GraphPad Prism. Описательная статистика
https://t.me/ad_researchИтак, первым делом нужно будет установить программу на свой компьютер. Тем у кого Windows может помочь вот эта папочка. Перед тем как нажимать на какие-то приложения - обязательно прочитай файл Crack.txt.

Далее запускаем программу и видим приветственное окно, где нам предлагается выбрать тип таблицы и организацию данных в ней. Пройдёмся пока обзорно по этому окну, в будущем ещё поработаем с каждой таблицей отдельно.

В левой части окна нам предлагается выбрать, какую таблицу для наших данных создать. Если пощёлкать по ним, то можно увидеть визуальные примеры и объяснения, но я не оставлю тебя самому с этим разбираться, а дам краткие пояснения ниже.
1.XY - это таблица для зависимых переменных. Можно использовать когда есть изменение параметра во времени (например, измерения кинетики), для кривых доза-ответ, а также для коррелирующих данных и последующего расчёта регрессий.
2. Column - это таблица для данных с одной группирующей переменной, то есть различающихся только по одному фактору. Например, это могут быть экспериментальные группы: крысы, которым давали лекарство и крысы, которым давали плацебо. Но пол крыс мы здесь уже учесть не можем. Зато можем в следующем типе таблиц.
3. Grouped - здесь мы можем учесть две группирующие переменные, например, пол и тип терапии. К сожалению, призма не позволяет делать более двух таких переменных, например, помимо типа лечения и пола учитывать ещё и линию животного. В тех редких случаях, когда мне это было нужно, я переходила в Statistica или в SPSS.
4. Contingency - это анализ таблиц сопряжённости. Мы про них пока не говорили, это нужно для анализа качественных данных. Например, если мы хотим посчитать есть ли разница в проценте заболевших среди тех, кто делал прививку и тех, кто её не делал.
5. Survival - анализ выживаемости. Тоже используется для анализа качественных исходов типа жизнь или смерть. Но в целом, также может анализироваться выписка из больницы и более позитивные вещи.
6. Parts of whole - и это тоже для качественных данных, по сути здесь мы сравниваем проценты от общего числа событий и рисуем красивые круговые диаграмки. Например, можем отразить, что на момент написания этого поста TGstat показывает, что аж 84% подписчиков АДового рисёрча читают посты канала, а 16% видимо ждут подходящего случая.
7. Multiple variables - выглядит внутри почти как Column, но есть большая разница. В Column у нас была одна переменная (например, вес тела) в разных группах (например, препарат и плацебо). Здесь же у нас все переменные разные. В строках у нас находится пациенты, у которых измеряют вес (переменная 1), рост (переменная 2), уровень глюкозы (переменная 3) и так далее. Такой тип таблиц используется для расчёта корреляций между переменными и последующего регрессионного анализа. Опять же, если нужно отследить изменения этих переменных и их взаимосвязи во времени или в разных группах - призма бессильна. Только исследовать каждый параметр как отдельную переменную, из-за чего можно потерять часть результата.
8. Nested - по смыслу это почти как column, то есть мы сравниваем группы только по одному фактору. Но этот вариант нужен, когда есть технические повторности, то есть один и тот же параметр измеряется несколько раз. Например, для одного пациента измерили уровень глюкозы трижды, чтобы повысить точность. Часто технические повторности просто усредняют и уже в какой-нибудь column записывают финальный результат, но тогда при анализе и сравнении групп не будет учитываться погрешность прибора.
Теперь по правой части.
9. Здесь нам предлагается выбрать, начнём мы работать со своими данными или же потренируемся для начала на встроенных датасетах (sample data). Сейчас и в следующих постах мы будем работать только на тренировочных данных.
10. Опции зависят от предыдущего выбора. В случае, если мы выбираем свои данные, то далее всё зависит от типа таблицы. Нас могут спросить сколько повторностей, связаны выборки или нет или предложат просто ввести финальные данные для построения графика. Если же мы выбираем тренировочные данные, то далее нам нужно будет выбрать датасет по типу анализа, который мы бы хотели проводить.
Сегодня поработаем с таблицей Column и самыми первыми тренировочными данными Entering replicate data. Выбираем их как на картинке ниже и нажимаем Create.

Перед нами появляется рабочая среда. Разберём пока некоторые её части.

- Сразу выскакивает подсказка от программы, что за тренировочные данные и как они организованы. Для удобства работы её можно свернуть, кликнув на правый верхний угол. В целом, призма настолько дружелюбная, что мои посты особо не нужны, потихонечку разобраться можно и самостоятельно.
- Далее посмотрим на наши данные. У нас есть три группы - без лечения, плацебо и с лечением. Отличаются очевидно по одному параметру: какую таблетку им давали (или не давали). Не понятно, что за параметр измерялся, но в каждой группе у нас 5 повторностей. Пока нам это не важно, но пусть это будет концентрация фолиевой кислоты (витамин B9) в нг/мл. Большим недостатком призмы является неспособность в арифметические действия внутри таблиц. То есть, если тебе для анализа нужен индекс массы тела, то в призму должны идти значения именно ИМТ. Придётся измерить рост и вес, в отдельной программе, например, в Excel рассчитать ИМТ и финальный результат уже перенести в призму для анализа и построения красивых графиков.
- В левой части будут сгруппированы все наши таблицы и связанные с ними результаты анализа, графики и тд. Создать новую таблицу можно через New Data Table и тогда выскочит такое же меню, как было при запуске программы.
- Здесь можно записать информацию о проекте: дату эксперимента, его номер, номер лабжурнала, название проекта, ответственного за эксперимент, описать протокол и добавить какие-то заметки. Если в лаборатории следят за документацией, то это всё должно быть заполнено, но чаще всего вкладка игнорируется
- Здесь будут все результаты анализа данных
- А здесь будут графики для каждой таблицы
- Layouts нужны, если ты хочешь собрать несколько графиков на одной картинке.
- Ну а мы нажимаем на кнопку анализ на верхней панели и без каких-либо предварительных ласк переходим к анализу данных.

В призме различные методы анализа привязаны к типу таблиц, что в целом достаточно логично. Однако, из-за того как по-разному организованы данные сделать описательную статистику в таблице Grouped у нас не получится - придётся разбивать каждую подгруппу на отдельный столбец и переходить в Column. Из-за этого и отсутствия возможности производить операции с данными я часто сочетаю эксель и призму.
Теперь заглянем в описательную статистику для Column analyses и выберем Descriptive statistics так, как это показано на скрине выше. Обрати внимание, что в правой части можно выбрать отдельные группы, которые будем описывать, но сегодня предлагаю выбрать все и нажать ОК. Следующее окошко предлагает нам выбор, что именно считать.

- Здесь находятся базовые меры центральной тенденции и разброса: минимум и максимум и размах; квартили (медиана, 1 и 3 квартиль); Mean - среднее, SD - стандартное отклонение, SEM - стандартная ошибка среднего и сумма всех значений в колонке.
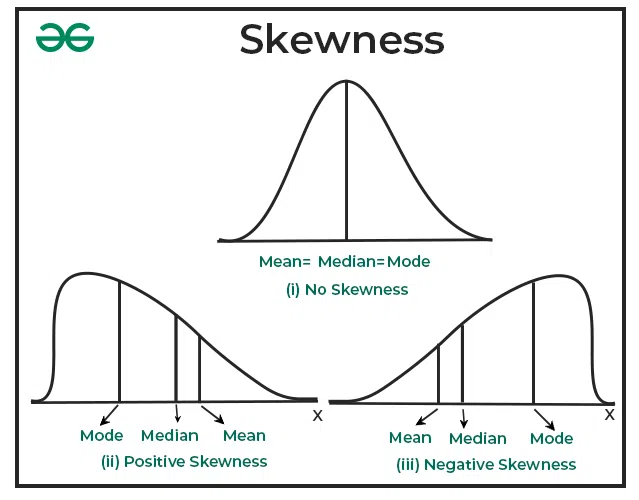
- Здесь более интересные параметры, о которых мы ещё не говорили: Coefficient of variation (коэффициент вариации) - это отношение стандартного отклонения к среднему значению и оно отражает насколько сильно изменяются наши данные относительно своего среднего. Skewness and kurtosis (асимметрия и эксцесс) - это параметры, которые отражают форму распределения, а точнее его соответствие симметричному нормальному, где эти параметры равны 0. Ну а с процентилями мы уже были знакомы ранее. В это окошко через знак ; можно вбить сколько угодно разных процентилей

3. Здесь же можно посчитать среднее геометрическое, гармоническое и квадратическое, если вдруг это нужно.
4. Здесь для некоторых мер центральной тенденции можно посчитать доверительные интервалы. Мы ранее обсуждали что это такое и считали его для среднего.
5. Этот раздел будет работать для таблиц типа Nested, когда есть подстолбцы с техническими повторностями. Тогда программа спрашивает как ей считать эти параметры: сначала усреднить повторности, а затем считать параметры по столбцу, посчитать для каждого подстолбца отдельно или вообще воспринимать все значения как единый датасет. В будущем ещё вернёмся к этому
6. Здесь у нас спрашивается сколько знаков после запятой мы хотим видеть
7. И здесь нам предлагают запомнить выбранные параметры как параметры по умолчанию.
Нажимаем ОК и сразу оказываемся на вкладке с результатами. Собственно здесь в виде таблицы представлены все запрошенные нами параметры.

Обрати внимание, что в левой части во вкладке Results появились результаты нашего анализа (1). А если мы хотим что-то поменять в нём, то необязательно возвращаться к исходной таблице, а можно нажать Descriptive statistics в левом верхнем углу и вернуться к окошку с выбором параметров.
Вот так просто и красиво считаются параметры выборок в призме, надеюсь, что этот материал был полезен. А в следующий раз я покажу на примере этих же данных как работать с графиками.