Как Uber применяет кэши для удержания нагрузки в 40 миллионов RPS
Alexey BykovПодробное саммари статьи How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache
Ссылки:
Введение
Статья от Uber про то, как они держат большую нагрузку, используя разные интересные решения с кэшами. Для хранения данных (десятки петабайт) и обслуживания нагрузки (десятки миллионов RPS) Uber использует свое хранилище Docstore - распределенную БД, построенную поверх MySQL. В совокупности с NVMe SSD дисками эта БД позволяет достичь низкого времени ответа и высокой пропускной способности для читающей нагрузки, однако для некоторых видов нагрузки это может быть дорого, как с точки зрения серверных ресурсов, так и с точки зрения обслуживания.
Архитектура DocStore
Docstore состоит из трех компонентов: query engine, storage engine и control plane. Query engine занимается всем, что связано с запросами: парсинг, валидация, построение плана исполнения, а также шардированием данных, маршрутизацией запросов, мониторингом состояния узлов с данными и авторизацией/аутентификацией клиентов. Storage engine отвечает за репликацию данных, транзакции, управление параллельным исполнением. Также storage engine решает задачу консенсуса с помощью алгоритма Raft в каждой из партиций, которая, как правило, состоит из трех узлов. Узел, в свою очередь, это инстанс MySQL с NVMe SSD дисками и является мастером либо одной из реплик.
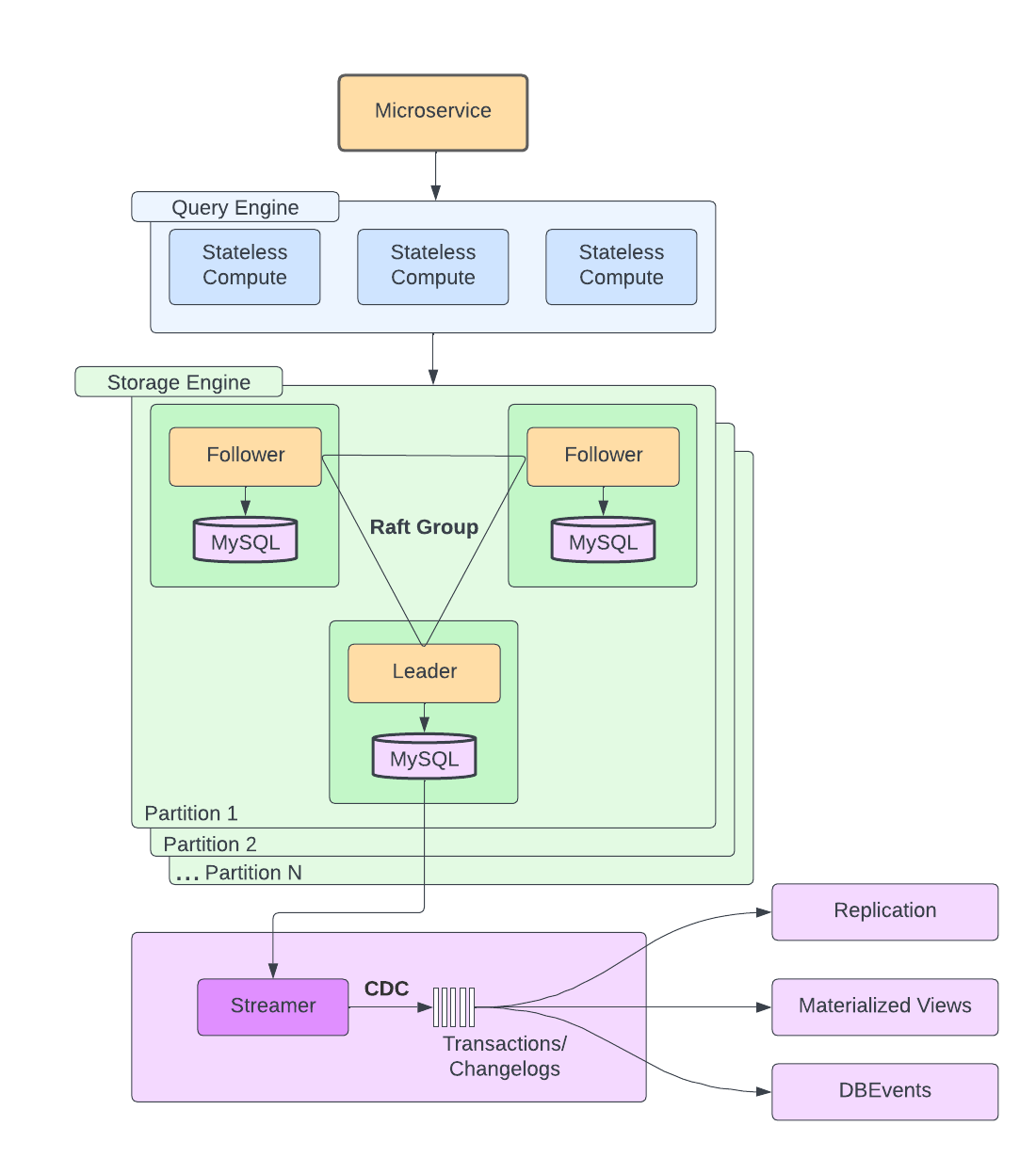
При этом, как и у любой дисковой БД, у Docstore есть ряд недостатков, которые мешают обслуживать огромную нагрузку с низким временем ответа. Во-первых, у скорости чтения данных с диска есть вполне осязаемый предел, преодолеть который невозможно. Во-вторых, несмотря на все свои возможности, вертикальное и горизонтальное масштабирование имеют сопутствующие проблемы, например, в результате шардирования могут появиться "горячие" партиции/шарды, на которые будет идти сильно бОльшая нагрузка, чем на остальные. Про проблему горячих ключей/партиций/шардов есть интересный пример от Twitter, про который я писал здесь. В-третьих, существует сильный дисбаланс читающей и пишущей нагрузки, что может приводить к ухудшению времени ответа в узлах MySQL, которые Docstore использует под капотом.
Для преодоления описанных сложностей в Uber многие команды прибегали к подходу с кэшированием, используя Redis в качестве кэширующих узлов. Основной паттерн использования кэша следующий: при записи данные пишутся как в основное хранилище, так и в кэш, а при чтении достаются из кэша, что позволяет получить низкие тайминги обработки запросов. При этом каждой команде приходилось поддерживать инстансы Redis, реализовывать логику инвалидации данных в кэше в каждом микросервисе, а также реализовывать механизм репликации данных в кэше на случай потери одной из локаций (англ. availability zone), либо же получать деградацию во времени обслуживания запросов, пока кэши в другой локации "прогреваются". Для решения проблемы с тем, что каждая команда тратит время на написание и поддержку собственных решений для кэширования данных из БД в in-memory хранилище, в Uber создали централизованное решение CacheFront, которое сразу интегрировали с Docstore.
Зачем придумали CacheFront
Создатели CacheFront хотели решить сразу несколько проблем. Во-первых, уменьшить утилизацию дорогого железа, требуемого для узлов Docstore, за счет использования более дешевых хостов, на которых можно развернуть кэширующие узлы. Снятие существенной нагрузки непосредственно с БД позволяет не заниматься дорогостоящим масштабированием storage engine компонента Docstore. Во-вторых, улучшить время обработки запросов в p50 и p99 (в медиане и в 99-персентиле), а также уменьшить количество всплесков таймингов при небольших всплесках нагрузки. В-третьих, улучшить разработческий опыт при использовании кэшей: заменить кастомные решения, созданные в отдельных командах, на централизованное решение, а также забрать ответственность за код и инфраструктуру, связанные с кэшированием, из продуктовых команд в команду Docstore; интегрировать логику кэширования в основной клиент Docstore, минимизируя при этом количество бойлерплейт-кода, который потребуется писать продуктовым командам. В-четвертых, максимально развязать логику кэширующего слоя и storage engine, чтобы их можно было независимо масштабировать, а также не создавать проблемы с горячими партициями при неравномерном шардировании.
Look Aside кэширование в сценарии ReadRows
В первую очередь, в CacheFront добавили поддержку самого простого и распространенного сценария - ReadRows (чтение строк по первичному ключу). Логика работы с кэшом была добавлена в Query Engine, что было максимально удобно для микросервисов, которые уже используют клиент Docstore - достаточно только передавать с запросами opt-in параметр использования данных из кэша. По-умолчанию включать использование закэшированных данных опасно, т.к. это может сломать логику, опирающуюся на согласованность данных.
Для чтений используется стратегия cache aside (также известная, как look aside):
- query engine получает запрос на чтение одной или нескольких строк
- query engine проверяет наличие записей в кэше (инстанс Redis), если какие-то записи есть в кэше - query engine сразу начинает отправлять эти данные клиенту (англ. streaming, потоковая передача данных)
- если части строк не оказалось в кэше, query engine запрашивает их в storage engine
- после получения оставшихся данных из storage engine они отправляются на клиент, а также асинхронно записываются в кэширующий слой
Комментарий от меня: каждый раз, когда я встречаю этот простой, но популярный подход, я занудно напоминаю, что он несет в себе серьезные риски для надежности, т.к. при отказе кэша нагрузка на БД может вырасти в несколько раз и даже на порядки (при высоком hit-ratio). Для осознания проблемы крайне рекомендую статью Metastable Failures in Distributed Systems, там же есть отдельный параграф 2.2 как раз про look aside кэширование.
Инвалидация кэша
Как известно, проблема инвалидации данных в кэше - одна из самых сложных в компьютерных науках. По-умолчанию, у каждой записи в кэше есть время жизни - TTL (англ. TTL - time to live), после которого запись считается устаревшей и подлежит удалению. Для каких-то сценариев можно выбрать общий дефолт для TTL, например, 5 минут и кэш будет как-то работать. Однако большинство пользователей конечно хотели бы, чтобы изменения данных прорастали из БД в кэш значительно быстрее, чем время TTL. Можно уменьшать дефолтное значение TTL, но это приведет к уменьшению эффективности кэша за счет более быстрого "протухания" данных и, как следствие, снижения hit-ratio.
На первый взгляд, можно было бы инвалидировать записи в кэше при выполнении запросов на изменение (например, UPDATE/DELETE), но есть запросы, изменяющие записи по некоторому предикату, который проверяется непосредственно в БД при выполнении изменения записи (англ. conditional update). Для таких запросов реализовать логику инвалидации на уровне query engine уже не представляется возможным.
Change Data Capture
Для решения проблемы инвалидации данных в частности, да и вообще проблемы согласованности данных в кэше, в Uber используют механизм CDC (англ. Change Data Capture), позволяющий распространять в кэширующие узлы изменения в данных за секунды, а не ждать минуты TTL в схеме без CDC.
В схеме с CDC, однако, появляется новая сложность. Теперь запись в кэш может происходить в двух местах: в query engine на последнем шаге стратегии cache aside (асинхронная запись данных, полученных из БД, в кэш), а также с помощью механизма CDC. Таким образом, возможна гонка данных, а именно, более старая версия данных может оказаться в кэше, если будет записана последней. Для избежания подобных проблем при обновлении учитывается версия данных (конкретно, время последнего изменения), т.е. более устаревшие изменения не попадают в кэш, если там присутствуют более актуальные записи.
В дополнение к описанному механизму, в CacheFront существует API для явной инвалидации данных. Это полезно в сценариях, где требуется более строгая согласованность данных, например, read-own-writes. Это возможно для точечных обновлений, например, по первичному ключу, но уже упомянутый сценарий с conditional updates все еще требует других механизмов инвалидации, поэтому отказаться от CDC не удается.
Замер результатов
Для того, чтобы измерить, насколько хорошим получилось решение с CDC, в CacheFront был добавлен специальный режим, в котором читающие запросы всегда дублировались в БД и сравнивались с данными в кэше в фоновом режиме. По логам совпадений/различий считался процент совпадений от общего числа запросов, который можно считать метрикой согласованности кэша и БД. Для схемы с CDC эта метрика получилась равной 99.99%.
Прогрев кэша
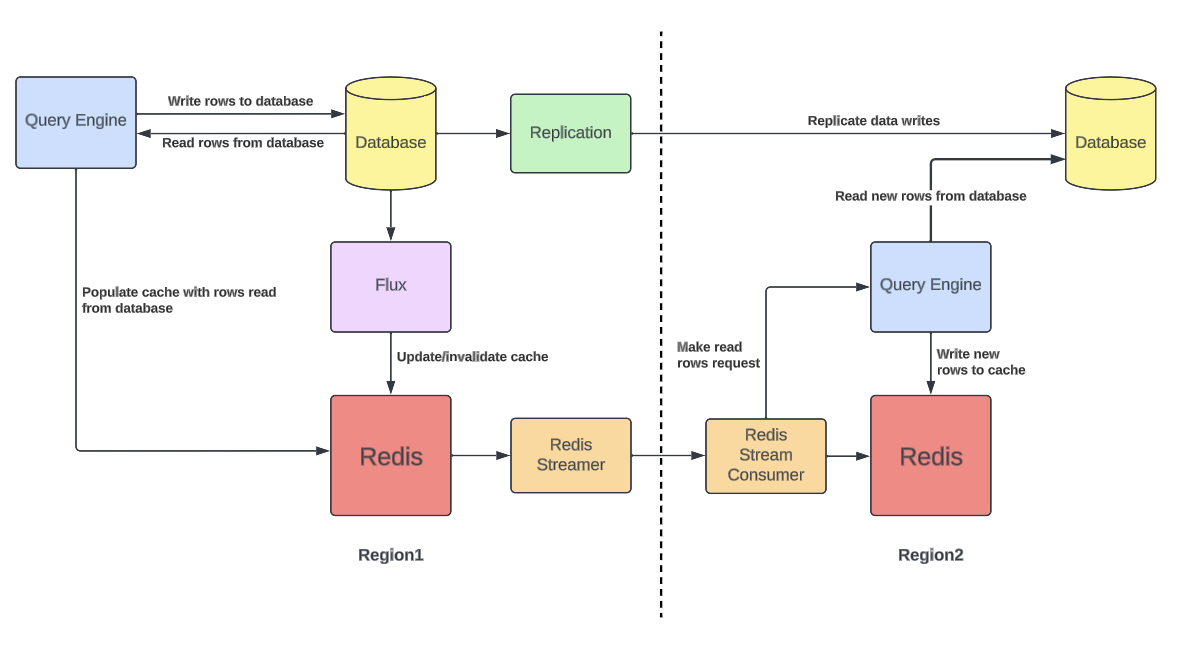
DocStore развернут в двух географически разделенных регионах для обеспечения высокой доступности и повышения отказоустойчивости. Изменения данных реплицируются между регионами, а при отказе одного из регионов второй должен уметь обслуживать все запросы. При отказе одного из регионов возникает проблема: запросы резко перенаправляются в оставшийся регион, но его кэши не прогреты под эту нагрузку. Таким образом, в момент переключения трафика в другой регион получаем резкий рост нагрузки на БД из-за непрогретого кэша.
Для решения проблемы прогрева кэша между регионами можно было бы воспользоваться механизмом репликации в Redis. Но в таком случае одновременно работали бы два механизма репликации данных между регионами: один от Redis, второй от самого DocStore. В таком сценарии возникала бы неконсистентность данных между DocStore и Redis.
Вместо этого в Uber используют следующий подход. Подписываемся на поток изменений Redis в одном регионе и отправляем в другой регион только измененные ключи (без значений). В другом регионе читаем ключи из этого потока и для каждого ключа инициируем читающий запрос через кэширующий слой. Если значения по ключу нет в кэше, данные будут загружены из БД и сохранены в кэш. Отправка только ключей между регионами позволяет уменьшить нагрузку на сеть, а также сохранить консистентность данных в БД и кэше внутри одного региона.
Негативное кэширование
Если читающая нагрузка содержит много запросов по несуществующим в БД ключам, то в этих запросах будут постоянно случаться cache misses и все эти запросы будут проливаться в БД. В таком сценарии имеет смысл кэшировать факт отсутствия ключа в БД. Для этого можно завести отдельный флаг - индикатор того, что данные по ключу отсутствуют (англ. negative caching). С этим подходом, однако, можно наступить на грабли, как это сделал Twitter, когда из-за негативного кэширования на 12 часов пропал аккаунт популярной спортивной команды (можно почитать в этом посте).
Шардирование
При больших нагрузках и/или большом объеме данных для работы кэша может не хватить одного кластера Redis. Масштабирование за счет узлов одного кластера часто упирается в лимиты Redis. Поэтому одна инсталляция DocStore может использовать несколько кластеров Redis для кэша. Шардирование Redis позволяет повысить отказоустойчивость кэша, т.к. при отказе одного кластера только для части ключей придется использовать БД для обслуживания запросов.
Получается, что есть две схемы шардирования: данных в инстансах БД и ключей кэша в Redis. Если эти схемы шардирования сделать одинаковыми, то снова может возникнуть проблема горячей партиции: если откажет кластер Redis, то все запросы по ключам с этого кластера будут направляться в БД. Если схемы шардирования одинаковые, то все запросы уйдут на один шард БД и перегрузят его. Чтобы избежать подобной проблемы, Uber специально использует разные ключи для шардирования в кэше и в БД. В таком случае при отказе кластера Redis запросы по ключам с этого кластера равномерно "размажутся" по всем шардам БД и не перегрузят ее.
Circuit Breaker
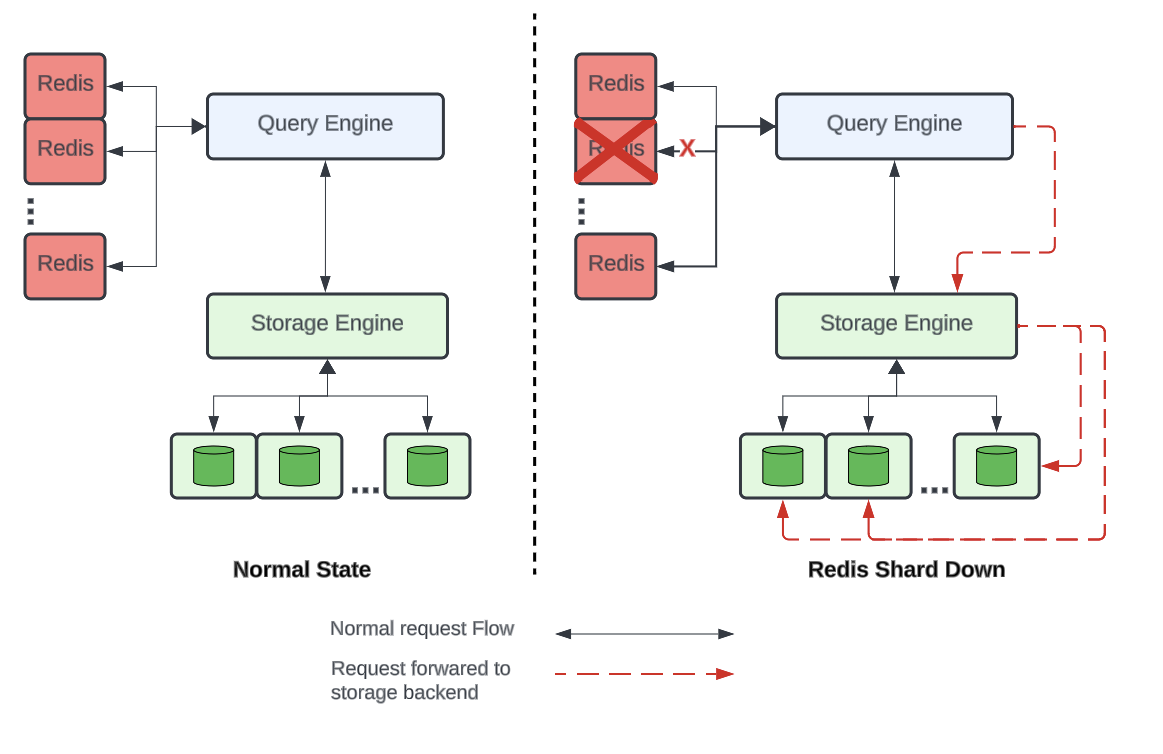
В ситуациях, когда узлы Redis начинают деградировать или полностью выходят из строя, с них снимается нагрузка, частично или полностью, в зависимости от процента ошибок при обработке запросов данным узлом. Ошибки считаются в скользящем окне, данные из уже прошедших интервалов времени (но еще попадающих в окно) учитываются, но с меньшим весом.
Тут видим классический паттерн Circuit Breaker, однако, по моему опыту, его целью чаще называют снятие нагрузки с проблемного узла системы, чтобы дать ему восстановиться. В статье же сделан акцент на том, что подход с Circuit Breaker'ом позволяет сэкономить тайминги обработки запроса, не делая бесполезный запрос в узел Redis, который скорее всего не ответит, и в любом случае придется делать запрос в БД.
Адаптивные таймауты
Выбор подходящих таймаутов запросов в Redis оказался не самой тривиальной задачей. Если выставить таймаут слишком низким, может значительно вырасти процент запросов, которые не будут обслужены кэшом и придется делать запрос в БД, повышая нагрузку на нее. Если выставить таймаут слишком высоким, появится проблема tail latency (задержка высоких персентилей) - некоторая доля запросов будет исчерпывать этот большой таймаут и приводить к высоким таймингам клиентов.
Здесь Uber предлагает вычислять таймаут динамически по персентилям времени ответа кэширующих узлов. Например, брать p99.99 времени ответа кэша в качестве динамического таймаута. Тогда 99.99% запросов будут успевать обслуживаться из кэша, а для оставшихся 0.01% при истечении таймаута запрос в Redis будет отменен и будет сделан запрос в БД.
Таким образом, адаптивные таймауты позволяют контролировать какой персентиль запросов будет обслуживаться быстро из кэша, явно задавая этот персентиль таймингов в качестве таймаута. При этом, конечно, все равно есть максимальное значение таймаута для сценария, когда Redis начнет отвечать очень долго из-за деградации.
Результаты
В итоге, Uber создали классное решение: чтение из кэша по сравнению с прямым чтением из БД позволило снизить тайминги обработки запросов, а также побороть проблему всплесков таймингов, особенно в высоких персентилях. Удалось добиться хорошей консистентности данных, в том числе в кросс-региональных инсталляциях. Трюки с шардированием и прогревом кэшей позволило добиться хорошей отказоустойчивости. Наконец, решение с кэшом в Redis позволило сильно сэкономить на серверных ресурсах: для обслуживания 6 миллионов RPS прямыми запросами в БД требовалось 60 тысяч ядер CPU, а кэш в Redis позволяет обслуживать 99.9% этой нагрузки на 3 тысячах ядер CPU.