Idea
JapaneseMLはじめまして、1ヶ月半ほど前からNumeraiにハマり始めた新参者です。本業は金融でプログラミング経験は少ないためjupyterで四苦八苦しながら取り組んでいます。実装に時間がかかるのでまだアイディアだけで検証しきれていないものが大半ですが、もし少しでもどなたかのインスピレーションになればと思い書いてみました。
基本的な方向性としては、完璧なモデルは存在しないと思っているので、パラメーター調整等にはあまり時間を費やしていません。NNも時間かかるので深堀りできていません。Kenoさんのものを少しいじってみた程度です。パラメーターをこねくり回して唯一無二の完璧な予想を出すよりも、平均値がそれなりに高くて(個々の予想値ではなく)実際のリターンの相関が低いモデルを複数作り出して分散効果を狙えばそこまでリスクを負うことなく十分儲かるのでは?と考えています。週次2%でも安定していればめちゃくちゃ高いリターンですので。
1-120でトレーニングするとベースラインモデルでざっくりval mean corrが2.5%、stdが2.9%なのでそのあたりを念頭に置いて相関の低いモデルができればそれで良いのかなと。
下のグラフが公式example nodelのliveパフォーマンスです。リーダーボード上位を見てもこれと一緒に上下動しているモデルが非常に多いので、リターンを多様化させる難しさがわかると思います。直近で言うと229をピークに234に向けて落ちるような動きになっている人が非常に多いです。
https://twitter.com/JapaneseMl/status/1331939814807986177?s=19
すぐ思いつくやり方としては、①違う統計モデルを使う、②一部の特徴量のみを使う、③一部のeraのみを使う等があります。
①についてはera1-120をただ与えてトレーニングするというやり方では線形回帰、ridge、lasso、xgb、lgbm、NNどれも似たりよったりのval corr推移になりました。NNは載せてませんが似たようなものでした(もちろん作り込み方によるとは思いますが)。
②についてはRichardが前に言及してたこともあり有望かなと思ったのですが、intelligence, dexterity, strength, wisdom, constitution, charismaのグループから一つ選んでトレーニングに使うというシンプル過ぎるアプローチはあまりうまく行きませんでした。利益の出るeraはバラけますが、era199とera211では全モデルがしっかり一緒にドローダウン食らっています。
他にもランダムに選んだり、XGBoostやRandomForestのfeature imporanceで絞り込んだり、borutaで使う特徴量を半分ぐらいに減らしたりと色々やってみましたが、era199と211でやられる傾向も変わりませんでした。Borutaは特徴量を110個まで絞り込んでもval mean 2.5、std 3.0出たので、かなり優秀ではありますが、ことnumeraiに限っては計算量減らせる位のメリットしか感じませんでした。主成分分析系の手法はデータ圧縮でもあるので精度はあまり上がらないイメージです。過学習は避けられそうなので汎化性能は高まってもおかしくないような気もしますが、同じval eraで燃えるのはもはや避けにくいのかもしれません。
③については、単純にトレーニングデータを10分割して10種類のモデルを作りそれぞれのパフォーマンス見たものが以下です。これも同じeraでドローダウンを食らっています。
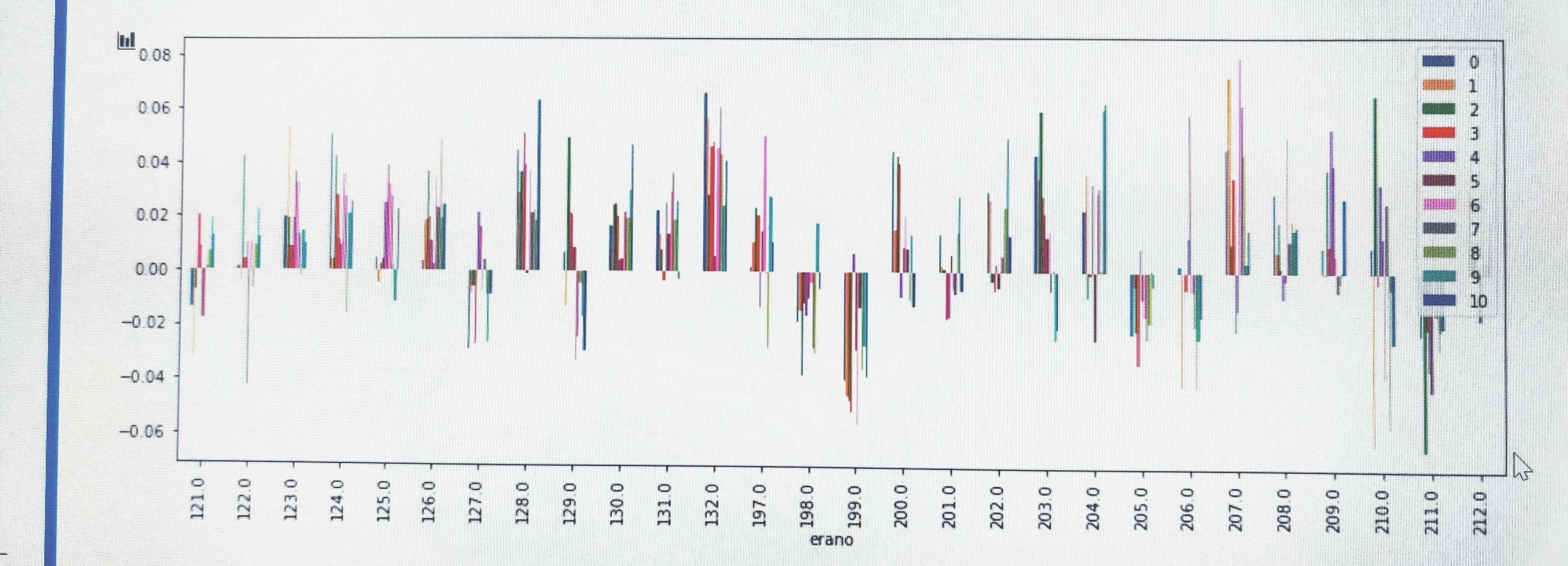
ということで私の試してみた手法の中で唯一意味のあるレベルでval corrの傾向を変えられたのはfeature neutralizationなので、実際にステーキングする際にも中立化した予想としていない予想を両方送るなどして、なんとか大きな損益のブレを避けようとしています。もちろんvalの結果を見てモデルをいじるのはカンニングしながらテストを解いているような要素はありますし、実際にliveのパフォーマンスが上手く分散される保証もないのですが、個人的にはera199と211でガツンとドローダウンするモデルを何個も走らせるよりはcomfortableです。
その他頭がこんがらがっているので文字通り殴り書きになっていますが、こんな事も考えています。
Era1-120でトレーニングするのではなく、それぞれのera毎に120個のモデルを作って予想を平均。
IsBurnEraをTargetにして色々特徴量をぶち込んでみてなんとかそれなりの精度の予想が出せるかどうか。燃えるレジームを検出。
Era毎に作れる特徴量の候補としては
・特徴量間の相関係数(310*310=96100もあって扱いにくい…feature group毎に第2主成分まで取るとかにすれば、144まで減らせる)
・特徴量間の相関係数の平均値、最小値、最大値、ばらつき(標準偏差)、前eraからの変化
Era199のような特別な時期には特徴量間の相関も相当無茶苦茶になっているだろうと思ったわけですが、それは事後的にわかる話であって、特徴量の関係を眺めてみた所で事前にそんな無茶苦茶なマーケットになることを予想するのは無理な話なのでは?という結論に落ち着きつつあります。ストレステストにはなるかもしれませんが、「普通」のマーケットでは役に立たないので、個人的にはvalidationにも使わなくて良いかなと思い始めている位です。
運営に与えられた通りのval erasを使ってホールドアウト法で汎化性能を評価するのではなく、きちんとしたtimeseries cross validationを行いそれをもって汎化性能を評価する。この場合にはval dataも含めてトレーニングしても良いかも。ただし前述の通りあまりにも異常な期間をトレーニングに含めると単に普通の期間での性能が落ちるだけになる可能性もあります。
私はmdoさんのこのスニペットを拝借しました。
https://forum.numer.ai/t/era-wise-time-series-cross-validation/791
Adversarial validationから着想を得て、liveのラウンドに似ている(分類モデルのprobaが高く自信を持ってliveと誤判定されている)トレーニングデータのeraをX個使ってモデルを作成→予想。こちらのスニペットを参考にしましたが、オリジナルはera毎にはなっていません。似ているX個のデータを使っています。時間かかる割に今の所上手く行っていないのですが、もう少しやってみたいとは思っています。
https://forum.numer.ai/t/adversarial-validation/407
極端なデータを均すために0.25-0.75にインプットをクリッピングする。もしくは逆に0と1だけを使う。0と1だけを予測するなど。→いまいち、平均下がるだけ。
予測とターゲットがどうずれてるのか調べてみても良いかも。
Era199と211に強いモデルを作って保険として使う。→将来全く違うパターンでやられるかもしれないし平均も低い。199と211で訓練したモデルそのままではあまりにパフォーマンス悪いので、199と211で訓練したモデルでtraining eraを予想、パフォーマンスの良いeraをX個選んで訓練、という流れでやってみました。Xの数にもよりますが、一応val平均1.7%、199と211で結構プラスになるモデルは作れました。
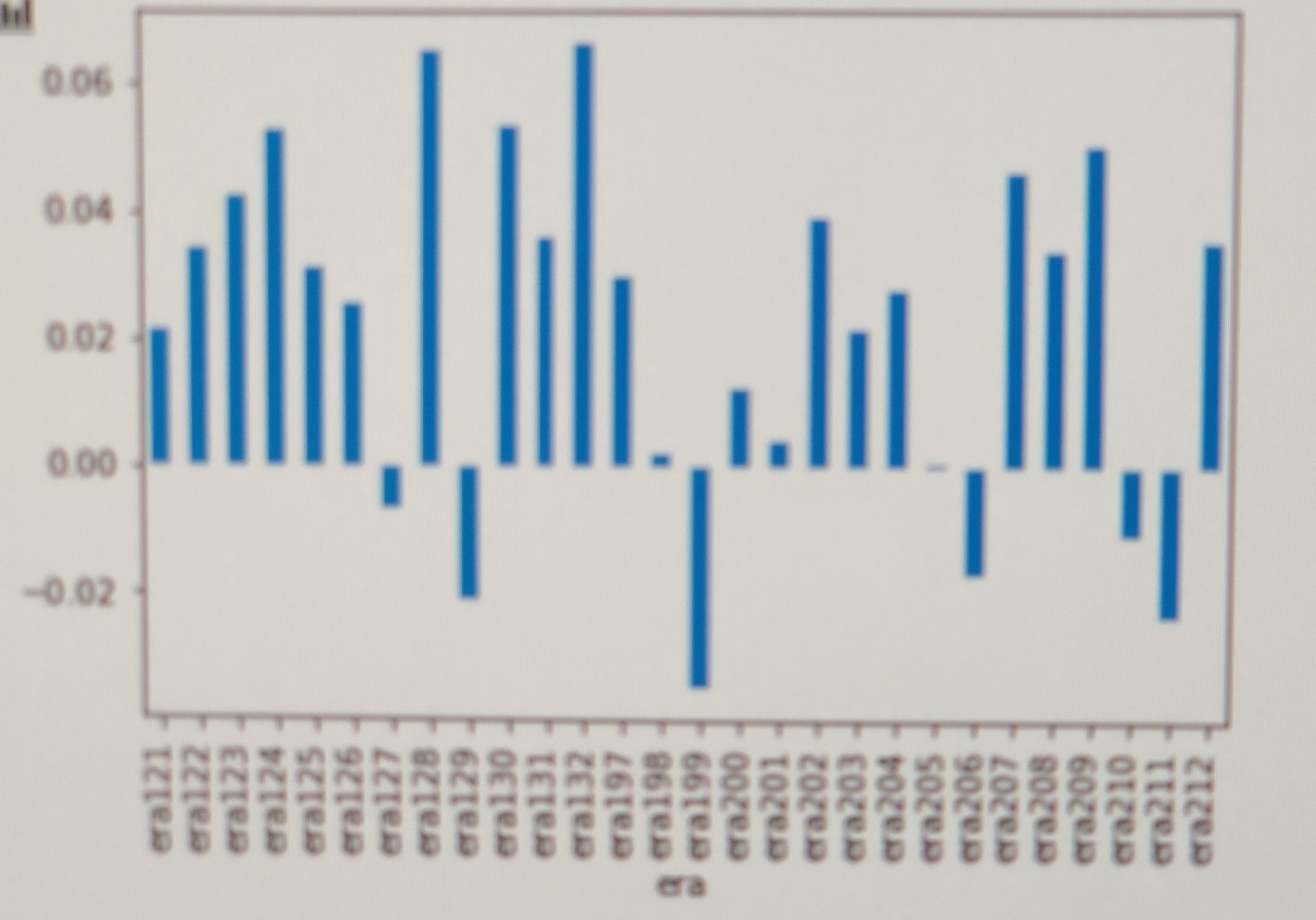
Era boostはやってみましたが、いまいち。個人的にはただのオーバーフィッティングな気がしています。XGBoostバージョンを実装して試してみた結果が以下です。トレーニングeraではera間のブレが減って安定したかもしれませんが、out of sampleでは全然だめでしっかりお馴染みのeraでやられる事がご覧いただけます。
https://forum.numer.ai/t/era-boosted-models/189
トレーニングeraのera毎にサンプル数を絞り込んで学習する。ブースティング系の手法では既に似たようなことやってるのであまり効果なさそうながら、少しはペイアウトのパターンが違うモデルできるかも。
Era毎にfeaturesではなく上位X主成分に対して予想を中立化。良いアイディアかもしれないと思ったのに効果はほとんどなしでした。
以上です。長文を読んで頂きありがとうございました。少しでもヒントになる部分があれば幸いです。Twitterでご連絡頂ければ返信できると思います。コード全部ちょうだい系の方以外はウェルカムですので一緒に頑張りましょう!