Hadoop
Никита ВолодарскийHadoop можно рассматривать как систему-набор open-source программ, которые любой может использовать как "основу" для операций с большими данными (big data).
Система Hadoop
Можно сказать, что Hadoop состоит из "модулей", каждый из которых выполняет определенную задачу, необходимую для работы системы, предназначенной для анализа больших данных.
Распределенная файловая система (HDFS)
Основополагающим модулем Hadoop'а можно считать Распределенную файловую систему (HDFS - Hadoop Distributed File System). HDFS позволяет хранить данные на большом количестве связаных между собой устройств, или, по просту говоря, на кластере. Каждый отдельный компьютер в кластере принято называть "Нода" от английского слова Node – узел.
Подробнее про HDFS предлагаю почитать по ссылке (рус.) или в документации Apache Hadoop.
MapReduce
MapReduce назван так из-за операций, которые выполняет этот модуль –считывание данных из базы данных, помещение их в формат, подходящий для анализа (Map), и выполнение математических операций, например, подсчет кол-ва элементов в выборке (Reduce).
Вот пример операции MapReduce:
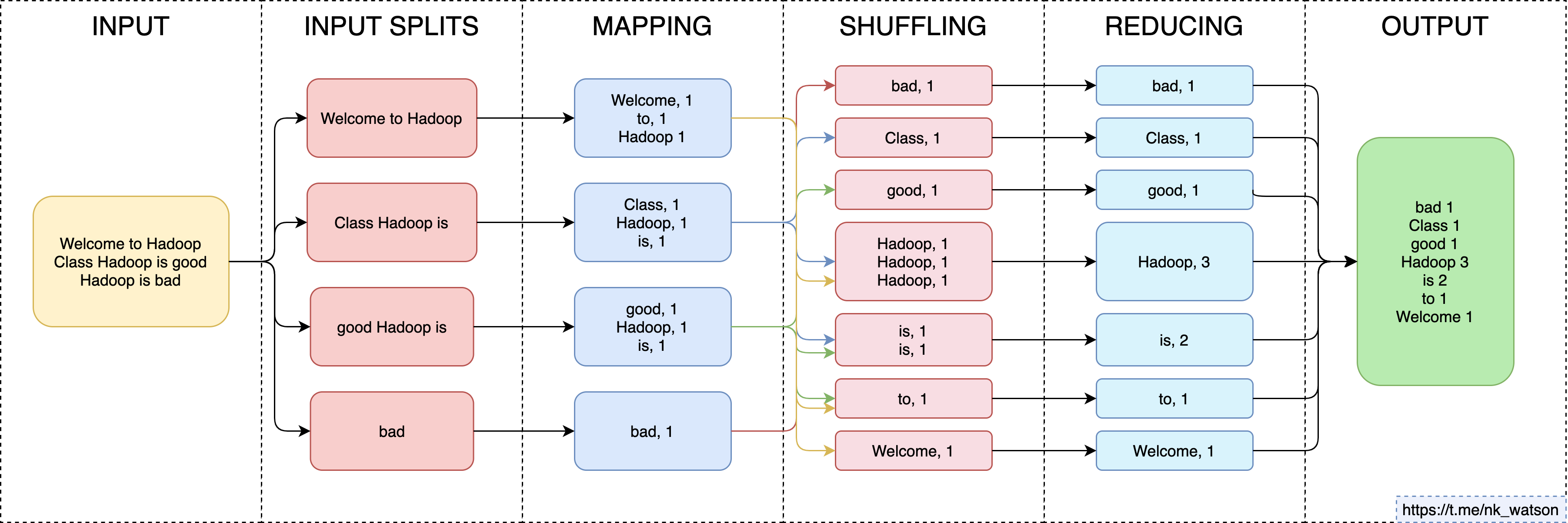
Подобные вычисления позволяют проводить различные математические операции с данными, которые распределены на огромном количестве компьютеров. Благодаря такому подходу становится возможным использование ресурсов каждого отдельного компьютера в кластере для решения одной задачи (одного запроса к базе данных). Например, подсчет количества слов в постах в твиттере.
Абстрактно это можно представить так:
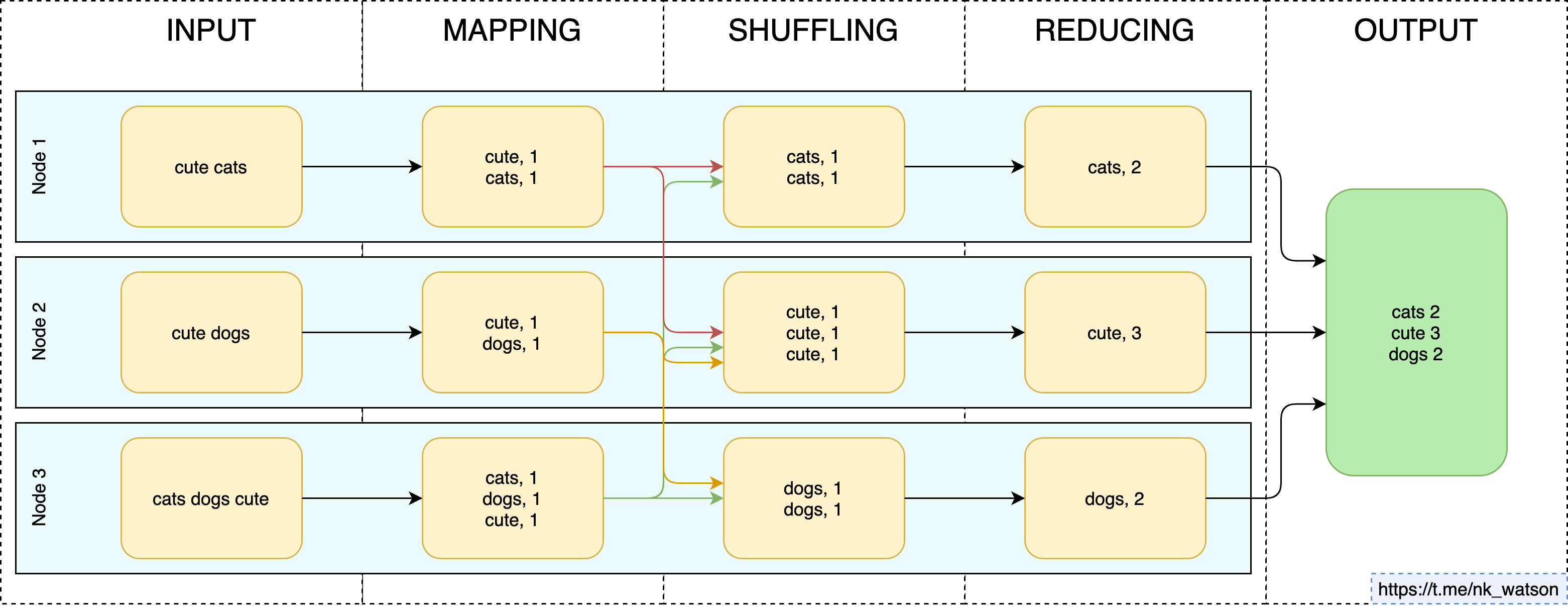
Подробнее читайте в классной статье на хабре.
YARN
Еще одним модулем является YARN – планировщик ресурсов, распределяющий ресурсы между приложениями. В частности YARN может выделять ресурсы на задачи MapReduce. Если таких задач будет много, YARN будет определять, кому важнее получить ресурсы.
YARN расшифровывается, как "Yet Another Resource Negotiator", что означает "Еще Один Ресурсный Планировщик".
Более сложным языком, очень подробно и безумно интересно про Yarn написано по ссылке.
И это всё?
Нет, сейчас инфраструктура Hadoop состоит из огромного количества модулей.
Подробнее можно почитать, например, по ссылке, или самостоятельно погуглить модули с картинки ниже:
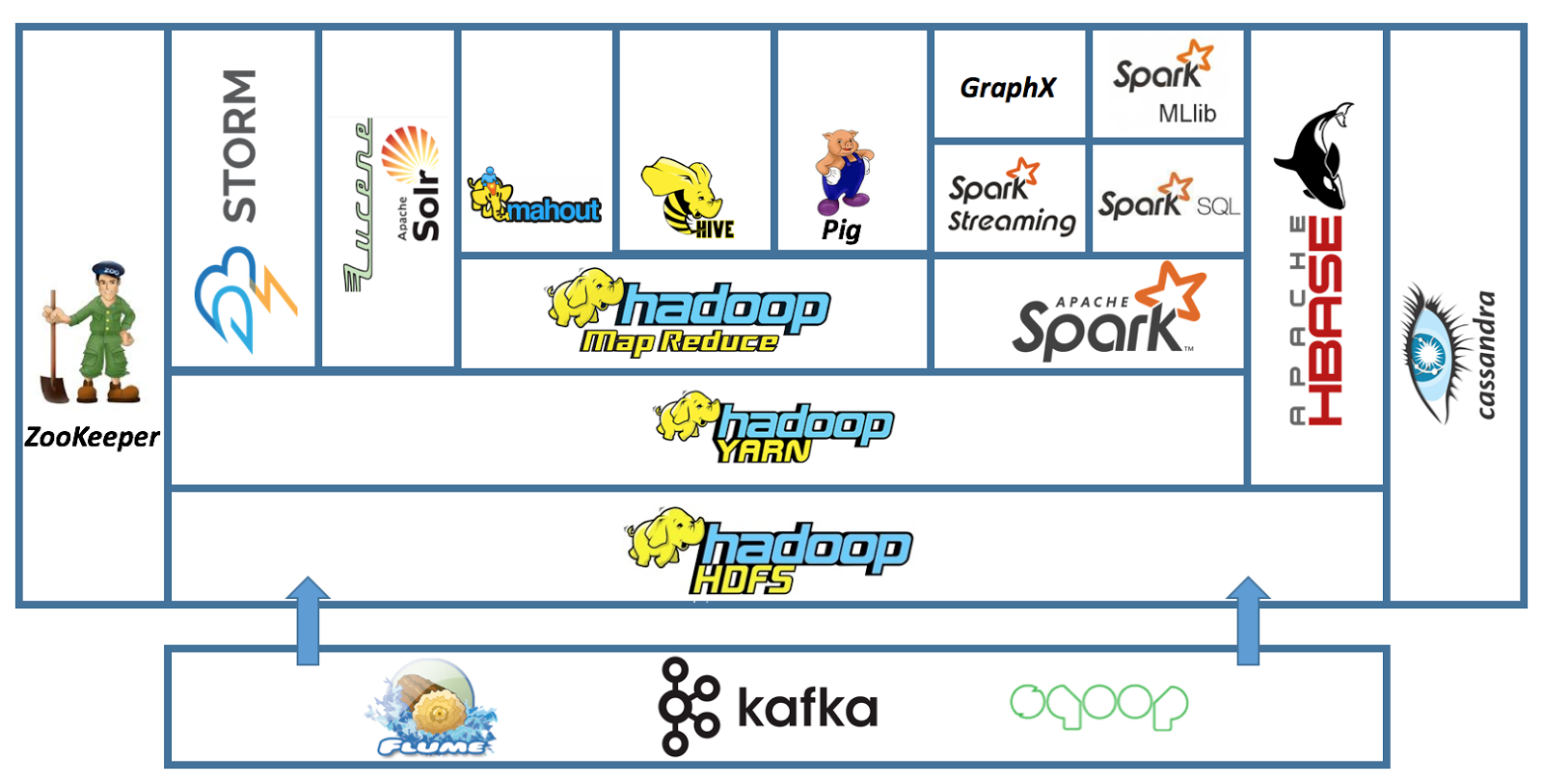
Для чего стоит применять технологии системы Hadoop.
- Для обработки очень больших (например, Петабайт) объемов данных. Особенно система Hadoop хороша для анализа "холодных" данных.
- Для хранения разнообразных наборов данных: текстовые файлы, картинки, аудио файлы, и др. Hadoop отлично подходит для создания Data Lake.
Hadoop НЕ подходит:
- Для анализа данных в реальном времени. Т.к. из-за архитектурных особенностей обработка данных в Hadoop'e занимает намного больше времени, чем аналогичная обработка в реляционных базах данных. Обработка данных в Hadoop иногда может занимать до нескольких дней.
- Для использования в качестве OLTP – система обработки транзакций в реальном времени. Например, Hadoop не подойдет для систем покупки товаров или бронирования отелей.
Да, Hadoop довольно медленный. Но при этом у него огромное количество других плюсов, которые заставляют крупнейшие компании России применять его на практике.