IOAI: a side story
tsymba❤️Всем привет! На волне хайпа и по горячим следам написал про первый межнар по ИИ, который прошел в Болгарии буквально позавчера. Мне посчастливилось принимать участие в подготовке и организации; мой основной вклад состоял в разработке трети задач из научного раунда.
Сама история ниже, а вы подписывайтесь на мой канал.
UPD: автор CV поделился своей историей, выкладываю здесь для полноты.

Почему это важно
Когда я был школьником, участие в профильной олимпиаде было обязательным: я был обязан писать олимпиады по математике и информатике в обеих школах, в которых учился. После школьного этапа идут городской (муниципальный), областной\краевой (региональный), заключительный (он же всероссийский). Диплом на всероссийской олимпиаде дает очень мощные привилегии при поступлении в профильные вузы, какое-то количество денег, бесценный опыт и друзей, ну и, конечно, ЧСВ 😎.
А что дальше? А дальше по ряду предметов существуют международные олимпиады. Такие точно есть по математике, физике, химии, лингвистике, некоторым другим предметам, а в частности — по информатике (хотя на самом деле это олимпиада по программированию).
Организовать международную олимпиаду непросто — нужны спонсоры, всемирно уважаемые люди, легитимность, процесс отбора и регистрации, и множество других заморочек. Что дает диплом на международной олимпиаде, решается внутри каждой страны на месте, но для участника это, в первую очередь, вечная всемирная слава 🏆. В частности, строчка в резюме еще до того, как ты начал о таком думать, и зачастую мощный травелатор вместо тропинки в светлое будущее.
Итак, к сути! Некая группа могущественных людей собралась и решила сделать первый межнар по ИИ в Болгарии. Набрали спонсоров, сделали примеры задач, разослали приглашения нужным людям в нужных странах — и все завертелось.

Формат
Формально было два раунда: “практический” и “научный”. В первом я организационно практически не участвовал, поэтому углубляться в него не буду (и, кажется, у него был отдельный призовой зачет, в отличие от, например, межнара по химии с двумя раундами). В этом году была своя атмосфера на практическом раунде — школьники генерировали контент для клипа болгарской певицы Марии 🙂
Научный раунд имел три трека (CV, NLP, ML) и две части (домашнюю и внешнюю) — всего шесть задач. На домашние задачи давалось три недели, но вклад задач составлял всего 5% от суммарной оценки. На онсайт задачи давалось восемь часов — там школьников запирали в отдельной комнате, приставляли надзирателя, выдавали два ноутбука и следили за экранами. А решали ребята следующее:

Задачи
Краткий пересказ домашних задач (только суть, без лора):
- CV🦒🦓: дана уже обученная text-to-image модель (lambdalabs/miniSD-diffusers), надо заставить ее генерировать жирафа, если пишешь про зебру, и наоборот — зебру, если описываешь жирафа. Модель фиксирована, над текстами и текстовой частью изменения проводить нельзя, но можно набрать или нагенерировать данных самому (если выложишь в открытый доступ). Проверяют детектором на жирафах, зебрах, и разных других животных (то есть слона надо тоже уметь рисовать).
- NLP: Классификация хауситской части прошлогоднего датасета африканских новостей на пять топиков. Чтобы буквы не узнали, их поменяли на оные из пары индийских языков. Ограничения на использование эмбеддингов определенной модели (mBERT). В общем, полная zaminamina heyhey.
- ML: даны массивы 💎фиг пойми чего💎 размером 178x8, надо разбить на два класса. Можно пользоваться только деревом решений ограниченной длины из sklearn, гиперпараметры менять нельзя. Метрика — средний recall по обоим классам (aka ROC AUC на бинарных предсказаниях).
На онсайте были задачи по мотивам домашних:
- CV🐄: опять дана диффузионка text-to-image, но теперь надо обязательно рисовать пожарный гидрант, если рисуешь корову. Изначально была очень классная задача, но пришлось ее заменить(
- NLP: все то же самое, но добавили еще два класса новостей. Сильные ограничения на методы.
- ML: даны четырехмерные массивы 💎фиг пойми чего💎 размером 5x5x5x6 с кучей симметрий, нужно по ним предсказать три переменные (регрессия). Из методов можно пользоваться только линейной регрессией. Метрика — взвешенная RMSE.
Добавлю, что на каждую задачу была куча ограничений на тему того, что можно, а чего нельзя: например, для ML я явно прописал, что нельзя, например, обучить нейронку, и брать эмбеддосы из нее в простую модель (можно было обучить автоэнкодер, но лучше не надо). Зато можно было пользоваться интернетом и чат-версией LLM (да, даже во время онсайта!).
У задач был забавный lore, тут я его приводить не буду, но покажу картинки, с которых начинались задачки. К описанию задачи я сгенерировал картинку, на которой совершенно случайно оказался Тимоти Шаламе, остальные авторы задач тоже делали себе картинки. Известны случаи, когда участники (мы следили за их экранами) залипали на девушку из моей второй задачи (в начале поста).

Мотивация
Изначально я пришел в команду, когда там уже зрела идея задачи по ML (тогда трек назывался feature engineering — и этот дух там остался). Но пришлось от этой идеи отказаться, когда пришла информация о том, что есть команды, которые в курсе конкретно именно этого датасета и задачи. У меня страшно подгорело 🍑🔥, и нулевым принципом моей задачи стало то, что она должна быть основана на данных, которых нет в интернете — чтобы это просто не могло повториться.
Основной принцип, которым я руководствовался, когда придумывал задачки: никакого Kaggle🚫! Из всех форматов будущей олимпиады по ИИ я меньше всего хотел, чтобы это были контесты, в которых люди жгли видеокарты, стакали модели, перебирали гиперпараметры и накидывали всевозможные методы, выбивая пятые знаки после запятой. Я глубоко убежден, что это имеет мало общего с ML in the wild, и мне хотелось это донести каким-нибудь образом.
В олимпиадных задачах важно, чтобы существовало какое-то забавное решение, интересный трюк, который в целом дает тебе половину ответа. Очень хотелось, чтобы этот трюк тяжело было загриндить каким-нибудь перебором признаков. С этим я справился частично — трюки были, но они гриндились процентов на 80% (хотя никто из участников не побил авторское решение).
В процессе работы над реализацией задумки я пришел к ограничениям по времени выполнения — вся обработка данных, обучение и инференс должны были укладываться в три минуты (позже — пять). Но задачка все еще казалась простой, поэтому я, вспомнив про data-centric competition от Эндрю Ына, решил, что школьники должны страдать💫. И ограничил модели простейшими, убрав возможность регулировки гиперпараметров — то есть участники имели контроль только над данными, и должны были нагенерировать хорошие признаки.
В итоге это стало сферическим соревнованием по feature engineering в вакууме. Особенно последнее — потому, что это реально были идеальные физические условия (об этом позже). А также потому, что нормисы при первой попытке визуализации данных не поймут ничего.
Откуда задача
Где взять никому не известную задачу? Ту, про которую лучше всех знаешь ты, и в которой в мире мало кто вообще разбирается? Наконец, ту самую, которая никому не интересна и не нужна? Люди, занимающиеся исследованиями, хорошо знают ответ на этот вопрос — я использовал материалы своей диссертации🙃. Общение с людьми вне научной сферы показало мне, что среди всех топиков этот — самый скучный, поэтому дам версию в пару абзацев.
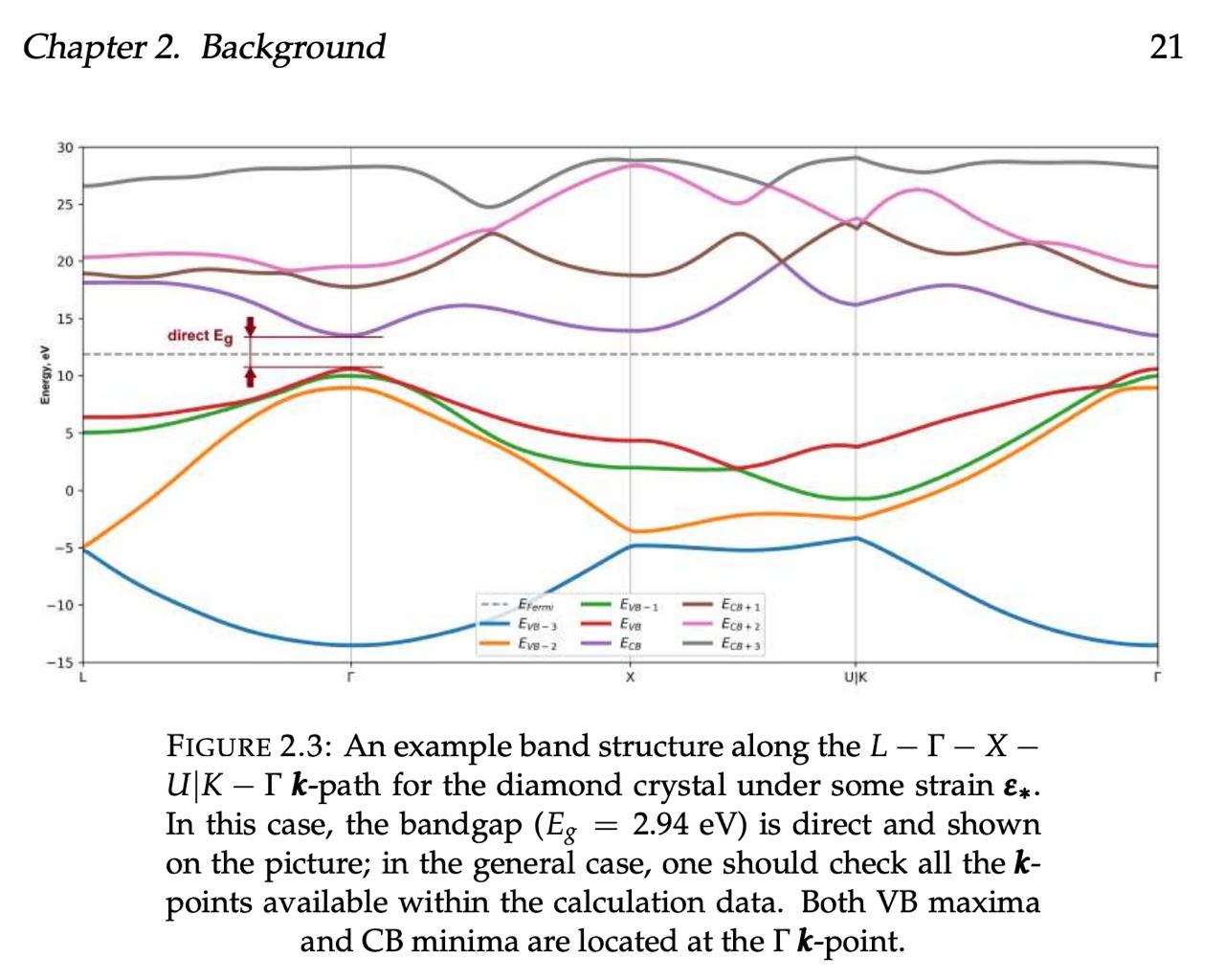
Если взять идеальный кристалл (углерода — алмаз💎, или кремния) и начать его растягивать, то у него поменяются свойства — он может, например, начать проводить ток. Это происходит потому, что в кристалле меняется расстояние между атомами, и электроны взаимодействуют по-другому. Если описать поведение электронов в растянутом кристалле, то можно рассчитать всякие такие свойства и что-то открыть\запатентовать.
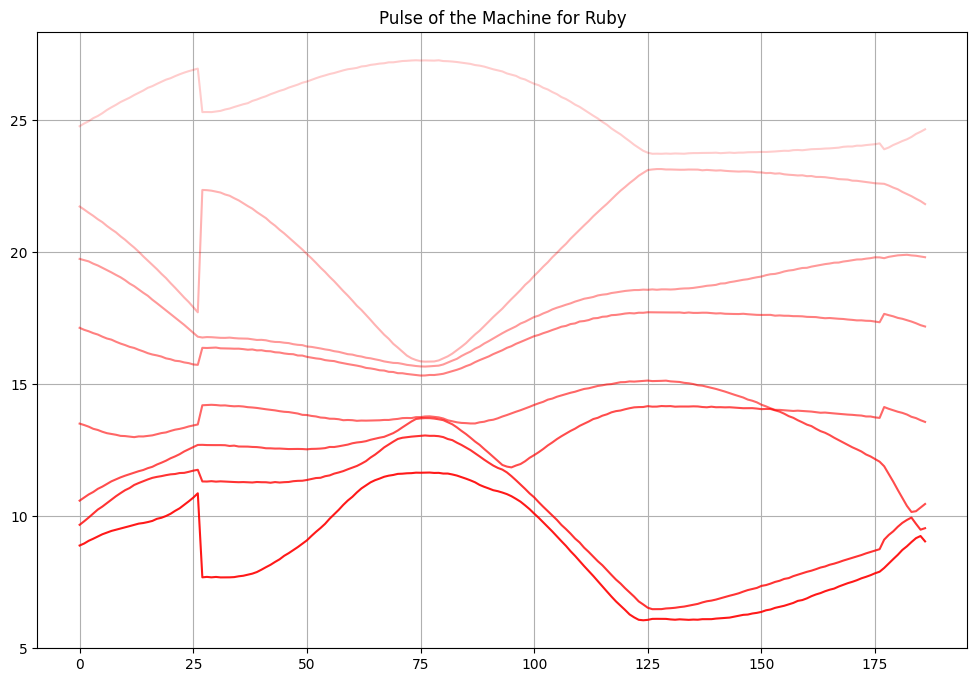
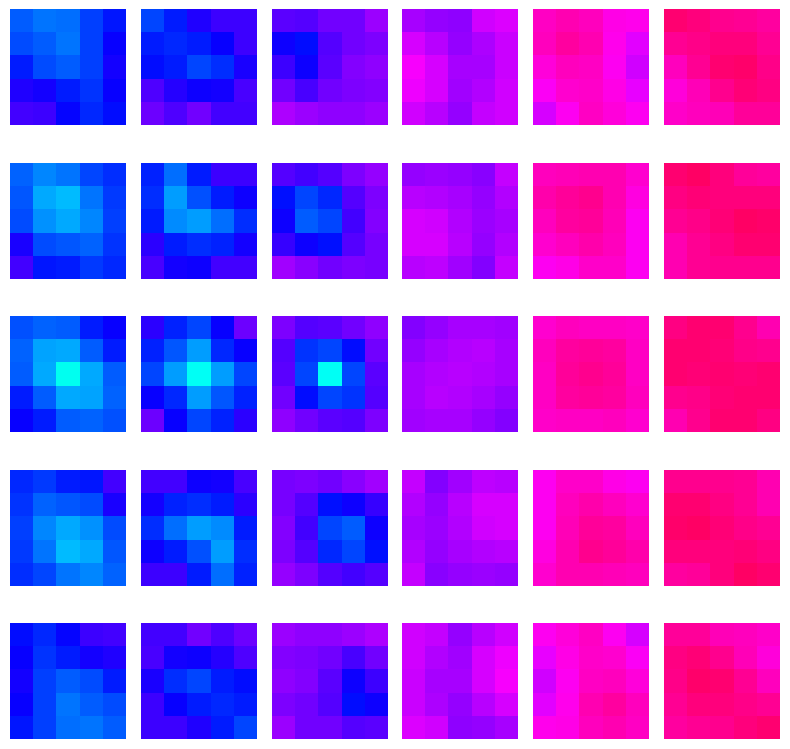
И вот эти графики\многомерные массивы (первое получается из второго хитрой интерполяцией), собственно, описывают поведение электронов в деформированных кристаллах. И признаки, которые требовалось найти в задаче — настоящие физические свойства, которые либо используются для описания (первая задача), либо для получения этих данных (вторая задача) — в общем, явно сильно скоррелированные с данными вещи. Я проработал с похожими данными несколько лет, и потому точно знал, что задача решается.
Как решать и как решали
Вначале я сам попробовал решить задачу простыми методами с этими ограничениями — и немного подкорректировал данные: перемешал, добавил шума, и где-то убрал часть данных. Везде нужно было, превозмогая нечеловеческую природу, немного покрутить данные и поиграться с признаками, чтобы понять, что к чему. Реализма добавляло то, что большая часть данных оказалась мусором🗑️ — в первой задаче хватало трех полос из восьми, во второй — половину точек можно просто выкинуть (в каждом сэмпле).
Я не буду подробно рассказывать про трюки, потому что это не имеет смысла без контекста этих самых данных. Но кратко: в первой задаче надо было просто отнормировать данные по обеим осям и подбирать относительные признаки, во второй — размножить данные шесть раз, используя описанные симметрии, и убрать повторяющиеся столбцы. Все! Не rocket science, но надо знать, уметь, и догадаться. А главное — без этого работает довольно плохо, то есть если просто закинуть данные в NN, то ничего не получится — потому что и связь нетривиальная для кучки обрезанных линейных преобразований, и данных мало (во второй задаче было всего 2024 семпла).
Ребята справились великолепно👏 — я в их возрасте вообще землю ел (не доходил даже до всероса). Команды, которые вышли в топ, догадались до трюков (или их части), а также просто имели широту знаний ML и умели пользоваться LLM и гуглить (платиновый спонсор).
В домашней задаче много команд пыталось обойти ограничения на простоту модели. Они выдумывали хитрые трюки, чтобы прокинуть признаки из моделей покруче, но я настоял на своем и отказывал им в креативном полете мысли, вводя новые ограничения, стараясь сохранить антикэггловский дух соревнования. Это очень сильно усложняло контекст, но зато очень помогло во время онсайта — игра велась по тем же правилам, и почти не было вопросов о том, что делать можно, а чего делать нельзя.
Я был уверен, что в онсайт-таске мое решение побьют, но тут сыграл фактор времени и тяжесть погружения в эти чертовы многомерные массивы🤯. Я знаю, что было жестко, но надеюсь, ребятам понравилось.

Update: как готовили CV
мопед не мой, выкладываю историю автора
Я делал задачу с двумя аспирантами из Болгарии. Как возможные темы прикидывали Dream Booth, отслеживание точек в движении, адверсальные атаки, дипфейки. Мне казалось, что было бы здорово делать в областях, где они могли взаимодействовать как пользователи ещё до участия в олимпиаде, в духе VLM, диффузионных моделей, обратного поиска.
Тогда же в академическом твиттере обсуждали, что генеративные модели не умеют рисовать комнаты без слона. Например, результат по запросу "a well lit room with absolutely no elephants in it".

Мне показалось классным попросить ребят в задаче сделать так, чтобы слоны вообще не рисовались никогда, включая промпты в духе "большое серое животное с хоботом в саванне", в условиях, что всё остальное должно рисоваться так же. У задачи есть ещё несколько плюсов:
- Был не совсем уж тривиальный ход в решении с передачей отрицательного рейта обучения на примеры со слонами. Я помню что встречал его на одном из давних yandex cup и был классный вау-эффект когда придумываешь этот ход.
- Понятно, как делать автоматический скоринг, просто смотри детектором, нарисовался ли слон или нет
- Выражения в духе "не заметили слона в комнате", "слон в посудной лавке" и "to see pink elephants" давали хорошую базу для истории.
Рассказал команде, болгары восхитились (тм). Как базовую модель брали довольно базовую диффузионку mini-diffusers, потому что её можно тренить на Colab во всех регионах (официальный спонсор вычислений на олимпиаде) и потому что её было довольно прямолинейно разобрать на части.
Оставалось сделать родственную задачу для домашней части, где они могли получить опыт работы с моделью. Для этого придумали задачу, где нужно было поменять жирафа и зебру местами, то есть по запросу с зеброй рисовать длинношеее.
Потом всё пошло по плану (кхм), и за неделю до соревнования вместе с финальным тестом для домашки мы случайно отправили условие задачи со слонами, которая предназначалась для очной части соревнования. Слитую задачу, конечно же, нельзя было использовать, поэтому мы срочно придумали новую. Я даже немного выдохнул, потому что на тестировании задачи со слонами были проблемы в духе что датасет на колабе грузился произвольное количество времени от 5 минут до часа, а один базовый прогон тренировки мог занимать до часа, что не очень для 8-часового соревнования.
Новая задача так же использовала mini-diffusers, но все манипуляции были только над латентными представлениями и текстовыми эмбеддингами. Собственно для задачи мы предлагали дорисовывать пожарные гидранты везде, где были коровы; гидранты выбрали потому, что хорошо детектировались для подсчёта скора и как омаж к Google-капче.
Вместо послесловия
Я не смог поучаствовать в организации очно, но, судя по уютному чатику организаторов, все, что могло пойти не так — пошло не так. Вопреки всему, олимпиада состоялась, и награды нашли победителей.
В этом году золото взяли Польша, две команды из Сингапура, и (с большим отрывом и под нейтральным флагом) команда из Летово (это подмосковный топоним, но мне хочется думать, что на самом деле это пластмассовый мир победил). Следующая олимпиада пройдет в Пекине, и я очень надеюсь снова принять участие в ее организации.
Церемония награждения транслировалась на Youtube, и мое сердечко грело то, что школьники в чате оставались школьниками: постили “ГООООЛ”, в шутку восславляли постельные достоинства одного из организаторов, кто-то даже говорил о политике — в общем, все жили свою лучшую жизнь. И вы ее не забывайте жить ❤️