How Modern Data Platforms Survive in a World of Many SQL Engines
Data&AI Insights📖 Источник: medium.com
Как современные платформы данных выживают в мире множества SQL-движков
Статья Мутупаланиаппана Раманатхана, опубликованная 25 января 2026 года на Medium в издании Towards Data Engineering, посвящена вызовам и решениям, с которыми сталкиваются современные аналитические платформы данных в условиях фрагментации SQL-движков. Автор подробно рассматривает причины появления множества SQL-движков в одной экосистеме, проблемы, связанные с несовместимостью диалектов SQL, и предлагает концептуальные подходы к проектированию платформ, способных сохранять корректность и переносимость аналитической логики. В статье приводятся конкретные примеры, технические детали и прогнозы развития архитектур аналитических систем.
Миф о «стандартном SQL» и проблема фрагментации
Автор начинает с развенчания распространённого заблуждения, что SQL является универсальным языком для работы с данными. На практике каждый движок реализует собственный диалект, который отличается:
- Поведением функций (например, разная реализация агрегатных или строковых функций)
- Семантикой соединений (JOIN), включая порядок и типы соединений
- Особенностями оконных функций и их граничных условий
- Правилами неявного преобразования типов (type coercion)
Эти различия, поначалу кажущиеся незначительными, на больших масштабах приводят к тому, что один и тот же SQL-запрос может возвращать разные результаты в зависимости от движка. Это ведёт к потере доверия к метрикам и аналитическим данным, поскольку ошибки проявляются неявно, без явных сбоев.
Почему использование множества SQL-движков неизбежно
Множество SQL-движков в одной организации — это не результат неопределённости, а осознанный выбор, вызванный следующими факторами:
- Оптимизация затрат на разные типы рабочих нагрузок (например, дешёвое хранение и дорогие вычисления)
- Тонкая настройка производительности под специфические паттерны запросов
- Разделение интерактивной аналитики и пакетной обработки данных
- Гибкость выбора поставщиков и снижение рисков зависимости от одного вендора
В результате формируется гетерогенный стек аналитики, где смена движков (engine churn) становится постоянным процессом, а не разовой миграцией.
Реальные издержки фрагментации SQL
В статье выделяются два типа издержек:
- Видимые — ручная переработка запросов, поддержка параллельной логики, отладка несоответствий.
- Скрытые — замедление экспериментов, повышение рисков в бизнес-отчётности, узкие места в работе платформенных команд, отвлечение инженеров от аналитики на задачи трансляции запросов.
В итоге платформа перестаёт масштабироваться не из-за технических ограничений производительности, а из-за «семантического дрейфа» — постепенного расхождения смыслов и результатов запросов в разных движках.
Проектирование аналитических платформ для меняющегося мира
Ключевой инсайт статьи — успешные платформы данных изначально проектируются с допущением, что движки будут меняться. Для этого они:
- Отказываются от жёсткой привязки аналитической логики к конкретным движкам
- Вводят уровни абстракции, которые сохраняют смысл запросов, позволяя менять движки без потери корректности
- Централизуют управление сложностью, концентрируя её в одном месте, а не распределяя по всей платформе
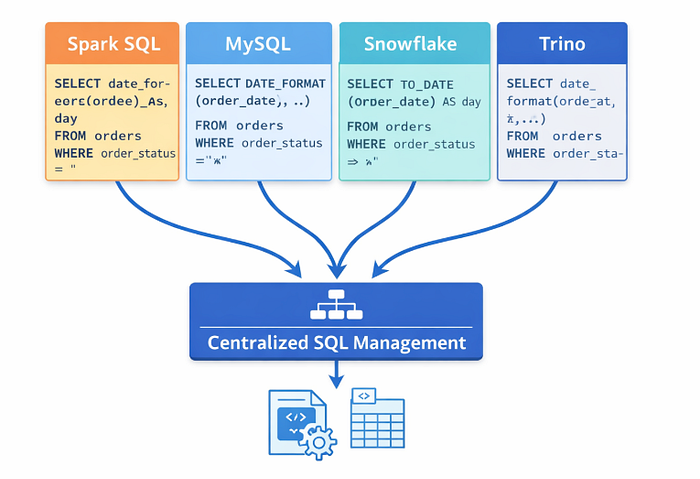
Иллюстрация: Множество SQL-движков и централизованная система управления
Такой подход не устраняет сложность, но позволяет контролировать её и снижать риски, связанные с фрагментацией.
Заключение и перспективы развития
Автор анонсирует продолжение темы, в котором будет рассмотрено, почему большинство попыток обеспечить переносимость SQL-запросов с помощью текстовых преобразований не работают, и какие архитектурные паттерны действительно эффективны на уровне корпоративных систем.
В статье подчёркивается, что современные аналитические платформы должны быть построены на принципах переносимости и адаптивности, а не на постоянстве и жёсткой привязке к конкретным технологиям. Это позволяет организациям сохранять доверие к данным, ускорять инновации и управлять рисками в условиях быстро меняющегося технологического ландшафта.
Итог
Статья Мутупаланиаппана Раманатхана раскрывает критическую проблему современного мира аналитики — фрагментацию SQL-движков и её влияние на корректность и масштабируемость платформ данных. Автор приводит конкретные причины появления множества движков, детально описывает технические различия в диалектах SQL и их последствия. Он показывает, что традиционный подход с одним движком устарел, а новые платформы должны строиться с учётом постоянных изменений и разнообразия технологий. Главным решением становится введение абстракций и централизованное управление сложностью, что позволяет сохранить переносимость и доверие к аналитической логике. В дальнейшем автор планирует раскрыть успешные архитектурные паттерны, обеспечивающие устойчивость и масштабируемость в условиях множественности SQL-движков.
📢 Информация предоставлена телеграм-каналом: Data&AI Insights
🤖 Data&AI Insights - Ваш источник инсайтов о данных и ИИ