Инструкция по работе с Research Rabbit
Казун Антон, telegram-канал Стажер-ИИсследовательResearch Rabbit: введение
Research Rabbit — это новое и бесплатное приложение на основе ИИ, которое умеет строить сети взаимосвязей между научными статьями.
Приложение позволяет решать следующие задачи:
- Быстро находить новые релевантные источники
- Очень точно выделять "ядро" научной дискуссии по вашей теме (что читать обязательно, а что факультативно)
- Находить смежные с вашим полем темы, про которые вы раннее не думали
- Совместно с соавторами работать с научной литературой
В целом Research Rabbit позволяет за 10-15 минут собрать хороший и полный список литературы по совершенно новой для вас теме, на что в прежние времена могло уходить много часов кропотливой работы.
Ниже представлена краткая инструкция по работе с примером для иллюстрации. Однако приложение интуитивно понятно и его легко можно освоить и без инструкции.
Инструкция
Шаг 1. Регистрация
Заходим на https://researchrabbitapp.com/ и регистрируемся. Ресурс полностью бесплатный. При регистрации нужно указать e-mail, придумать логин и пароль. На следующей странице ввести имя, должность/место учебы или работы, сферу интересов, и информацию о том, откуда вы узнали про ресурс.

Шаг 2. Создаем новую коллекцию
Перед нами рабочее пространство приложения. В левом верхнем углу есть три кнопки — "новая коллекция", "новая категория" и "связать с Zotero". Нас будет интересовать первая кнопка. К связи с Zotero мы вернемся в конце инструкции, а "New Category" просто создает новую группу для нескольких коллекций, чтобы нам было удобно сортировать подборки литературы, когда их станет много.

Вы можете создать коллекцию по своей теме.
Для примера мы создадим коллекцию "Determinants of Crime" и будем работать над вопросом о социально-экономических детерминантах преступности.
Шаг 3. Наполняем коллекцию
Мы создали новую коллекцию, но там пока ничего нет. Чтобы добавить туда статьи, нужно нажать на большую зеленую кнопку "Add Papers"

Есть много способов добавить статьи: по названию, по DOI (уникальный идентификатор статьи), по PMID (аналог DOI для медицинских публикаций), по ключевым словам (это скорее поиск, чем добавление конкретной статьи). Также можно взять целую коллекцию из Zotero (прямой интеграции с Mendeley пока нет) или загрузить сразу библиографический список (например, в формате BibTeX; в том числе такой список можно создать из Mendeley, если вы им пользуетесь).

Мы пока пойдем самым простым путем — добавим несколько статей по названию. Через DOI было бы надежнее, поскольку у нескольких статей могут быть похожие названия, но здесь мы посмотрим, как приложение с этим справится.
Какие статьи добавлять? Желательно взять те тексты, про которые вы точно знаете, что они относятся к интересующей вас теме.
Но преимущество Research Rabbit состоит в том, что можно начать почти из любой точки (вернее, нескольких текстов). Пойдем в Goolge Sholar и возьмем первые пять текстов, которые нам выдаст поиск по запросу "socio-economic determinants of crime ". Это безусловно не самый правильный способ искать релевантную научную литературу, если бы мы действовали традиционным методом подготовки обзора, то это было бы ошибкой (далее будет понятно почему).

Вводим название первой статьи, нажимаем "Поиск".

Приложение само ищет статью. К счастью есть только одно совпадение, оно правильное, добавляем ее к коллекции. Затем повторяем процедуру для всех текстов. С третьей и пятой статьями он предложил несколько исследований на выбор (чего не произошло бы, используй мы DOI), но найти и добавить нужный вариант не составляет труда.
Теперь в нашей библиотеке есть пять статей. Они отображаются во втором столбике (см. ниже).
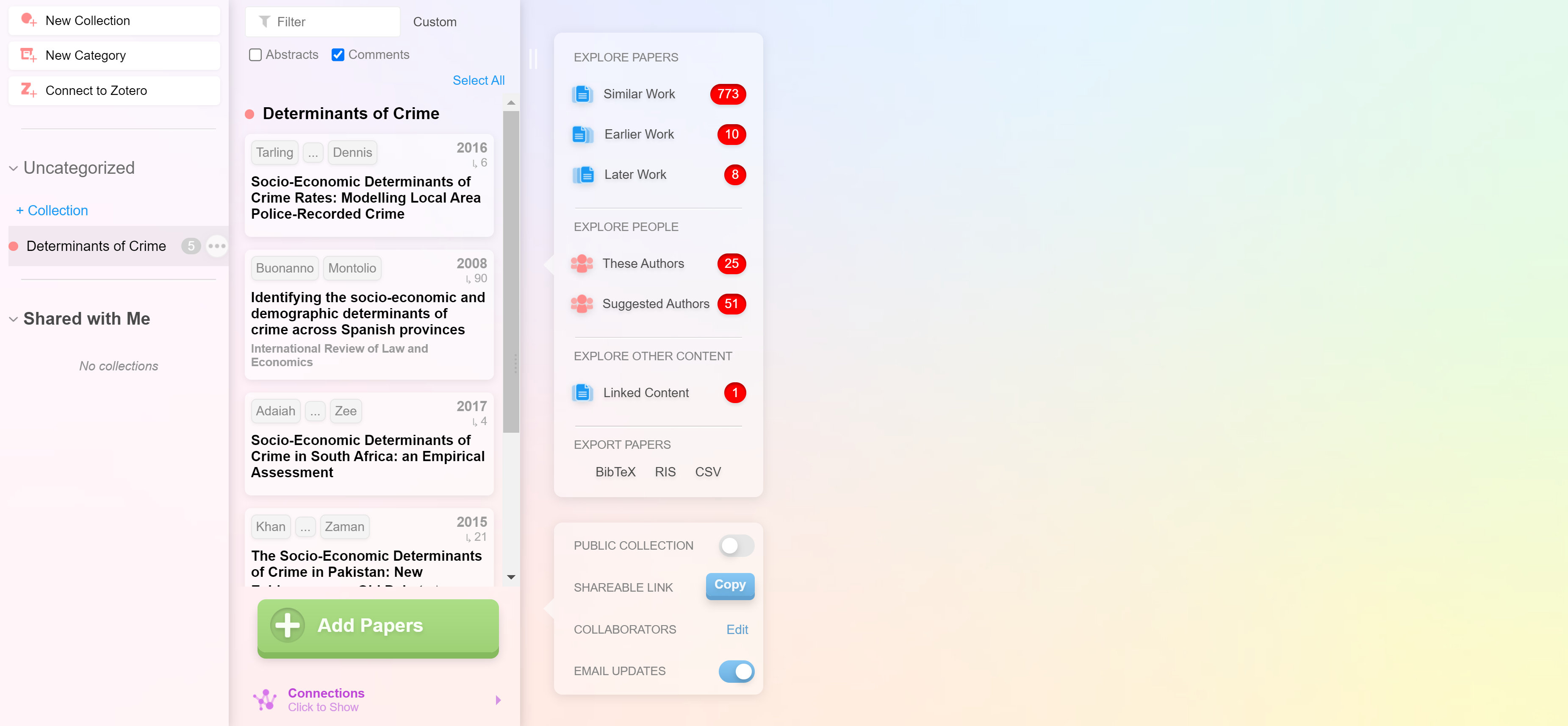
Шаг 4. Строим сеть научных текстов
Как только мы добавим пять или более текстов, нам предложат построить сеть (появится розовая кнопка "Connections" под списком наших источников). Нажмем ее.

Построенная нами сеть представляет жалкое зрелище. Выбранные нами статьи почти никак не связаны друг с другом. Исследование 2015 г. цитирует текст 2008 г. (что отражено в виде связи), но в остальном работы никак не упоминают друг друга и не образуют никакого единого дискуссионного поля. Это неудивительно, ведь мы выбирали эти тексты буквально наугад (потому при подготовке обзора без использования ИИ-приложения так делать было бы нельзя).
Кроме того, можно заметить, что более новые тексты отображаются более насыщенным цветом, чем старые публикации. А размер кружочков отражает количество раз, которые статья процитирована — чем жирнее круг, тем чаще статью цитировали относительно других публикаций в сети.
Не будем останавливаться на этом промежуточном результате и посмотрим немного правее, где приложение любезно предлагает сразу несколько новых опций: найти похожие статьи, более поздние публикации (те, которые цитируют наши) или более ранние публикации (те, которые цитируются нашими). Можно также посмотреть, что еще написали авторы выбранных нами текстов, и рассмотреть рекомендуемых авторов по этой теме (или близким темам).

Пока мы недостаточно точно обозначили наше исследовательское поле, потому нажмем на "Similar Work". Нам тут же предложат большой список текстов, отсортированных по релевантности (или центральному положению в сети). Также приложение построит сеть из первых 50 текстов. Зеленые точки — то, что мы уже добавили (две точки все еще никак не связаны с дискуссией, три другие вписаны в сеть, но находятся далеко не в центре сети).

А в центре нашей сети оказалась классическая работа нобелевского лауреата Гэри Беккера с 10,732 цитированиями. Т.е. даже если бы мы ничего не знали про выбранную нами тему и никогда не слышали про Беккера, то на этом этапе узнали бы о его существовании и поняли, что он ключевой автор, чьи работы обязательны к прочтению.

Каждую работу в построенной сети можно выбрать, прочитать аннотацию и в случае необходимости добавить к нашей коллекции, нажав кнопку в правом верхнем углу "Add to Collection".
Шаг 5. Добавляем новые источники
Нас не интересуют все без исключения статьи, попавшие в сеть. Нужны те, которые посвящены социальным и экономическим детерминантам преступности. Пройдем по сети (клик на разные точки) и добавим десяток текстов, которые кажутся нам наиболее релевантными. При прочих равных предпочтение лучше отдавать тем, что находятся ближе к центру сети.
При решении этой задачи стало понятно, что из 50 источников в этой сети нам безоговорочно подходит не более десятка, остальные написаны на связанные темы, но мы пока не знаем, нужны ли они (т.е. бездумно переносить все 50 текстов в библиотеку мы не будем).
Вернемся к исходной точке — нашему списку литературы (для этого нужно поскроллить страницу влево).

Теперь сеть связей между нашими источниками выглядит менее позорно — статьи явно (за исключением двух, выбранных изначально) образуют единую сеть научной дискуссии.
Можно повторить процедуру, нажав "Similar Work". Сеть будет построена уже для 14 текстов, что мы отобрали.

Здесь мы уже начинаем видеть чёткие кластеры литературы. Например, в нижней части сети у нас оказались тексты про влияние образования на преступность, в левой части про безработицу, в правой про неравенство, вверху страновые кейсы с опытом различных стран мира. Таким образом, мы не только нашли новые источники, но теперь лучше понимаем, как структурирована дискуссия и какие факторы стоит изучить.
Мы можем добавить статьи из тех кластеров, что нам интересны, а затем перестроить сеть снова (и так сколько угодно раз).
Другой полезный прием — это попросить найти "последующие работы". Действительно, наш список литературы пока получается немного устаревшим, работ опубликованных в последние несколько лет практически нет. Нажимая "Later Work" мы немного жертвуем похожестью, потому лучше использовать эту кнопку не на первом этапе, а после того, как сделаны несколько итераций поиска и добавления похожих работ.

Кроме того, над сетью есть полезное переключение на "Timeline". В этом случае мы не увидим красивую сеть, но получим сортировку работ от самых новых к самым старым.

Можно добавить в сеть несколько более новых источников. При прочих равных у них было меньше шансов попасть в сеть, поскольку они опубликованы недавно и еще не успели получить внимания. Вообще это весьма важное ограничение данного инструмента — совсем новых текстов там нет, а ранние исследования имеют более высокие шансы оказаться в центре сети, чем недавние.
Шаг 6. Останавливаемся и читаем
Итак, у нас уже есть список литературы из пятидесяти источников, которые точно охватывают наиболее обсуждаемые в литературе аспекты нашей проблемы. Возможный вопрос — когда следует остановиться. Ответ на него зависит от задач исследования.
Если задача состоит в том, чтобы познакомиться с темой в общем виде, то после добавления нескольких десятков источников можно садиться за чтение. Возможно, что следующие 30-40 текстов не добавят много нового и лучше будет поискать работы на смежные темы. Если задача состоит в систематическом анализе проблемы или теории и важно охватить все, что есть, то остановиться можно в том момент, когда перестройка сети перестанет предлагать тексты по вашей тематике. Например, для ответа на вопрос о социально-экономических детерминантах преступности нам не нужно глубоко погружаться в историю криминалистики или в тематику человеческого капитала, хотя эти теми и связаны. Но сеть по выбранной нами теме, если строить ее полностью, будет огромной, поскольку про влияние на преступность неравенства или образования написано много десятков статей. Потому другой подход — когда станут понятны темы, на которые разбивается дискуссия, можно взять по несколько ключевых источников из каждого кластера.
Шаг 7. Пригласить соавторов (если есть)
Приложение позволяет работать над списком литературы совместно. Можно пригласить ваших соавторов.

Кстати источники можно и убирать из коллекции. Например, у нас остались две изначально добавленные из Google Sholar статьи, которые оказались никак не связаны с общей дискуссией.

Можно также вручную добавить к сети новые статьи, если вы считаете, что их не хватает.
Интеграция с Zotero
Zotero позволяет хранить найденную литературу и удобно ее организовать по проектам или темам. Как было сказано в самом начале, Research Rabbit имеет связываться с Zotero, чтобы брать оттуда источники и добавлять новые тексты.
Если настроить связь с Zotero, то вы сможете напрямую добавлять свои папки в Research Rabbit. Синхронизируется не вся ваша библиотека, а только та коллекция (папка), что вы выбрали.
При синхронизации Research Rabbit может не найти некоторые тексты, тогда приложение предложит добавить наиболее похожий на них вариант (так бывает, например, если в вашей библиотеке был текст online first, который успел выйти со страницами и другим годом).
Таким образом, начинать со случайных статей, найденных в Google Sholar совсем не обязательно (и даже ненужно, здесь это было сделано лишь для иллюстрации того, что сеть можно построить даже на основе случайно выбранных текстов).

Преимущество синхронизации с Zotero состоит в том, что когда вы добавляете текст в свою сеть, он автоматически добавляется и в вашу коллекцию Zotero (обновление может занять несколько минут, но это происходит). После этого вы можете работать с выбранными текстами, добавлять их в свое исследование и формировать список литературы.
Если хотите оставаться в курсе новых возможностей по корректному и эффективному использованию ИИ в исследовательской работе, подписывайтесь на канал.