Изучаем Linux Bridge
Виртуальные Ethernet-устройства отлично подходят для передачи трафика между сетевыми namespace. Но когда нужно связать больше namespace, создание veth для такого «паучьего» трафика быстро становится не масштабируемым и сложным в сопровождении. И вот тут на сцену выходит linux bridge.
В этом посте мы разберёмся, как создать linux bridge и включить передачу трафика между четырьмя сетевыми namespace.
Прежде всего убедитесь, что у вас установлен Vargrant
Немного базы по network namespaces, veth и бриджам (вот прям совсем немного)
Network namespaces - это способ создавать изолированные сетевые окружения внутри Linux-системы. Они позволяют процессам иметь собственный сетевой стек: с интерфейсами, таблицами маршрутизации и правилами файрвола. Такая изоляция гарантирует, что процессы в одном сетевом namespace никак не влияют на процессы в других.
- Network namespaces предоставляют изолированные экземпляры сетевого стека, интерфейсов и таблиц маршрутизации в Linux.
Что такое Veth-устройства?
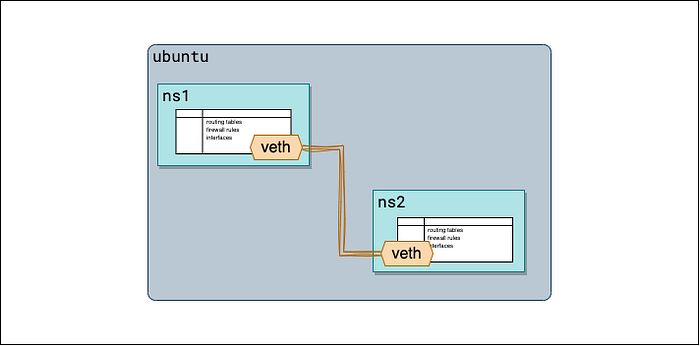
Veth-устройства - это пары виртуальных сетевых интерфейсов, которые используются для соединения сетевых namespace между собой. Каждая такая пара состоит из двух концов: один находится в одном namespace, второй - в другом. Эти виртуальные интерфейсы ведут себя как обычный Ethernet-кабель и обеспечивают связь между подключёнными namespace. Трафик может проходить через такую veth-пару в обе стороны.
Veth-устройства - это виртуальные сетевые интерфейсы, которые всегда идут парами и используются для соединения сетевых namespace.
Что такое Linux Bridge?
Linux bridge - это программный компонент в ядре Linux, который позволяет создавать сетевой мост. Сетевой мост - это соединение двух или более сетевых интерфейсов, благодаря которому они работают как один сетевой сегмент. Он функционирует на канальном уровне (Layer 2) модели OSI и умеет пересылать сетевой трафик между подключёнными интерфейсами.
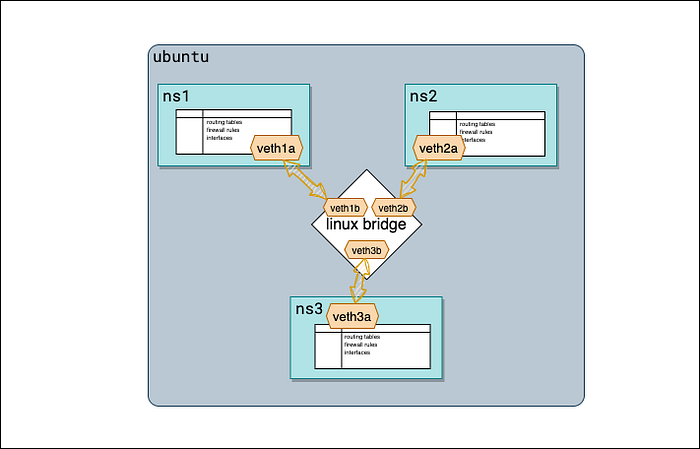
Управлять Linux bridge можно с помощью разных инструментов и команд. Классический вариант - утилита командной строки brctl, которую часто используют для создания, настройки и управления мостами. Кроме того, в более новых версиях Linux-дистрибутивов доступны современные сетевые инструменты - команды ip и bridge.
В итоге Linux bridge даёт гибкий и эффективный способ соединять сетевые интерфейсы и обеспечивать сетевое взаимодействие между разными устройствами или виртуальными окружениями внутри Linux-системы.
Linux bridge соединяет сетевые интерфейсы, позволяя устройствам общаться так, как будто они находятся в одной сети.
Подготовка окружения
Прежде чем переходить к созданию и настройке сетевых namespace и veth-устройств, нужно подготовить окружение. Для этого мы воспользуемся Vagrant и поднимем новую Ubuntu-машину внутри вашей системы.
$ curl -s https://gist.githubusercontent.com/amazingandyyy/352e20f6f757b4519412d03261609f30/raw/b6738afa90dd13869e1a3969b813134050c647bb/ubuntu.Vagrantfile > Vagrantfile $ vagrant up ... $ vagrant ssh
На этом этапе у вас будет готовая виртуальная машина, в которой можно спокойно экспериментировать с сетевыми настройками.
Создание netns, veth и моста
Шаг 1: создаём сетевые namespace
Создадим 4 сетевых namespace с помощью команды ip netns add:
$ sudo ip netns add ns1 $ sudo ip netns add ns2 $ sudo ip netns add ns3 $ sudo ip netns add ns4
Проверим, что всё создалось корректно:
$ ip netns list ns4 ns3 ns2 ns1
После создания можно использовать ip netns list, чтобы убедиться, что у нас есть 4 сетевых namespace.
Шаг 2: создаём veth-пары
Теперь создадим четыре пары виртуальных Ethernet-интерфейсов (veth). Каждая пара состоит из двух интерфейсов: стороны a и стороны b. Для этого используем команду
sudo ip link add <veth-name> type veth peer name <veth-peer-name>.
$ sudo ip link add veth1a type veth peer name veth1b $ sudo ip link add veth2a type veth peer name veth2b $ sudo ip link add veth3a type veth peer name veth3b $ sudo ip link add veth4a type veth peer name veth4b
Проверим результат:
$ ip a
...
4: veth1b@veth1a: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether c6:9c:e9:44:e9:a4 brd ff:ff:ff:ff:ff:ff
5: veth1a@veth1b: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 96:2a:20:a7:24:33 brd ff:ff:ff:ff:ff:ff
6: veth2b@veth2a: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 8a:f7:c1:cc:92:57 brd ff:ff:ff:ff:ff:ff
7: veth2a@veth2b: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 22:18:45:92:3c:a2 brd ff:ff:ff:ff:ff:ff
8: veth3b@veth3a: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 56:a0:aa:30:e5:85 brd ff:ff:ff:ff:ff:ff
9: veth3a@veth3b: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether a6:12:07:93:fb:7f brd ff:ff:ff:ff:ff:ff
10: veth4b@veth4a: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether f2:a3:71:00:56:dd brd ff:ff:ff:ff:ff:ff
11: veth4a@veth4b: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 0a:5b:4d:65:5d:f7 brd ff:ff:ff:ff:ff:ff
После создания используйте команду ip address (или сокращённо ip a), чтобы вывести все доступные интерфейсы на Ubuntu-машине. Здесь видно 4 veth-пары, которые мы только что создали - это интерфейсы с 4-го по 11-й.
Шаг 3: переносим veth-пары в соответствующие network namespace
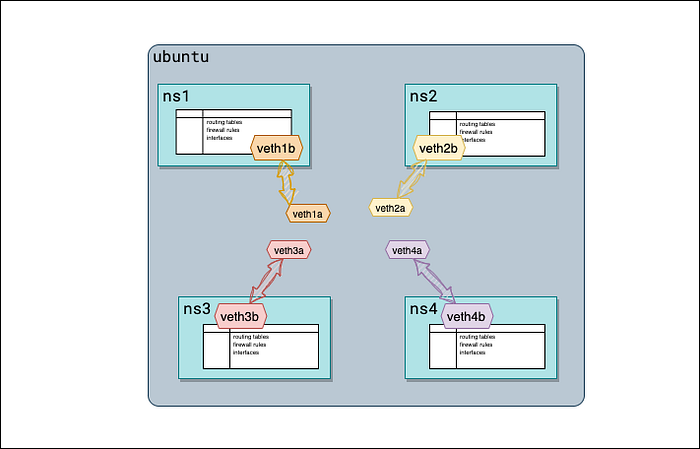
Теперь перенесём сторону “b” каждой veth-пары в нужный сетевой namespace:
$ sudo ip link set veth1b netns ns1 $ sudo ip link set veth2b netns ns2 $ sudo ip link set veth3b netns ns3 $ sudo ip link set veth4b netns ns4
Также поднимем все veth-интерфейсы с обеих сторон:
$ sudo ip netns exec ns1 sudo ip link set dev veth1b up $ sudo ip netns exec ns2 sudo ip link set dev veth2b up $ sudo ip netns exec ns3 sudo ip link set dev veth3b up $ sudo ip netns exec ns4 sudo ip link set dev veth4b up $ sudo ip link set dev veth1a up $ sudo ip link set dev veth2a up $ sudo ip link set dev veth3a up $ sudo ip link set dev veth4a up
Проверим, что всё настроено правильно:
$ sudo ip netns exec ns2 ip a
...
6: veth2b@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 8a:f7:c1:cc:92:57 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::88f7:c1ff:fecc:9257/64 scope link
valid_lft forever preferred_lft forever
На этом этапе каждый namespace уже имеет свой veth-интерфейс, и все они находятся в состоянии UP.
Шаг 4: создаём мост
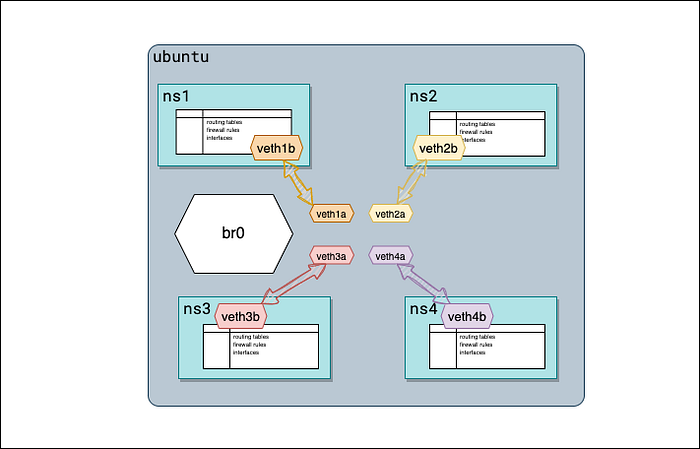
Создадим Linux bridge с именем br0 с помощью команды ip link:
$ sudo ip link add br0 type bridge
Проверим, что мост создан:
$ brctl show br0 bridge name bridge id STP enabled interfaces br0 8000.000000000000 no
Теперь поднимем мост br0 и снова убедимся, что всё в порядке:
$ sudo ip link set dev br0 up
Проверка:
$ ip a
...
12: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether ea:24:60:f9:1f:c7 brd ff:ff:ff:ff:ff:ff
inet6 fe80::e824:60ff:fef9:1fc7/64 scope link tentative
valid_lft forever preferred_lft forever
На этом шаге мост br0 уже создан и находится в состоянии UP, готовый принимать интерфейсы.
Шаг 5: подключаем veth к мосту
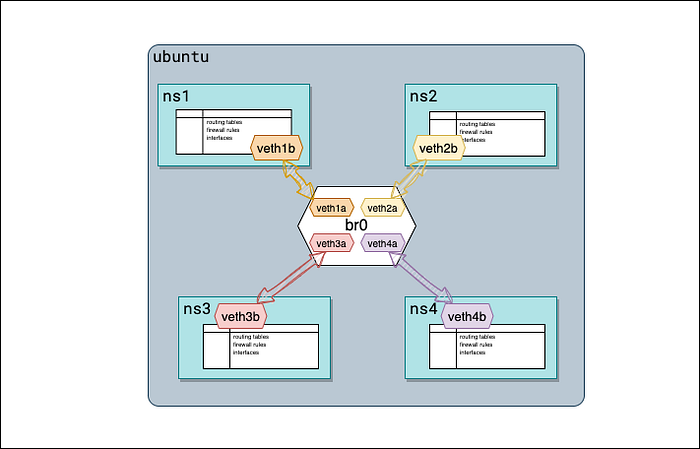
Подключим все интерфейсы стороны “a” каждой veth-пары к мосту br0. Для этого используем команду
ip link set master <bridge-name> dev <veth-device-name>, а затем посмотрим результат через brctl.
$ sudo ip link set master br0 dev veth1a $ sudo ip link set master br0 dev veth2a $ sudo ip link set master br0 dev veth3a $ sudo ip link set master br0 dev veth4a
Проверяем конфигурацию:
$ brctl show br0
bridge name bridge id STP enabled interfaces
br0 8000.0270685bd117 no veth1a
veth2a
veth3a
veth4a
Либо можно воспользоваться более новой командой bridge, чтобы посмотреть детали. Лично мне в этом случае больше нравится brctl, но он есть не на каждой машине, так что полезно знать оба варианта.
$ bridge link 5: veth1a@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 7: veth2a@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 9: veth3a@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 11: veth4a@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
Шаг 6: назначаем IP-адреса стороне “b”
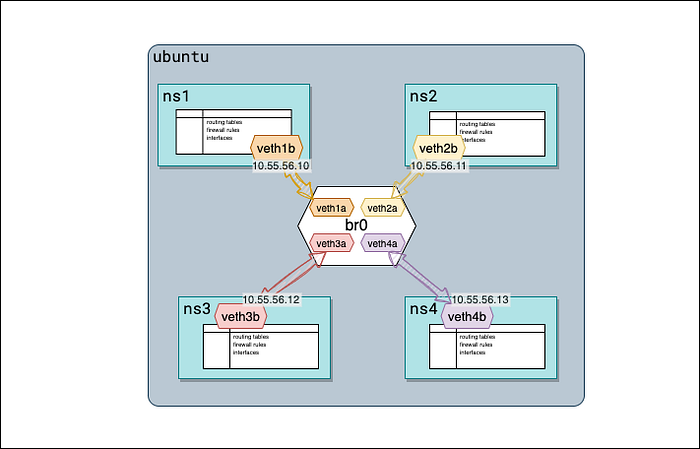
Теперь назначим IP-адреса интерфейсам стороны “b” каждой veth-пары внутри соответствующих сетевых namespace:
$ sudo ip netns exec ns1 ip addr add 10.55.56.10/24 dev veth1b $ sudo ip netns exec ns2 ip addr add 10.55.56.11/24 dev veth2b $ sudo ip netns exec ns3 ip addr add 10.55.56.12/24 dev veth3b $ sudo ip netns exec ns4 ip addr add 10.55.56.13/24 dev veth4b
На этом шаге все namespace оказываются в одной подсети и готовы к обмену трафиком через мост.
Установившийся трафик

$ sudo ip netns exec ns4 ping 10.55.56.10 PING 10.55.56.10 (10.55.56.10) 56(84) bytes of data. 64 bytes from 10.55.56.10: icmp_seq=1 ttl=64 time=0.101 ms 64 bytes from 10.55.56.10: icmp_seq=2 ttl=64 time=0.171 ms 64 bytes from 10.55.56.10: icmp_seq=3 ttl=64 time=0.107 ms
Инспектируем трафик
Мы можем посмотреть каждый компонент, через который проходит трафик. В нашем случае это veth4b, veth4a, br0, veth1a и veth1b.
Со стороны br0:
$ sudo tcpdump -vvvvln -i br0
tcpdump: listening on br0, link-type EN10MB (Ethernet), capture size 262144 bytes
04:54:01.018478 IP (tos 0x0, ttl 64, id 47668, offset 0, flags [DF], proto ICMP (1), length 84)
10.55.56.13 > 10.55.56.10: ICMP echo request, id 23824, seq 1, length 64
04:54:01.018606 IP (tos 0x0, ttl 64, id 11081, offset 0, flags [none], proto ICMP (1), length 84)
10.55.56.10 > 10.55.56.13: ICMP echo reply, id 23824, seq 1, length 64
04:54:02.049880 IP (tos 0x0, ttl 64, id 47826, offset 0, flags [DF], proto ICMP (1), length 84)
Со стороны veth1a:
$ sudo tcpdump -vvvvln -i veth1a
tcpdump: listening on veth1a, link-type EN10MB (Ethernet), capture size 262144 bytes
04:47:59.379378 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 10.55.56.10 tell 10.55.56.13, length 28
04:47:59.379394 ARP, Ethernet (len 6), IPv4 (len 4), Reply 10.55.56.10 is-at c6:9c:e9:44:e9:a4, length 28
04:47:59.379407 IP (tos 0x0, ttl 64, id 49340, offset 0, flags [DF], proto ICMP (1), length 84)
10.55.56.13 > 10.55.56.10: ICMP echo request, id 23761, seq 1, length 64
04:47:59.379420 IP (tos 0x0, ttl 64, id 57815, offset 0, flags [none], proto ICMP (1), length 84)
10.55.56.10 > 10.55.56.13: ICMP echo reply, id 23761, seq 1, length 64
04:48:00.386131 IP (tos 0x0, ttl 64, id 49533, offset 0, flags [DF], proto ICMP (1), length 84)
Заглянем внутрь моста
Поскольку мост находится в центре всего трафика, мы можем посмотреть, как именно br0 пересылает пакеты. Под капотом Linux bridge использует небольшую базу данных под названием FDB (forwarding database).
$ bridge fdb show br br0 ---> c6:9c:e9:44:e9:a4 dev veth1a master br0 96:2a:20:a7:24:33 dev veth1a vlan 1 master br0 permanent 96:2a:20:a7:24:33 dev veth1a master br0 permanent 33:33:00:00:00:01 dev veth1a self permanent 01:00:5e:00:00:01 dev veth1a self permanent 33:33:ff:a7:24:33 dev veth1a self permanent 22:18:45:92:3c:a2 dev veth2a vlan 1 master br0 permanent 22:18:45:92:3c:a2 dev veth2a master br0 permanent 33:33:00:00:00:01 dev veth2a self permanent 01:00:5e:00:00:01 dev veth2a self permanent 33:33:ff:92:3c:a2 dev veth2a self permanent 56:a0:aa:30:e5:85 dev veth3a master br0 a6:12:07:93:fb:7f dev veth3a vlan 1 master br0 permanent a6:12:07:93:fb:7f dev veth3a master br0 permanent 33:33:00:00:00:01 dev veth3a self permanent 01:00:5e:00:00:01 dev veth3a self permanent 33:33:ff:93:fb:7f dev veth3a self permanent ---> f2:a3:71:00:56:dd dev veth4a master br0 0a:5b:4d:65:5d:f7 dev veth4a vlan 1 master br0 permanent 0a:5b:4d:65:5d:f7 dev veth4a master br0 permanent 33:33:00:00:00:01 dev veth4a self permanent 01:00:5e:00:00:01 dev veth4a self permanent 33:33:ff:65:5d:f7 dev veth4a self permanent 33:33:00:00:00:01 dev br0 self permanent 01:00:5e:00:00:6a dev br0 self permanent 33:33:00:00:00:6a dev br0 self permanent 01:00:5e:00:00:01 dev br0 self permanent 33:33:ff:f9:1f:c7 dev br0 self permanent
Те две строки, которые я отметил стрелками --->, - это как раз то, чему мост научился в процессе установления трафика.
Подведём итоги
В этой статье мы разобрали концепции сетевых namespace, виртуальных Ethernet-устройств (veth) и Linux Bridge. Мы создали изолированные сетевые окружения, связали их между собой с помощью linux bridge и понаблюдали за тем, как ходит трафик. Все эти концепции лежат в основе сетевой виртуализации и изоляции и дают мощный набор инструментов для самых разных сетевых сценариев.