Git для Анализа Данных 2 часть.
https://t.me/ai_machinelearning_big_datadef main(repo_path):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
sgd = SGDClassifier(max_iter=100) # <-- обновим значение
trained_model = sgd.fit(train_data, labels)
dump(trained_model, repo_path / "model/model.joblib")
Это единственное изменение, которое необходимо сделать. Повторим обучение и оценку, запустив train.py и evaluate.py:
python src/train.py python src/evaluate.py
При этом обновятся файлы model.joblib и precision.json. Зафиксировать результаты в кэше DVC:
dvc commit
DVC выведет вопрос, действительно ли мы хотим внести изменения, отвечаем y.
Помним, что dvc commit работает иначе, чем git commit, и используется для обновления уже отслеживаемого файла. Это не удалит предыдущую модель, а создаст новую.
Добавим и зафиксируем внесенные изменения в Git:
git add --all git commit -m "Change SGD max_iter to 100"
Добавим тег:
git tag -a sgd-100-iter -m "Trained an SGD Classifier for 100 iterations" git push origin --tags
Отправим изменения на GitHub и в удаленное хранилище DVC:
git push --set-upstream origin sgd-100-iter dvc push
Теперь можно переключаться между ветками Git и DVC.
git checkout first_experiment dvc checkout
Результаты наших экспериментов представлены в виде разных версий кода и моделей, к которым мы быстро можем получить доступ.
Что скрывается внутри DVC-файлов
Откроем текущий dvc-файл модели: data-version-control/model/model.joblib.dvc. Содержимое примерно следующее:
md5: 62bdac455a6574ed68a1744da1505745outs: - md5: 96652bd680f9b8bd7c223488ac97f151 path: model.joblib cache: true metric: false persist: false
Файлы DVC – это файлы c YAML-разметкой. Информация хранится в парах ключ-значение и списках. Первый ключ – md5, за которым следует строка, казалось бы, случайных символов.
MD5 – популярный алгоритм хеширования. Хеширование использует содержимое файла, чтобы создать строку символов фиксированной длины. Такая строка называется хешем или контрольной суммой. Длина строки – независимо от размера исходного файла – составляет 32 символа.
Два одинаковых файла имеют одинаковый хеш. Если в одном из файлов изменится хотя бы один бит, хеши перестанут совпадать. DVC использует свойства MD5 для достижения двух важных целей:
- чтобы отслеживать, какие файлы были изменены, просто взглянув на их хеш-значения;
- определять, когда два больших файла совпадают – достаточно хранить только одну копию.
В рассматриваемом примере есть два значения md5. Первый описывает сам dvc-файл, а второй – файл model.joblib.path – путь к файлу модели относительно рабочего каталога. Логическое значение cache определяет, должен ли DVC кэшировать модель.
Примечание. Дополнительные сведения о dvc-файлах можно почерпнуть в официальной документации.
Совместная работа
Освоенного рабочего процесса достаточно, если вы единственный, кто использует оборудование, на котором проводятся эксперименты. Однако многим командам для работы приходится совместно использовать мощные машины.
Когда с данными работают несколько пользователей, не хочется плодить множество копий одних и тех же датасетов. Для экономии места DVC позволяет настроить общий кэш. Когда мы инициализируем репозиторий DVC с помощью dvc init, DVC помещает кэш в папку .dvc/cache. Этот путь можно изменить – для наглядности создадим новую папку shared_cache где-нибудь за пределами папки репозитория. Укажем DVC использовать эту папку в качестве кэша:
dvc cache dir путь_к_shared_cache
Каждый раз, когда мы запускаем dvc add или dvc commit, данные будут копироваться в эту папку. Когда мы используем dvc fetch для получения данных из удаленного хранилища, они попадают в общий кэш, а dvc checkout перенесет их в рабочий репозиторий.
Если вы следовали примерам руководства, то все файлы сейчас находятся в папке .dvc/cache. Сейчас логично переместить данные из кэша по умолчанию в новый общий кэш:
mv .dvc/cache/* путь_к_shared_cache
Теперь все пользователи на компьютере могут указать в качестве кэша репозитория общий кэш.
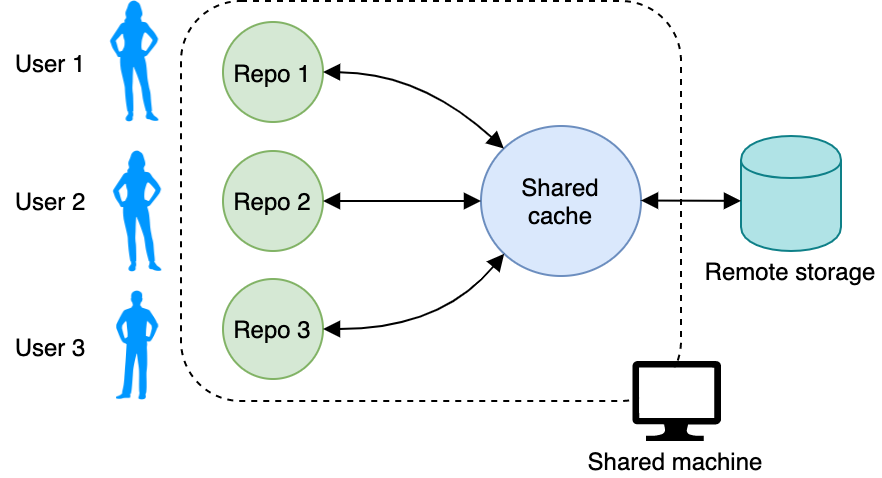
Проверив файл репозитория .dvc/config, мы увидим, что появился новый раздел:
[cache] dir = путь_к_shared_cache
Но как это помогает сэкономить место? Вместо того чтобы хранить копии одних и тех же данных в локальном репозитории, общем кэше и других репозиториях на машине, DVC позволяет использовать ссылки – типа reflink, symlink (символические) или hardlink (жесткие ссылки). DVC будет пытаться использовать по умолчанию reflink, однако если ОС не поддерживает рефссылки, DVC будет создавать копии. Больше о типах файловых ссылок можно узнать в документации DVC.
Если кратко, то поведение кеша по умолчанию можно изменить, указав параметр конфигурации cache.type, подставив вместо тип_ссылки значение symlink, reflink, hardlink или copies:
dvc config cache.type тип_ссылки dvc checkout --relink
Дополнительное пространство. Если в репозитории или кэше есть неиспользуемые модели или файлы данных, можно сэкономить пространство, очистив репозиторий с помощью сборщика мусора dvc gc.
Создаем воспроизводимый конвейер Data Science
Вот краткий обзор шагов, которые мы сделали к настоящему времени для обучения модели машинного обучения:
- Получение данных.
- Подготовка данных.
- Обучение модели.
- Оценка результатов обучения.
Вы могли заметить, что при изменении параметров некоторые шаги мы повторяли вручную. Процесс можно автоматизировать, объединив последовательность действий в конвейер DVC, запускаемый единственной командой.
Создадим новую ветку и назовем ее sgd-pipeline:
git checkout -b sgd-pipeline
Используем эту ветку, чтобы повторно запустить эксперимент в виде конвейера DVC. Конвейер состоит из нескольких этапов и выполняется с помощью команды dvc run. Каждый этап состоит из трех компонентов:
- Входные объекты,
dependencies - Выходные объекты,
outs - Выполняемая команда,
command
Командой может быть все, что мы обычно запускаем в командной строке, в том числе файлы Python.
Поскольку мы успели уже вручную добавить под управление DVC много файлов, DVC запутается, если мы попытаемся создать те же файлы с помощью конвейера. Чтобы этого избежать, сначала удалим CSV-файлы, модели и показатели с помощью dvc remove:
dvc remove data/prepared/train.csv.dvc \
data/prepared/test.csv.dvc \
model/model.joblib.dvc --outs
Итак, мы начинаем конвейер с запуска prepare.py. Передаем команде dvc run необходимые данные:
- Dependencies (ключ
-d):prepare.pyи данные вdata/raw - Outs (ключ
-o):train.csvиtest.csv - Command:
python prepare.py
Ключ -n используем для создания имени этапа:
dvc run -n prepare \
-d src/prepare.py -d data/raw \
-o data/prepared/train.csv -o data/prepared/test.csv \
python src/prepare.py
DVC создаст два файла: dvc.yaml и dvc.lock. Что можно увидеть в dvc.yaml:
stages: prepare: cmd: python src/prepare.py deps: - data/raw - src/prepare.py outs: - data/prepared/test.csv - data/prepared/train.csv
Элемент верхнего уровня stages имеет вложенные элементы, по одному для каждого этапа. Пока у нас только один этап prepare. По мере того как мы будем наращивать конвейер, в файле будут добавляться элементы. Технически можно не вводить команды dvc run в командной строке, а создавать или варьировать этапы в этом файле.
У каждого dvc.yaml есть соответствующий файл dvc.lock, также в формате YAML:
prepare:
cmd: python src/prepare.py
deps:
- path: data/raw
md5: a8a5252d9b14ab2c1be283822a86981a.dir
- path: src/prepare.py
md5: 0e29f075d51efc6d280851d66f8943fe
outs:
- path: data/prepared/test.csv
md5: d4a8cdf527c2c58d8cc4464c48f2b5c5
- path: data/prepared/train.csv
md5: 50cbdb38dbf0121a6314c4ad9ff786fe
Добавление хэшей MD5 позволяет DVC отслеживать входные и выходные данные и определять, изменяется ли какой-либо из этих файлов. Таким образом, вместо отдельных файлов dvc для train.csv, test.csv и model.joblib, все отслеживается в файле .lock.
Мы автоматизировали первый этап конвейера. Представим его в виде блок-схемы.

Следующий этап – обучение:
dvc run -n train \
-d src/train.py -d data/prepared/train.csv \
-o model/model.joblib \
python src/train.py

Финальный этап – оценка модели:
dvc run -n evaluate \
-d src/evaluate.py -d model/model.joblib \
-M metrics/accuracy.json \
python src/evaluate.py
Обратите внимание, что вместо ключа -o мы использовали ключ -M. DVC обрабатывает метрики иначе, чем другие выходные данные. DVC будет знать, что в accuracy.json хранится показатель производительности модели:
dvc metrics show metrics/accuracy.json: accuracy: 0.6996197718631179

Теперь весь рабочий процесс представлен на одном изображении. Не забудем сделать тег для новой ветки и отправить изменения на GitHub и DVC:
git commit -m "Rerun SGD as pipeline" dvc commit git push --set-upstream origin sgd-pipeline git tag -a sgd-pipeline -m "Trained SGD as DVC pipeline." git push origin --tags dvc push
Теперь самое интересное! Воспользуемся для обучения классификатором random forest. Обычно он работает эффективнее, чем SGDClassifier, и потенциально может дать лучшие результаты. Начнем с создания и проверки новой ветки, которую назовем random_forest:
git checkout -b "random_forest"
Изменим src/train.py, чтобы использовать RandomForestClassifier вместо SGDClassifier:
from joblib import dump
from pathlib import Path
import numpy as np
import pandas as pd
from skimage.io import imread_collection
from skimage.transform import resize
from sklearn.ensemble import RandomForestClassifier # <-
# ...
def main(path_to_repo):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
rf = RandomForestClassifier() # <-
trained_model = rf.fit(train_data, labels) # <-
dump(trained_model, repo_path / "model/model.joblib")
Поскольку файл train.py изменился, стал другим и его хеш MD5. DVC поймет, что необходимо воспроизвести одну из стадий конвейера. Поскольку изменение модели повлияет и на метрику, мы хотим воспроизвести всю цепочку. Любой этап конвейера DVC можно воспроизвести с помощью команды dvc repro:
dvc repro evaluate
И всё! Когда мы запускаем команду repro, DVC проверяет все зависимости всего конвейера, чтобы определить, что изменилось и какие команды нужно выполнить снова. Можно перемещаться между ветками и воспроизводить любой эксперимент с помощью одной лишь команды.
Кроме того, теперь проще простого сравнивать метрики. Если запустить dvc metrics show с ключом -T, будут отображаться метрики для всех тегов.
dvc metrics show -T
forest:
metrics/accuracy.json:
accuracy: 0.8098859315589354
sgd-pipeline:
metrics/accuracy.json:
accuracy: 0.6996197718631179
Это позволяет быстро определить, какой эксперимент в репозитории дал наилучший результат. Представим, что вы вернулись к проекту спустя полгода и забыли обо всех подробностях. Как и любому другому человеку, который хочет воспроизвести вашу работу, будет достаточно выполнить три шага:
- Запустить
git cloneилиgit checkout, чтобы получить программный код и dvc-файлы. - Получить данные обучения с помощью
dvc checkout. - Воспроизведите рабочий процесс с помощью команды
dvc repro evaluate.
Заключение
Поздравляем с прохождением туториала!
Итак, мы провели несколько экспериментов, обеспечили безопасное создание версий, резервное копирование данных и моделей. Более того, мы можем быстро воспроизвести каждый эксперимент, выполнив одну команду dvc repro.
Поначалу может показаться несколько сложным запускать в нужные моменты все команды DVC и Git. Положение облегчат хуки Git – при запуске определенных команд Git автоматически выполнятся команды DVC. К тому же DVC имеет Python API, то есть можно настроить необходимую автоматизацию на уровне кода.
Хотя это руководство представляет собой достаточно подробный обзор возможностей DVC, невозможно охватить всё в одной публикации. Для дальнейшего ознакомления с DVC мы рекомендуем обратиться к официальному руководству пользователя, справочнику команд и интерактивному учебнику.