Improved Customer Lifetime Value Prediction with Sequence-To-Sequence Learning and Feature-based Models
Artem ErokhinСтатья 2021 года. Авторы решили использовать RNN (recurrent neural networks), смешав это дело еще и с градиентными бустингами. Для нас здесь интересно посмотреть на подходы на основе рекуррентных сетей к моделированию LTV.
Я уже упоминал о том, что поставить задачку предсказания LTV можно по-разному. Например, это может быть просто задача регрессии, или какая-то смесь регрессии и классификации (пользователь останется/не останется). Но можно подумать об этой задаче, как о задаче моделирования временных рядов. То есть, у нас есть историческая последовательность действий, по которой мы хотим предсказать последующие действия. В такой постановке использование RNN является достаточно привычным методом решения, которое позволяет качественно учитывать особенности поведения пользователей во времени, периодичность возвращения и т.п. вещи.
Собственно, такую постановку и рассматривают авторы. У нас есть последовательность действий до какого-то момента времени. По ней мы хотим предсказать последовательность поведения после этого момента времени. Просуммировав предсказанные покупки, получим LTV пользователя в будущем.
Начнем с описания предлагаемого процесса предсказания:
- Из данных получаем признаки, основанные на временном ряде, и векторные представления для логов (примерно таким же образом, который мы ранее видели в заметке про Customer2Vec);
- Последовательности значений подаем в RNN модель. Тут стоит отметить, что мы подаем не просто ряд, а сглаженный ряд (в статье предлагают свертки над последовательностью значений, которые просто можно воспринимать, как абстракцию над скользящим средним). Второе замечание - мы подаем не просто последовательность покупок пользователя в виде векторов, а еще и обогащенные признаками данные в виде тензоров (в данном случае можно представить двумерной матрицей);
- Дополнительно мы используем и GBM модель над полученными на шаге 1 признаками;
- Соединяем результаты посредством стекинга -> получаем итоговые результаты предсказания LTV (про стекинг подробнее отсылаю к блогу Александра Дьяконова)

По замыслу авторов, такого рода соединение обеспечивает получение модели, учитывающей изменчивость во времени без ручной генерации признаков (собственно, RNN для этого и предполагается использовать). Но при этом, еще и учитывающей “классическую” постановку задачи регрессии, которая “ловит” иные связи между признаками (например, между статичными признаками пользователя - страна, пол и т.д. и какими-то вручную полученными агрегациями). В целом, подход любопытный, но больно напоминающий соревновательные подходы а-ля kaggle. И тащить такое в прод будет сложновато.
Ок, давайте немного отвлечемся на RNN часть.
Если коротко, то рекуррентные сети сохраняют некую часть информации с прошлых этапов, то есть воспринимают последовательности и стараются в весах сети оставить важную информацию за счет того, что эти веса “делятся” между шагами. Идея такая - получить генерализованное знание на основании полученных сжатых репрезентаций, отражающих важнейшие показатели сущности ряда.
Например, глазами мы можем понимать, что ряд может быть с трендом или без, с сезонностью или без оной и т.д. При этом, для разных рядов может быть важнее нечто свое. Плюс, и сезонность может быть разной, и тренды могут вести себя специфически. Потому, вручную разработанными признаками может быть сложно покрыть все множество возникающих ситуаций (впрочем, это обычная история для машинного обучения). Вот тут нам и нужен автоматический экстрактор признаков (чем и является RNN для временных рядов).
Т.к. детальное описание работы RNN тянет на отдельный пост (а может и не один), оставлю пару ссылок на дополнительные материалы про рекуррентные сети (раз, два).
Что же получилось в итоге?
Авторы сравнивали свой подход с простым средним за период до, BG/NBD, Markov Chain, Embeddings-RandomForest моделями. При этом, сравнивались еще и отдельные части подхода (отдельно GBM, отдельно RNN, отдельно их стекинг). Результаты ниже. Использовались два набора данных - в одном предсказания были на 6 месяцев вперед, в другом на 4 недели (и его я считаю достаточно бессмысленным со стороны бизнеса, т.к. чаще бизнес хочет предсказание LTV хотя бы на несколько месяцев вперед, а лучше - на год и больше).
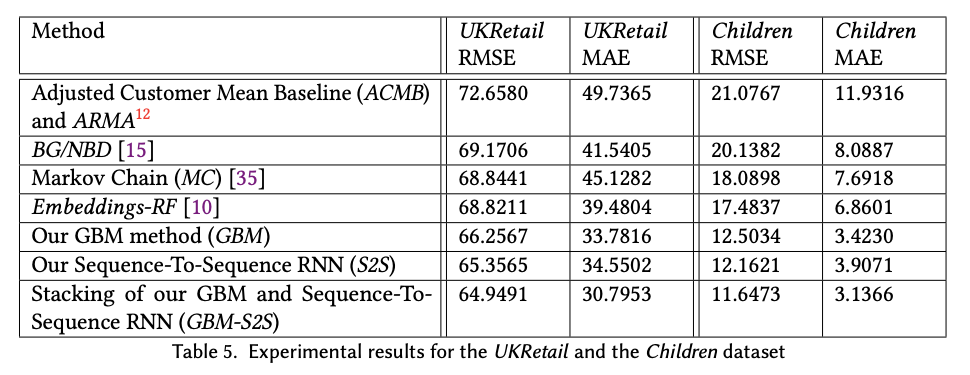
Мое мнение следующее.
Если честно, то отдельные части выглядят вполне себе неплохо. Стекинг, конечно, выиграл. Но сложность его использования может не окупать прироста в точности, т.к. неверно работающий точный алгоритм будет явно хуже чуть менее точного, но работающего без сбоев (а описание итогового подхода выглядит так, что при попытке его напрямую перенести в прод, в команде не найдется столько ног, чтобы собрать все выстрелы в ногу от такого решения).
В конце добавлю найденный код с применением рекуррентных сетей к предсказанию LTV. Правда, он для другой статьи ;) Но суть отражает неплохо.