Identifying Core Data's ability to perform lightweight migrations before loading the container
mad.devThis article has been translated from its original publication at https://habr.com/ru/companies/vk/articles/723672/

As we design an application based on the Core Data framework, we make repeated changes to the data model. Nonetheless, do we have to delete and reload all the data every time while overloading the server and draining users' batteries? Initially, it seemed like the only solution, but we found that everything could be simplified seamlessly.
In the article, we explain how to minimize the negative consequences of changes to data structures and wonder why Core Data still has yet to offer such a solution.
Why Core Data?
There are many frameworks for persistent data storage suitable for both iOS and MacOS app development. Howevwer, engineers choose Core Data, a framework developed by Apple, to address software development challenges for the following reasons:
- Core Data has little impact on compiled application’s size (only the model is stored in the IPA).
- This framework is supported by Apple and is likely to outlast third-party libraries.
Typically, the usage scenario is simple: we get data from the server, display it in the user interface, and store it in the local database so we can:
● Reuse it between screens;
● Show a cache when the network connection is lost (e.g., chat message cache or purchase history).
When rapidly implementing new features, the data model (.xcdatamodel) can quickly become outdated since new attributes are added, unnecessary entities are deleted, etc. Forcing developers to write migrations for every change, creating new model versions, and storing them in the application bundle seemed like a bad idea, as merge conflicts, system errors, increased IPA size, and bad moods were inevitable.
Even though Core Data is capable of lightweight migrations on its own, incompatible data differences can sometimes prevent it. We found an option where we simply delete data if the new model is incompatible with it, thereby emptying the cache. However, a major drawback we noticed during weekly release cycles was that almost every week, the chat or purchase models changed slightly. As a result, the database was deleted and all messages and purchases were downloaded again, straining the server, network, and users.
To achieve a compromise, we deleted the database not upon every model change but when Core Data couldn't do a lightweight migration. Fortunately, Core Data lightweight migrations occur much less frequently, so this solution would prevent redownloads of existing data.
What methods have we used?
- NSManagedObjectModel.isConfiguration(withName:compatibleWithStoreMetadata:) - allows you to check if the model has changed. This method compares the hashes of entities between the model and the database, returning false even if automatic lightweight migration is possible.
- NSMappingModel.inferredMappingModel(forSourceModel:destinationModel:) - allows you to check if a lightweight migration from the old model to the new one is possible. We can create an NSPersistentContainer with the new model, but where can we find the old one? This question we will answer further on.
Looking for old models
The symbolic breakpoint on inferredMappingModel gave us insight into Core Data's ability to restore the data model from which our NSPersistentStore was opened previously. The method is called every time we make any changes to the data model between application runs.
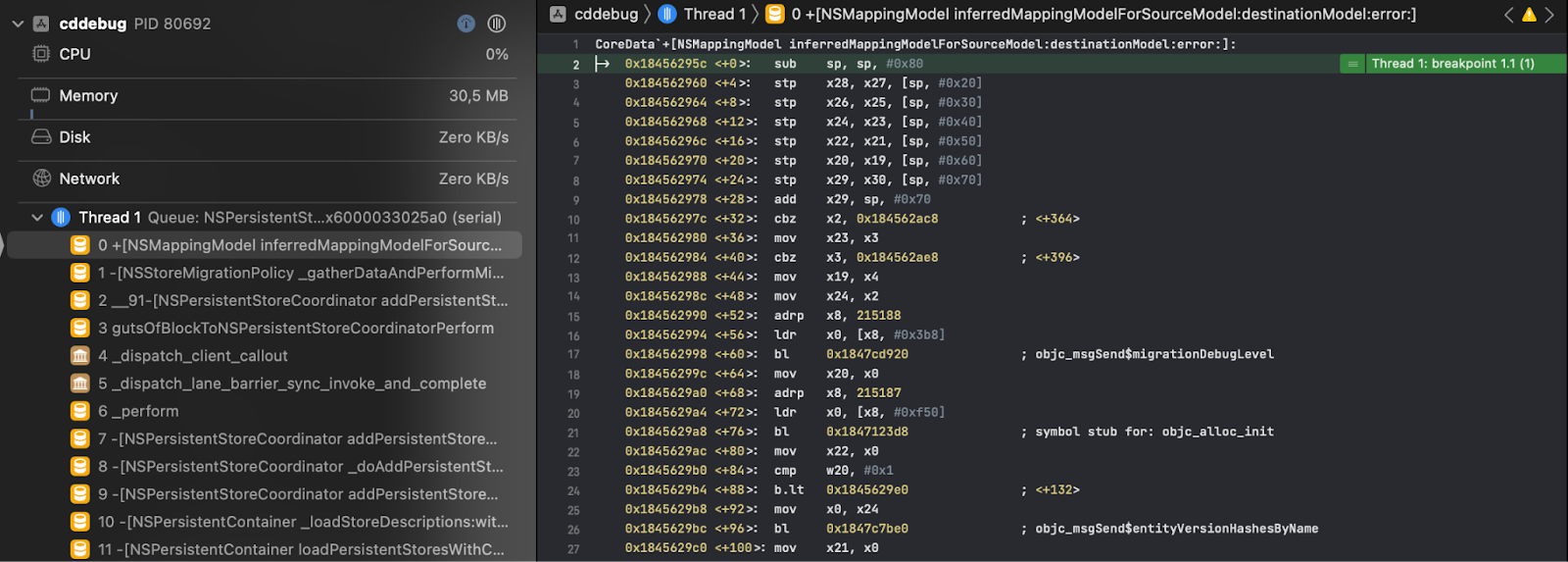
Where can we find the old model? There were two assumptions:
- The model is in the application's Container in the device's memory.
- The model is stored directly in the SQLite database file.
We checked both. It's great that Xcode lets us completely pull the app's Container from Windows → Devices → select device → Installed Apps → my app name → Download Container. We explored all the folders and files of a "blank" application, including only Core Data stack, and found nothing suspicious.
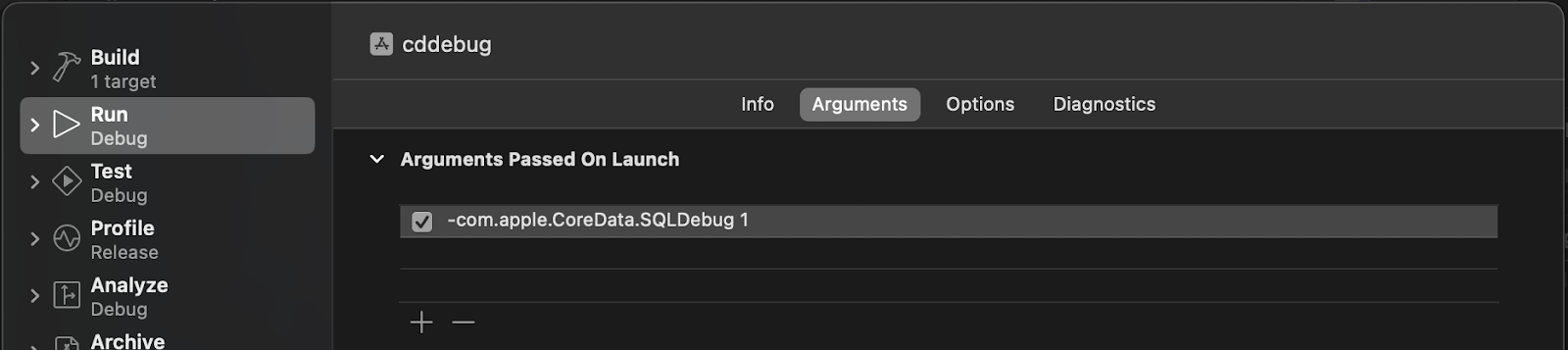
To understand what Core Data does with the SQLite file during initialization, we enable the tracing of all SQL queries. To do this, we edit the application launch scheme and pass the launch argument -com.apple.CoreData.SQLDebug 1.
Before the lightweight migration check stops at the Symbolic Breakpoint, we see the following logs:
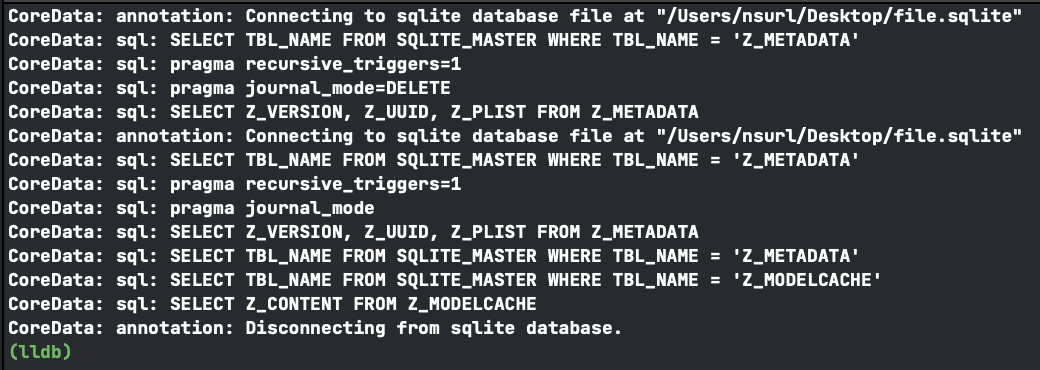
It is evident that when calling loadStore, Core Data communicates with three tables: SQLITE_MASTER, Z_METADATA, and Z_MODELCACHE, with SQLITE_MASTER being a system table of the SQLite DBMS. Apparently, Core Data uses it only to check
● whether Z_METADATA and Z_MODELCACHE exist in the database;
● whether it is the first time the database is being opened.
It was necessary to check what did Z_METADATA and Z_MODELCACHE contain. We used the free, open-source tool DB Browser for SQLite to do so.
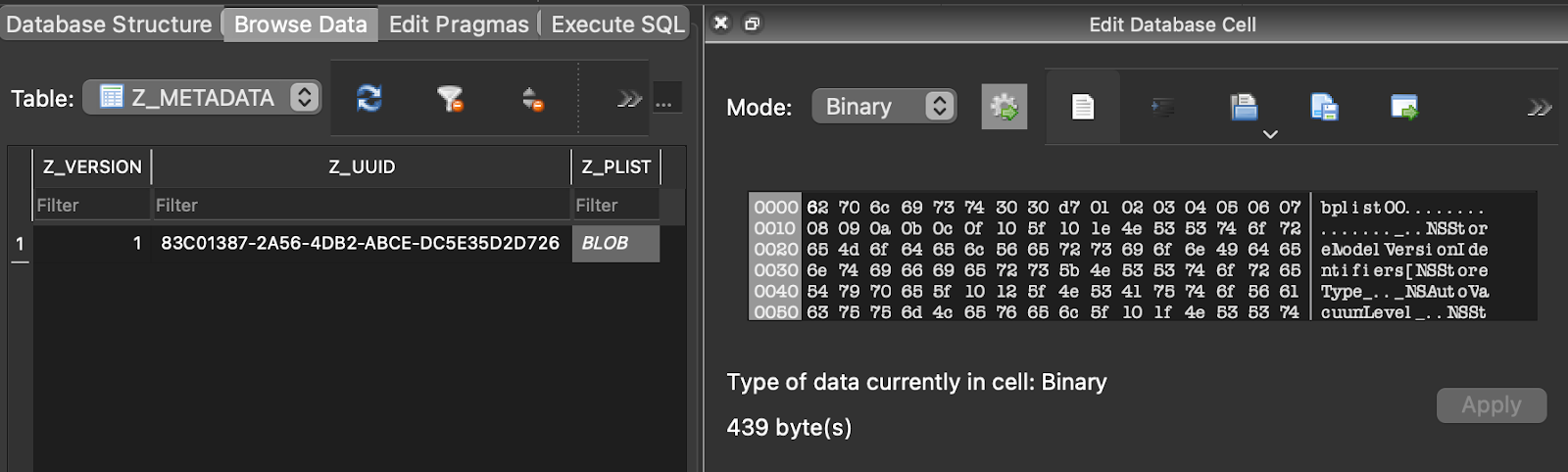
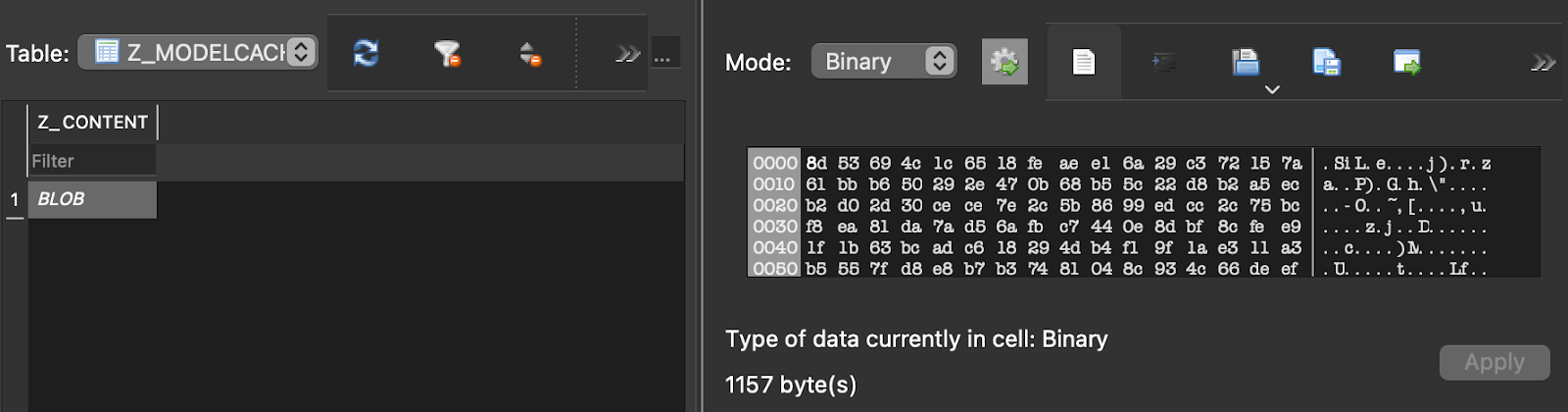
Model repositories are similar to Z_MODELCACHE, although the format in which they are stored is unknown. There were also thoughts that Z_METADATA in Z_PLIST stores enough information about each entity to recreate the entire model. So we looked at what kind of plist it was:

This information seemed similar to what is needed for the NSManagedObjectModel.isConfiguration(withName:compatibleWithStoreMetadata:) method to work. The order of SQL queries in the logs has also confirmed this. The framework checks if the hash of an individual entity has changed, and if so, it goes to Z_MODELCACHE to check for lightweight migration.
The solution was already there, it was just a matter of understanding the format in which the model is stored in Z_MODELCACHE.Z_CONTENT. In order to recover the model from raw data, we tried multiple methods, including NSKeyedUnarchiver, various utilities that suggest file extensions based on their contents, different byte markers like file type (many formats write meta-information into the first bytes), etc. Unfortunately, all of this failed.
Parsing files into small details
Without Hopper, it's impossible to figure it out, and I need to spy on what Core Data is doing with this data to bring the old model back. For such minor investigations, a demo version is usually enough:

Using the simulator, you can view the contents of Core Data functions. Usually, they are located somewhere here:
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Library/Developer/CoreSimulator/Profiles/Runtimes/iOS.simruntime/Contents/Resources/RuntimeRoot/System/Library/PrivateFrameworks/
However, we did not find Core Data there, but in debug session mode, you can use the command "lldb image list" to see all loaded dynamic libraries and find the path eventually:

We drag the binary file into Hopper and start analyzing it. From the stack trace of the Symbolic Breakpoint NSMappingModel.inferredMappingModel(forSourceModel:destinationModel:), we can see that it's being called from the method -[NSStoreMigrationPolicy _gatherDataAndPerformMigration:]. We turn on the pseudocode mode for better readability and look inside the method:
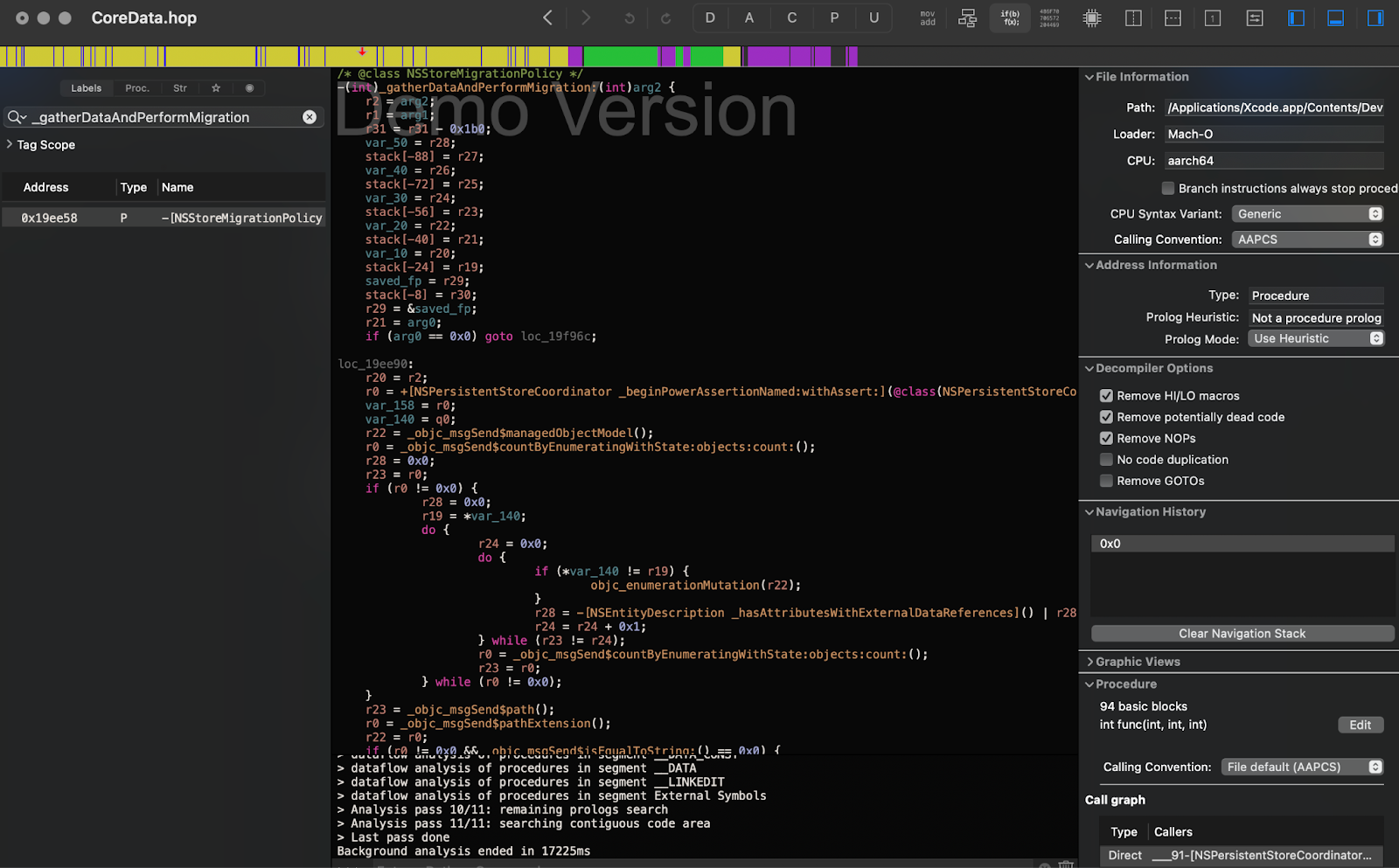
We can see that several messages are sent to obtain the sourceModel and managedObjectModel almost immediately.
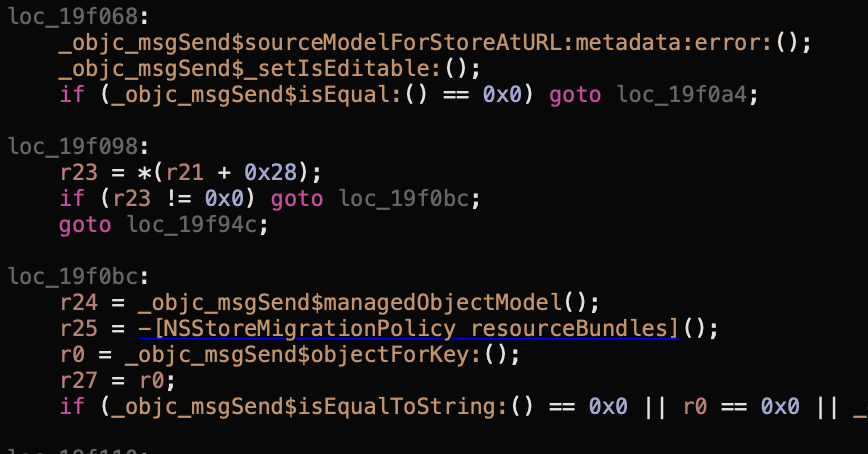
After exploring the functions, we found the one that speaks for itself: -[NSSQLiteConnection fetchCachedModel]. A second Symbolic Breakpoint is shown on the screenshot to demonstrate how deep it is hidden.
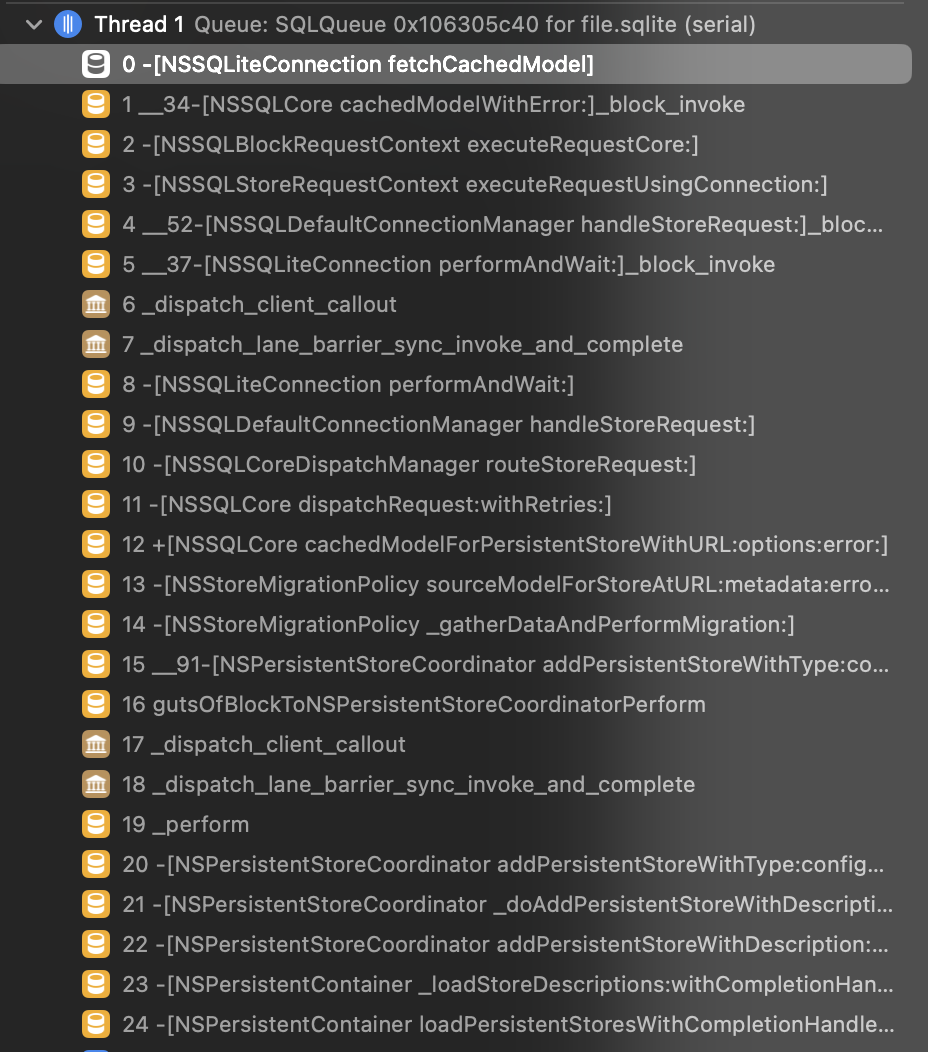
And a screenshot from Hopper:
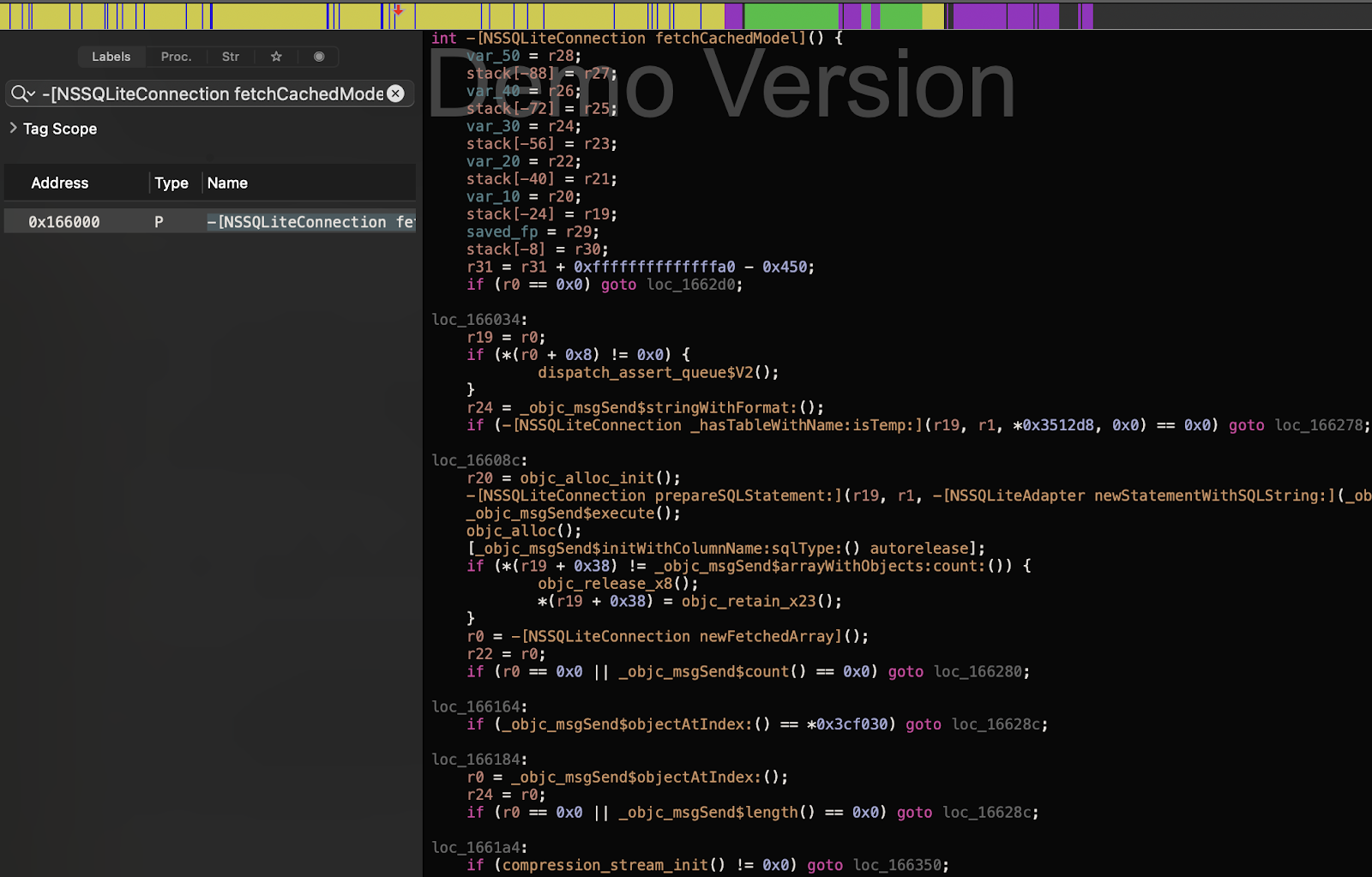
Voila!
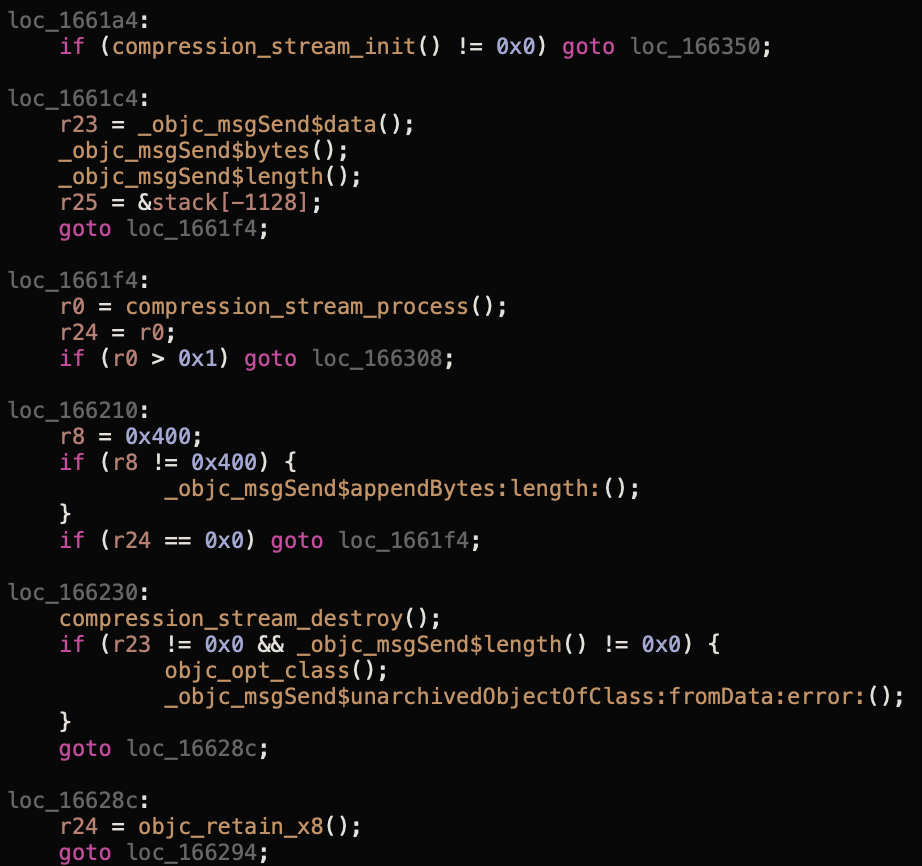
The compression_stream processes the data from the database, and then the unarchivedObjectOfClass function is called. It can be confusing to understand the parameters used to call the function, but the documentation says that four compression algorithms are supported: COMPRESSION_LZ4, COMPRESSION_ZLIB, COMPRESSION_LZMA, and COMPRESSION_LZFSE. Moreover, NSData has a convenient decompressed wrapper that prevents you from manually working with the stream. Finally, we brute-forced the ZLIB algorithm, and our code successfully restored the model.
And a ready-made solution as a conclusion
Ultimately, a clear algorithm and interface were defined for the solution. How did it help us? Thus, we added a few logs and now better understand each database in the application:
- How often does the model change?
- How often does the model change so the cache is no longer valid, and which fields cause this?
- What are the most frequently changing entities?
As a result, we can think about separating the cache so that we don't delete everything when a model slightly changes but only what changes very frequently and significantly. Thanks to this, invalidation affects less data.
It is unclear why the functionality to get the current model from the file was not made public.
You can use the solution launched on GitHub. Tests are conducted to determine if Apple has modified the principle of storing the latest model in the cloud (nonetheless, everything remained unchanged from iOS 11 to iOS 16).