Индексация
Что такое индексация?
Индексация - это механизм доступа к данным, позволяющий ускорить поиск по столбцам путем создания индексов (указателей на место хранения данных в базе данных).
Представьте, что вы хотите найти какую-то информацию в базе данных. Компьютер будет просматривать каждую строку, пока не найдет ее. Если искомые данные находятся в самом конце, такой запрос будет выполняться очень долго.
Наглядное представление поиска последней записи:
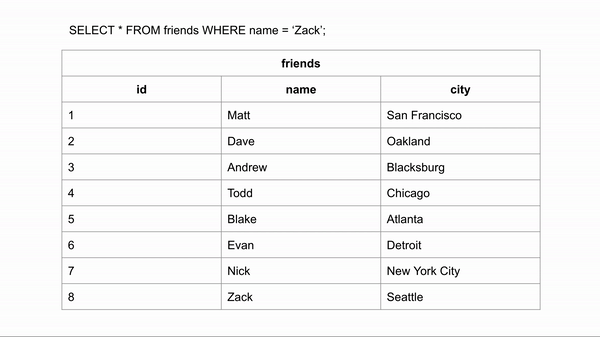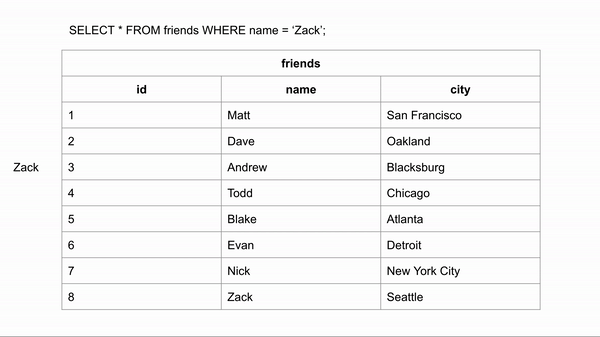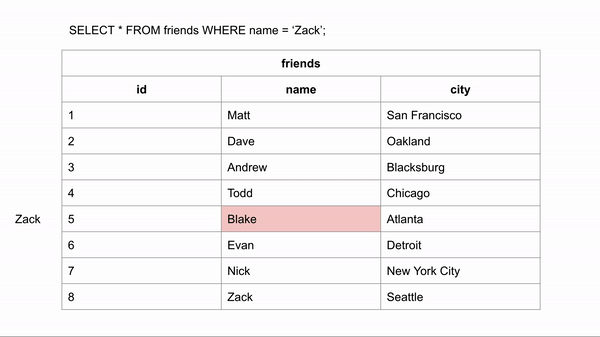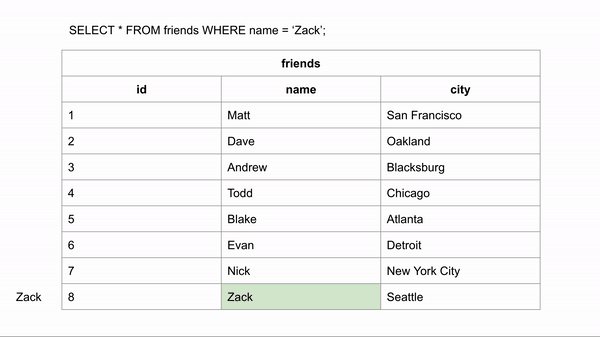
Если бы таблица была упорядочена в алфавитном порядке, поиск имени происходил бы намного быстрее. Если мы хотим найти "Zack" и знаем, что данные расположены в алфавитном порядке, мы можем перейти в середину записей и посмотреть, находится ли Zack до или после этой строки. Затем для для оставшихся строк опять провести такое же сравнение.
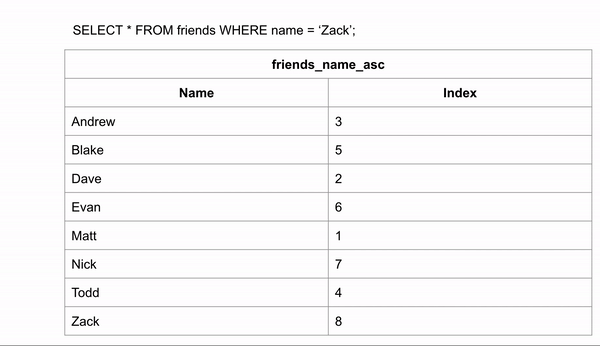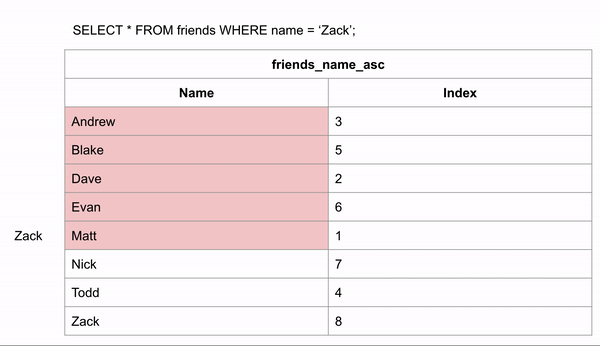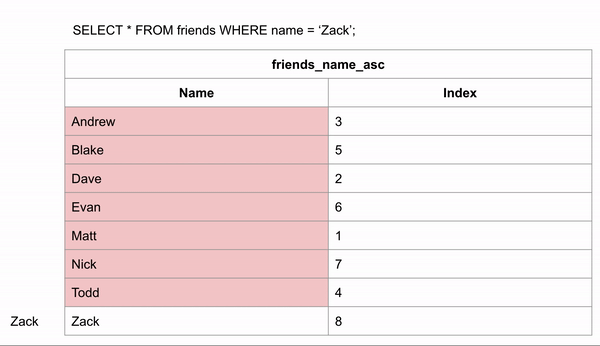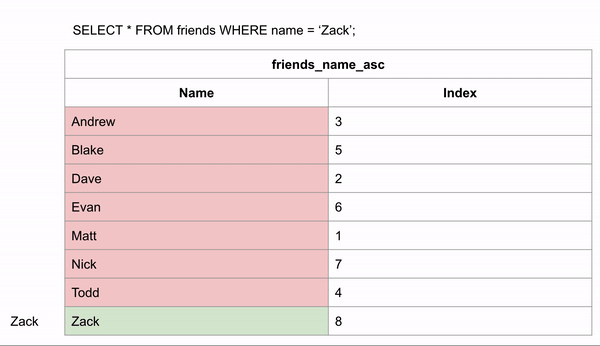
Для поиска правильного ответа потребовалось 3 сравнения вместо 8 в неиндексированных данных.
Индексы позволяют нам создавать отсортированные списки без необходимости создавать новые отсортированные таблицы.
Что такое индекс?
Индекс - это объект, содержащий поле, по которому сортируется индекс, и указатель от каждой записи к соответствующей записи в исходной таблице. Давайте рассмотрим индекс из предыдущего примера и посмотрим, как он сопоставляется с исходной таблицей Friends:
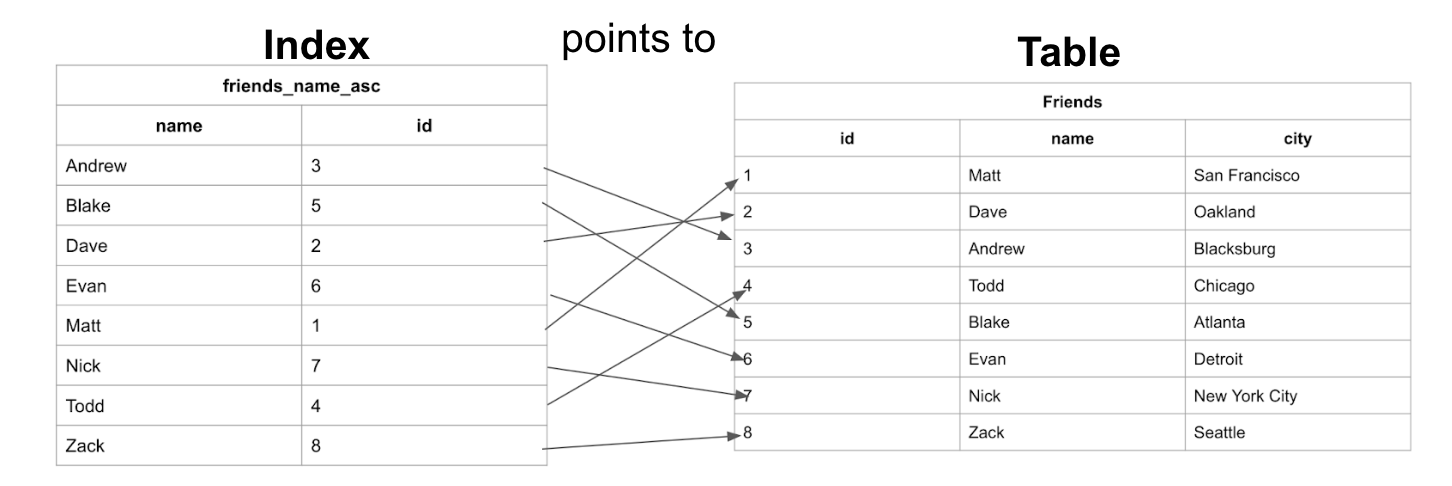
Мы видим, что в таблице данные хранятся в порядке добавления данных. А в индексе имена хранятся в алфавитном порядке.
Типы индексов
Существует два типа индексов:
- Кластерные
- Некластерные
Как кластерные, так и некластерные индексы хранятся в виде B-деревьев - структуры данных, похожей на двоичное дерево. B-дерево - это "самобалансирующаяся древовидная структура данных, которая поддерживает сортировку данных и позволяет выполнять поиск, последовательный доступ, вставку и удаление за логарифмическое время". По сути, она создает древовидную структуру, которая сортирует данные для быстрого поиска.
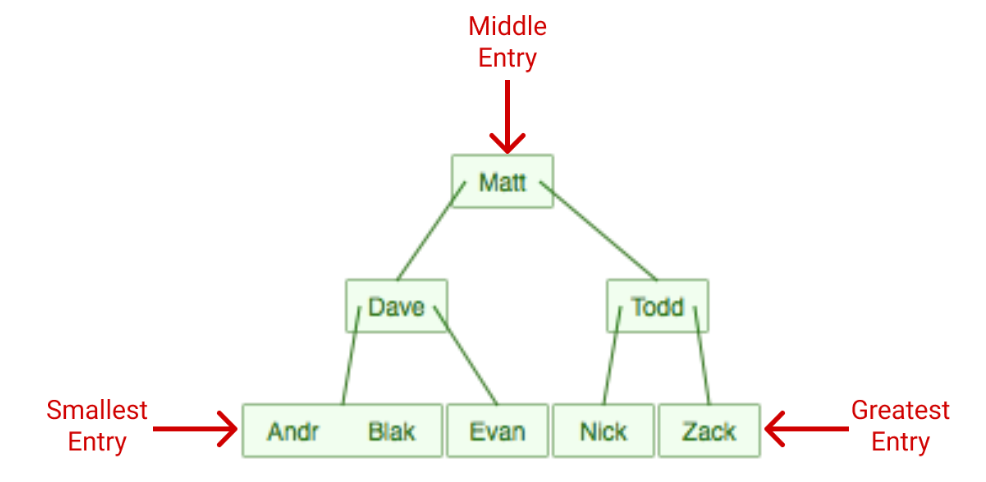
Здесь представлено B-дерево созданного нами индекса. Самая маленькая запись - самая левая, а самая большая - самая правая. Все запросы начинаются с верхнего узла и идут вниз по дереву, если целевая запись меньше, чем текущий узел, то используется левый путь, если больше - правый.
Для повышения эффективности многие B-деревья ограничивают количество символов в записи. B-дерево делает это самостоятельно и не требует ограничения исходных данных. В приведенном выше примере B-дерево ограничивает длину значений до 4 символов.
Кластерные индексы
Кластерный индекс - это уникальный индекс, использующий первичный ключ. Кластерный индекс гарантирует, что первичный ключ хранится в порядке возрастания, что также является порядком, в котором таблица хранится в памяти.
- Кластерные индексы не нужно явно объявлять.
- Создаются при создании таблицы.
- Используют первичный ключ, отсортированный в порядке возрастания.
Кластерный индекс создается автоматически при указании первичного ключа:
CREATE TABLE friends (id INT PRIMARY KEY, name VARCHAR, city VARCHAR);
После заполнения эта таблица будет выглядеть следующим образом:
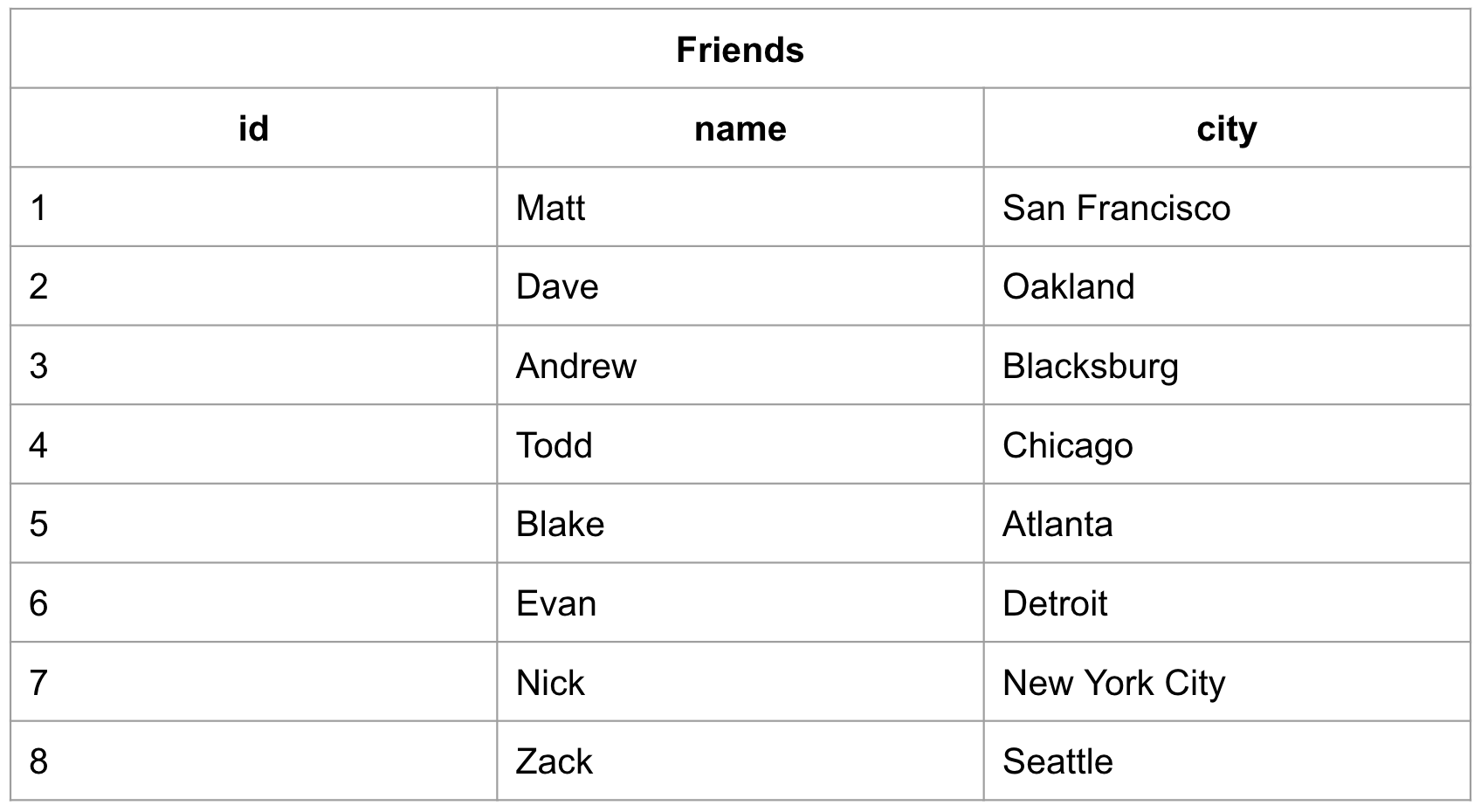
В созданной таблице "friends" автоматически создан кластерный индекс, построенный вокруг первичного ключа "id", под названием "friends_pkey":
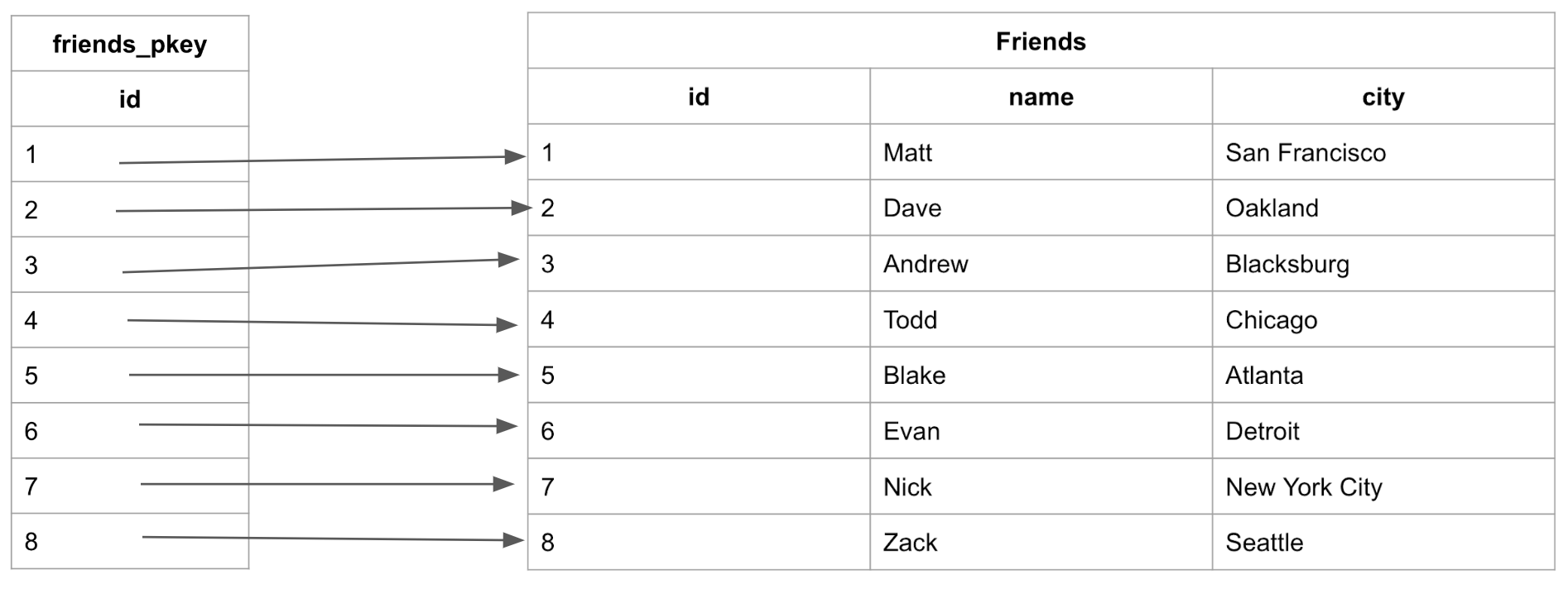
При поиске в таблице по "id" из-за возрастающего порядка столбцов поиск выполняется оптимально.
Однако, чтобы найти в таблице "name" или "city", нам придется просматривать каждую запись, поскольку эти столбцы не имеют индекса. Именно здесь используются некластерные индексы.
Некластерные индексы
Некластерные индексы - это отсортированные ссылки на определенное поле из основной таблицы. Для создания некластерного индекса используйте следующий код:
CREATE INDEX friends_name_asc ON friends(name ASC);
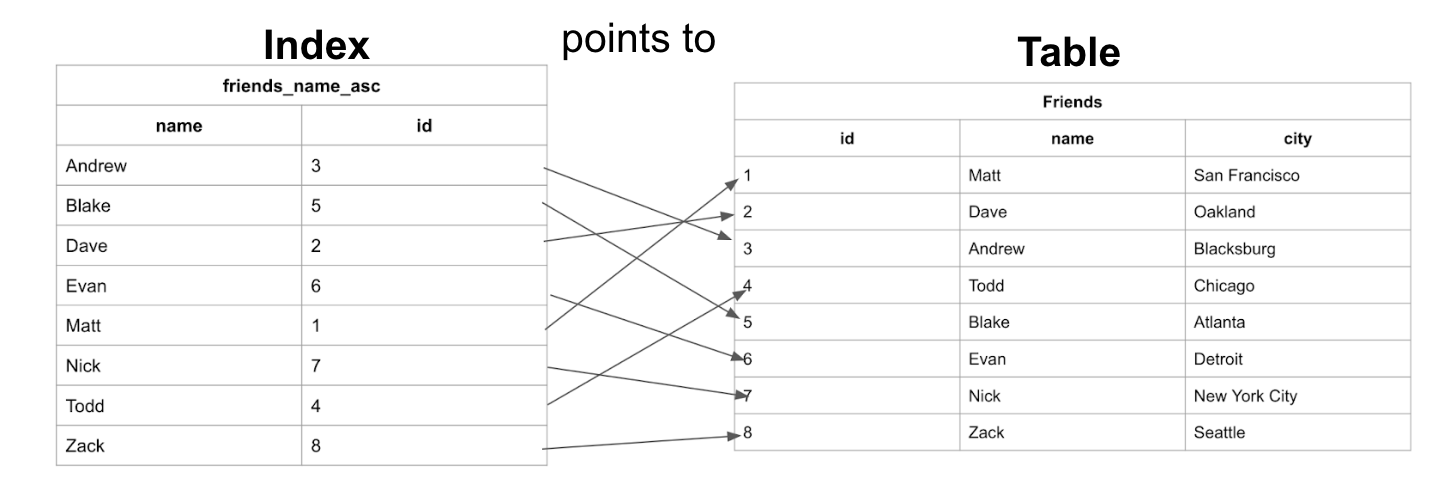
Некластерные индексы могут быть созданы после создания и заполнения таблицы.
Примечание: Некластерные индексы не являются новыми таблицами. Можно из воспринимать как оглавление книги. Номер страницы указывает на то место в книге, где вы можете найти нужные данные.
Некластерные индексы указывают на адреса памяти, а не хранят сами данные. Это делает их более медленными, чем кластерные индексы, но обычно они намного быстрее, чем неиндексированный столбец.
Вы можете создать множество некластерных индексов. Начиная с 2008 года, в SQL Server можно иметь до 999 некластеризованных индексов, а в PostgreSQL ограничений нет.
Просмотр созданных индексов
В PostgreSQL команда "\d" используется для получения подробной информации о таблице, включая имя таблицы, столбцы таблицы и их типы данных, индексы и ограничения.
Детали таблицы friends выглядят следующим образом:
Запрос, предоставляющий подробную информацию о таблице friends: \d friends;

"friends_name_asc" является ассоциированным индексом таблицы "friends". Это означает, что план, который SQL создает при определении наилучшего способа выполнения запроса, начнет использовать этот индекс при выполнении запросов. Обратите внимание, что "friends_pkey" указан как индекс, хотя мы никогда не объявляли его как индекс. Это кластерный индекс, который автоматически создался на основе первичного ключа.
Мы также видим, что существует индекс "friends_city_desc". Этот индекс был создан аналогично индексу имен:
CREATE INDEX friends_city_desc ON friends(city DESC);
Этот новый индекс хранится в обратном алфавитном порядке, поскольку было передано слово "DESC", что означает "по убыванию".
Эффективность индексов
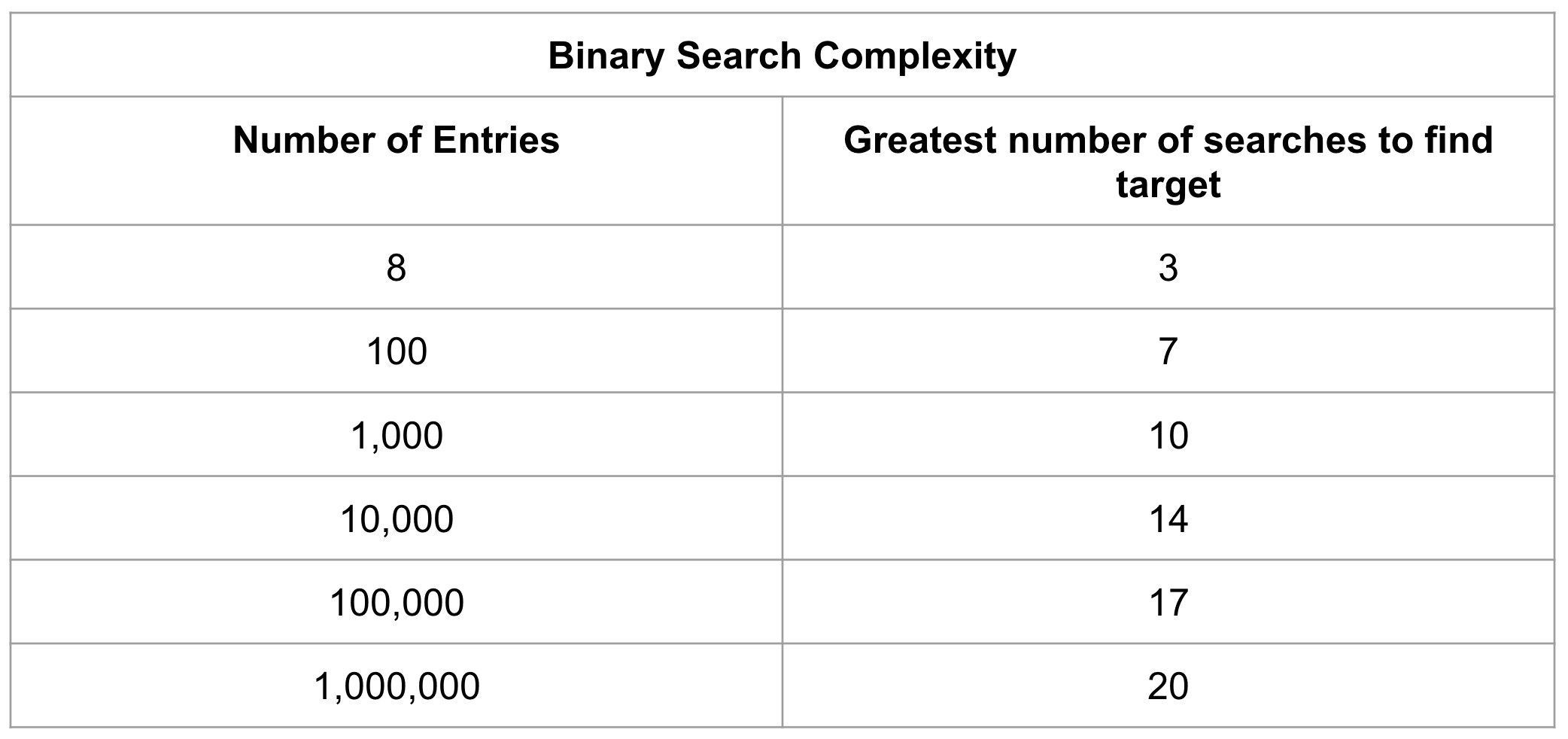
Сравнивая метод поиска по индексированной таблице friends с поиском по неиндексированной таблице friends, можно сократить общее количество поисков с восьми до трех. Используя этот метод, поиск в 1 000 000 записей можно сократить всего до 20 переходов в двоичном поиске.
Когда использовать индексы
Индексы предназначены для ускорения работы базы данных, поэтому используйте индексацию всегда, когда оно значительно повышает производительность вашей базы данных. Чем больше становится ваша база данных, тем больше вероятность того, что вы увидите преимущества индексациии.
Когда не использовать индексы
При записи данных в базу сначала обновляется исходная таблица (кластерный индекс), а затем обновляются все индексы этой таблицы. Каждый раз, когда в базу данных производится запись, индексы становятся непригодными для использования, пока они не будут обновлены. Если база данных постоянно получает записи, индексы никогда не будут пригодны для использования. Именно поэтому индексы обычно применяются в базах данных хранилищ данных, которые обновляются по расписанию (в непиковые часы), а не в продакшн базах данных, которые могут постоянно записывать новые данные.
Тестирование производительности
Чтобы проверить скорость выполнения запросов с и без индексов, используйте оператор EXPLAIN ANALYZE в PostgreSQL:
EXPLAIN ANALYZE SELECT * FROM friends WHERE name = 'Blake';
Имейте в виду, что:
- Планирование запросов в PostgreSQL довольно эффективно, поэтому добавление нового индекса может не повлиять на скорость выполнения запросов.
- Добавление индекса всегда означает хранение большего количества данных
- Добавление индекса увеличит время, необходимое для полного обновления базы данных после операции записи.
Если добавление индекса не уменьшает время выполнения запроса, вы можете просто удалить его из базы данных.
DROP INDEX friends_name_asc;