эссе, сожравшей чуть ли не половину контекста. А еще в другом чате, где я не упоминал, что обработчики событий устарели, Magistral все же написал код хуже:

В качестве заключения
Magistral - это та модель, которую очень удобно показать кому-нибудь и сказать "Смотрите, у Mistral тоже есть reasoning-модель", не вдаваясь в подробности относительно того, какого она качества. Я не хочу думать, что это показатель того, во что превратился французский стартап. Мне хочется верить, что это просто чья-то ошибка при загрузке весов, неудачная шутка или просто проба пера. Magistral во всех своих вариациях на данный момент - плохая модель. Вишенкой на торте я считаю то, что на странице анонса модели Mistral напоминают, что у них есть Flash Answers, технология, позволяющая инференсить модели быстрее. Это очень издевательский костыль к тому, что рассуждающая модель рассуждает просто плохо.