Inductive bias и нейронные сети
Tatiana GaintsevaВ этой статье я расскажу, что такое inductive bias и где он встречается в машинном обучении. Спойлер: везде. Любая нейросеть имеет inductive bias (даже та, что в человеческом мозге, хе-хе)
Также вы узнаете:
- почему inductive bias — это очень хорошо
- какой inductive bias в сверточных нейросетях
- и как успех архитектуры Image Transformer связан с inductive bias
Ну что, поехали:

Что такое inductive bias
Inductive bias — это набор ограничений, которые возникают у модели машинного обучения вследствие сделанных допущений об устройстве модели и способа ее обучения.
(eng: Inductive bias refers to the restrictions that are imposed by the assumptions made in the learning method — link)
Я намеренно не буду переводить термин "inductive bias" на русский язык: общепринятого перевода нет, а все разумные варианты перевода, на мой взгляд, не передают суть термина. К тому же, в профессиональной среде все используют англицизм.
Чтобы лучше понять определение, рассмотрим примеры:
- Модель линейной регрессии. Линейная регрессия строится в предположении, что между целевой переменной и зависимыми переменными (признаками) существует линейная зависимость. Иными словами, линейная регрессия строит модель в виде линейного пространства: прямой, плоскости и подобного. Из-за этого ограничения линейности модели линейная регрессия плохо обучается под любые данные, в которых целевая переменная от признаков зависит не линейно (см. рис ниже). Это ограничение — линейная природа модели — и есть ее inductive bias (точнее, один из ее inductive bias'ов)
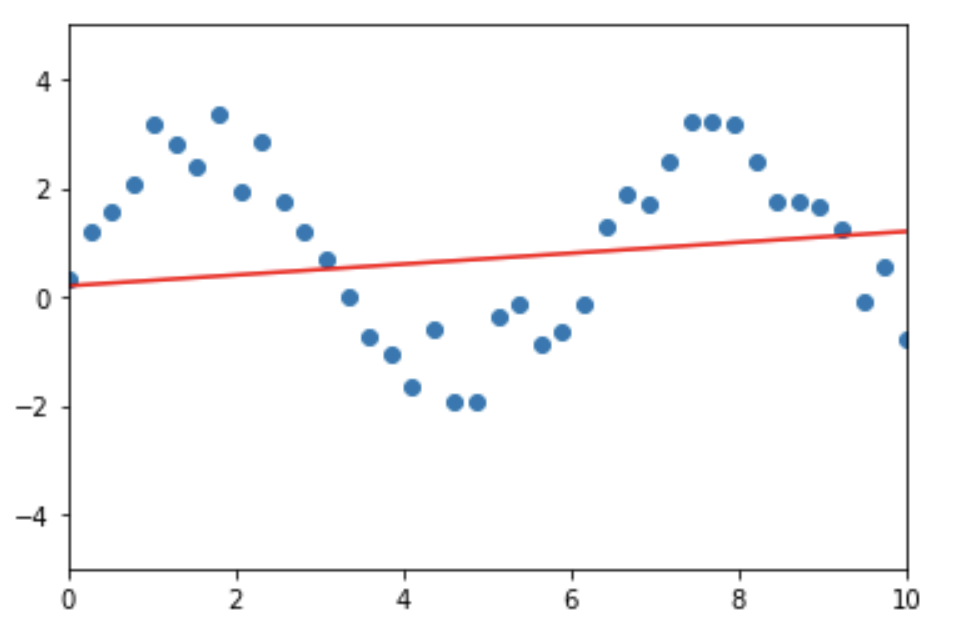
Ось Х — значение признака, ось Y — значение целевой переменной. Видно, что зависимость Y от Х нелинейна. Из-за этого модель линейной регрессии, которая пытается построить линейную зависимость между X и Y, будет очень плохо описывать эти данные.
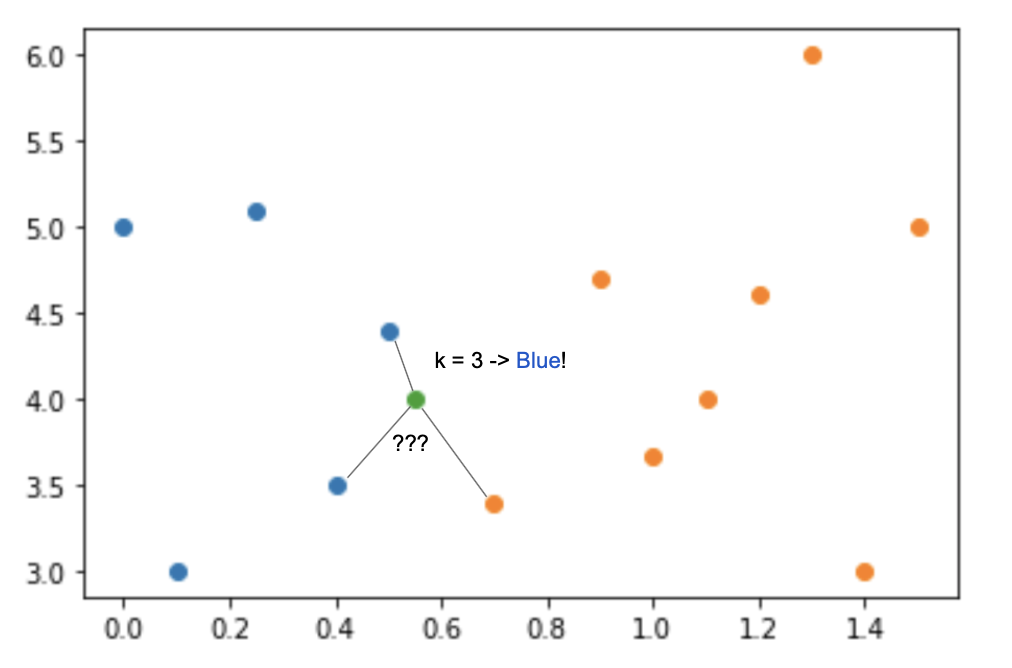
- Модель K ближайших соседей (k-nearest neighbours). Эта модель работает в предположении "компактности": что "значение целевой переменной для неизвестного объекта однозначно определяется значениями целевой переменной для k ближайших (в некотором смысле) к нему объектов". Это допущение — inductive bias алгоритма k ближайших соседей. Понятно, что в реальном мире значение целевой переменной для элемента не обязательно похоже на значения целевой переменной ближайших к нему элементов. И на данных, для которых это допущение неверно, алгоритм KNN работает плохо.
- Ну и приведем пример не из машинного обучения. Вот вы — человек (я почти в этом уверена). Допустим, вы хотите научиться делать так же, как Джерри на гифке ниже: съедать огромный кусок сыра за один раз)

Могу поспорить, что у вас ничего не выйдет: ваше тело устроено так, что не позволит вам так сильно открыть рот и проглотить за раз такой огромный кусок сыра =) Это — inductive bias вашего тела: одно из его ограничений. Точно так же вы не можете растягивать руки, как Мистер Фантастик из "Фантастической четверки" или укусить свой локоть — это тоже ограничения вашего тела, которые появляются из-за определенного устройства ("модели") вашего тела.
Итак, подведем итог: inductive bias — это ограничения модели машинного обучения, которые возникли вследствие определенного дизайна, устройства этой модели.
Без inductive bias не обойтись
Из примеров о линейной регрессии и KNN может показаться, что inductive bias — плохая штука. Ведь он накладывает ограничения на модели! Inductive bias линейной регрессии не позволяет ей хорошо обучаться под данные, которые не имеют линейной зависимости между целевой переменной и признаками. Inductive bias алгоритма KNN не позволяет ему хорошо работать на данных, в которых целевая переменная объекта не однозначно определяется значениями целевых переменных "близких" элементов. Одни недостатки!
Но без inductive bias модель машинного обучения существовать не может. Вот почему:
Цель модели машинного обучения — используя обучающую выборку данных, вывести общее правило, по которому можно будет выдавать ответ на любой элемент из доменной области (а не только на элементы из обучающей выборки). Пример задачи — имея 100.000 изображений лиц людей, научиться решать задачу распознавания лиц и уметь распознавать лица любого человека в мире. Этот процесс — выведение общего правила для всех элементов домена на основе ограниченного числа наблюдений — называется генерализацией (обобщением) модели машинного обучения.
Такая генерализация невозможна без наличия inductive bias у модели. Почему? Потому что обучающая выборка всегда конечна. А из конечного набора наблюдений, не имея совсем никакой дополнительной информации, вывести общее правило можно бесконечным числом способов.
Причем чем меньше обучающая выборка, тем больше у модели различных вариантов вывода общего правила (генерализации), и тем больше из этих вариантов — трешовые. Вы, наверное, знаете, что если обучающая выборка мала, нейронные сети часто переобучаются. Это происходит потому, что у нейросетей не очень сильный inductive bias, и, обучаясь на маленькой выборке, они часто выбирают не тот способ генерализации. Например, при решении задачи классификации изображений кошек и собак обращают внимание на фон, а не на самих животных.
Таким образом, inductive bias — это дополнительная информация для модели; способ показать модели, "в какую сторону думать". Это внедрение в модель неких априорных знаний о том, как устроены данные, с которыми она работает, чтобы она смогла сделать верный выбор алгоритма генерализации. Например, inductive bias линейной регрессии заставляет модель из всех вариантов функций, описывающих данные, выбирать ту, которая имеет линейную природу.
Кстати, если вы спросите, почему люди, в отличие от нейросетей, могут быстро обучиться на задачу классификации кошек и собак, имея всего десяток картинок в обучающей выборке — это потому, что у людей есть inductive bias: мы знаем, что на картинке есть фон, а есть объект, и при классификации картинок нужно обращать внимание только на сам объект. А нейросеть до обучения ни о каких "фонах" и "объектах" не знает — ей просто дают разные картинки и просят научиться их отличать.
Чем меньше обучающая выборка, тем более сильный inductive bias требуется для успешного обучения модели. Иными словами, тем большие ограничения нужно наложить на модель, чтобы она не "ушла сильно в сторону". Inductive bias содержит в себе общую информацию о данных, которые модель сама не может вывести из данных при обучении, так как данных для этого недостаточно.
Выше мы упомянули, что в нейросетях inductive bias не очень сильный. Давайте разберемся, где в нейросетях вообще присутствует inductive bias и почему слишком слабый inductive bias — не всегда хорошо.
Inductive bias в нейросетях
Нейронные сети обладают меньшим inductive bias, чем классические алгоритмы машинного обучения. Но все же он в нейросетях есть.
Каждая нейронная сеть обладает архитектурой (строением). Архитектура нейросети — это то, какие слои в ней присутствуют (полносвязные, сверточные, рекуррентные, ...), сколько нейронов в каждом слое, какая функция активации на каждом из слоев, используется ли dropout и attention и т.д. Архитектура нейросети — это уже inductive bias.
Более того, алгоритм обучения нейросети — это тоже inductive bias. Мы обучаем нейросеть с помощью алгоритма обратного распространения ошибки (backpropagation), а не с помощью какого-либо другого метода, и это тоже является некоторого рода ограничением модели. Выбор learning rate, алгоритма оптимизации (Adam, RMSProp, ...) — все это тоже вносит вклад в inductive bias.
Идем дальше. Каждый из типов слоев — сверточный, полносвязный, рекуррентный — имеют свой inductive bias. Причем их inductive bias помогают им обрабатывать данные того вида, для которых они предназначены: сверточному слою — изображения, рекуррентному — данные, представленные в виде последовательностей. Давайте для примера рассмотрим сверточную нейросеть:
Inductive bias сверточного слоя
Рассмотрим сверточный слой (convolution).

https://brandinho.github.io/mario-ppo/
Inductive bias сверточного слоя — предположение компактности и нечувствительности к переносу (translation invariance). Фильтр свертки за один раз захватывает компактную часть всего изображения (например, квадрат 3х3 пикселя, как показано на гифке), не обращая внимания на дальние пиксели изображения. Также в сверточном слое один и тот же фильтр используется для обработки всего изображения (как на гифке — один и тот же фильтр обрабатывает все квадраты 3х3 изображения).
Эти inductive bias помогают сверточному слою обрабатывать изображения так, как их "обрабатывает" человек: предположение компактности отвечает человеческому представлению о том, что каждый объект на изображении расположен компактно, т.е. в определенной области изображения, а не разреженно по всей площади картинки; а нечувствительность к переносу отвечает тому, что один и тот же объект на изображении будет обработан одинаково вне зависимости от того, в какой части картинки он находится (см. рис. ниже):

Таким образом, inductive bias сверточного слоя помогает ему эффективно обрабатывать изображения. Сверточный слой устроен так, что его inductive bias отлично соотносится с природой изображений и объектов на них, поэтому сверточные нейросети так хороши в обработке картинок.
Visual Transformer и inductive bias
Возможно, вы слышали об архитектуре Visual Transformer. Это НЕсверточная архитектура нейросетей для обработки изображений, которая показывает лучшие результаты, чем сверточные сети, на некоторых задачах: например, на задаче классификации картинок из датасета JFT-300M. В этом датасете 300 миллионов изображений. Подробно об архитектуре читайте в оригинальной статье.
Может показаться, что раз Visual Transformer побеждает сверточные нейросети на крупных датасетах, то все: эпоха сверток прошла, теперь Visual Transformer — лучшая архитектура.
На самом деле — и да, и нет. Visual Transformer действительно бьет сверточные нейросети на крупных датасетах, однако на небольших датасетах Transformer проигрывает сверткам. Другими словами, если у вас есть огромный датасет для обучения сети, Transformer — ваш выбор, однако для обучения на небольших датасетах лучше выбрать свертки.
На графике ниже представлены результаты нескольких моделей, обученных на разных датасетах: ImageNet (~1.2 млн изображений), ImageNet-21k (~15 млн изображений) и JFT-300M (~300 млн изображений).
BiT — сверточная архитектура на основе ResNet, ViT — архитектура Visual Transformer. На графике видно, что трансформеры начинают показывать результаты лучше сверток только на больших датасетах.

Результаты моделей BiT (ResNet-based) и ViT (Visual Transformer) на датасетах разных размеров. Внутри серой области заключены результаты различных моделей BiT. Видно, что ViT начинает выигрывать у BiT только при достаточно большом размере датасета
Так происходит, потому что у архитектуры Visual Transformer нет inductive bias, какие есть у сверточного слоя. Здесь мы наблюдаем подтверждение того, что чем меньше обучающий датасет, тем более сильный inductive bias нужен для успешного обучения модели. Но верно и обратное: чем больший датасет есть у нас в распоряжении, тем меньший inductive bias требуется и тем лучше модель может обучиться под задачу (потому что у нее меньше ограничивающих bias'ов)
А также убеждаемся, что inductive bias сверточных нейросетей действительно сильно помогает для решения задач, связанных с изображениями.
Какие inductive bias у других слоев: рекуррентного, полносвязного и т.д., предлагаю подумать самостоятельно =)
Заключение
Как видно из этих примеров, сделать модель без inductive bias в принципе невозможно, так как уже само устройство модели вносит ограничения в ее возможности и является inductive bias. Да и делать такую модель не нужно: как мы увидели из статьи, inductive bias часто помогает в решении задач. Вопрос лишь в том, насколько сильный нужен inductive bias для решения конкретной задачи и насколько он поможет решить нужную задачу.
Главная задача при создании архитектуры модели машинного обучения — наделить модель таким inductive bias, чтобы он помогал модели обучиться решать поставленную задачу (как в случае сверток), а не мешал.
Надеюсь, эта статья помогла вам в понимании того, что такое Inductive bias и почему он полезен, а не вреден =) Вот еще несколько полезных ссылок по теме:
Литература:
Inductive Bias (springer.com)
Using inductive bias as a guide for effective machine learning prototyping (medium)
Supercharge your model performance with inductive bias (towardsdatascience)
JFT-300M dataset (paperswithcode)
An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale (arxiv)