Финал НТО БД*МО 2022
обычный участник олимпиадИтак, финал бд*мо уже почти завершился (отправлять сабмиты нельзя, привата пока нет).
Начну с некоторой предысторией этого профиля. Прошлый год отличился тем, что мало того, что организаторы дали довольно.... спорную по качеству задачу, так еще и тестирующая система не работало бОльшую часть финала. Было 3 дня на решение задачи, при этом тестирующая система работала только в первый день, далее она упала из-за нагрузок и сабмиты проходили лишь у 5-10% команд. Организаторы проигнорировали просьбы участников хоть что-нибудь сделать и в конце даже открыто заявили, что перетестирования посылок не будет. Таким образом зарешал рандом и те, кто успели заслать хоть что нибудь в первый день. К слову, чтобы победить достаточно было заменить линрег в бейзе на катбуст и поставить удачный сид (так победил я) или просто добавить фичей через функцию, которая уже была в бейзлайне (так победили другие мои друзья),
Теперь перейду к финалу этого года, с новыми организаторами (из ИТМО). Люди заподозрили неладное еще на 1м отборочном этапе. В то время как на других профилях проходным было 30-100/200 баллов, на бд*мо он оказался 185/200. Очень много людей, которые думали что он будет низким и поэтому даже не пытались решать первый тур, просто пролетели.
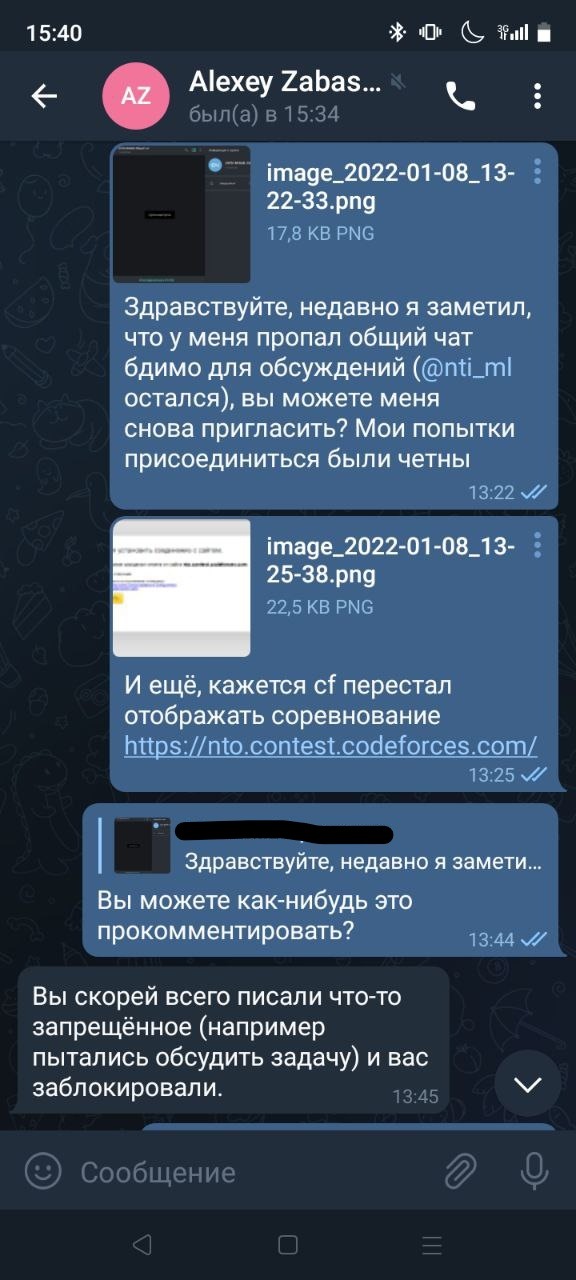
Первый этап прошёл, люди стали добавляться в чат. Постепенно появлялись различные новости насчет финала, иногда у людей возникали вопросы и они их задавали и т.д. Всё как на обычном НТО. Вскоре пришла новость - около трети участников 2го этапа дисквалифицированы "за списывание". У всех уже появились вопросы, люди стали спрашивать в чате как так-то, за что и т.д. Людей, которые задают вопросы, стали просто банить в чате - так было забанено несколько моих друзей и знакомых, опытных ml-щиков, у которых даже не было смысла списывать. Организаторы добавили, что аппеляция возможна и на неё можно пойти, однако почему-то только одного человека восстановили. После этого я решил поспрашивать людей, за что их банили. Все они отвечали (писали, перекидывали сообщения организаторов или даже кидали скрины), что им даже не предъявили доказательств. Самый частый ответ организаторов на просьбу пересмотреть решение или узнать причину дисквалификации был "вы сами знаете за что". Они тупо ничего не сделали. Многие снова стали возмущаться в общем чате и многие были забанены.
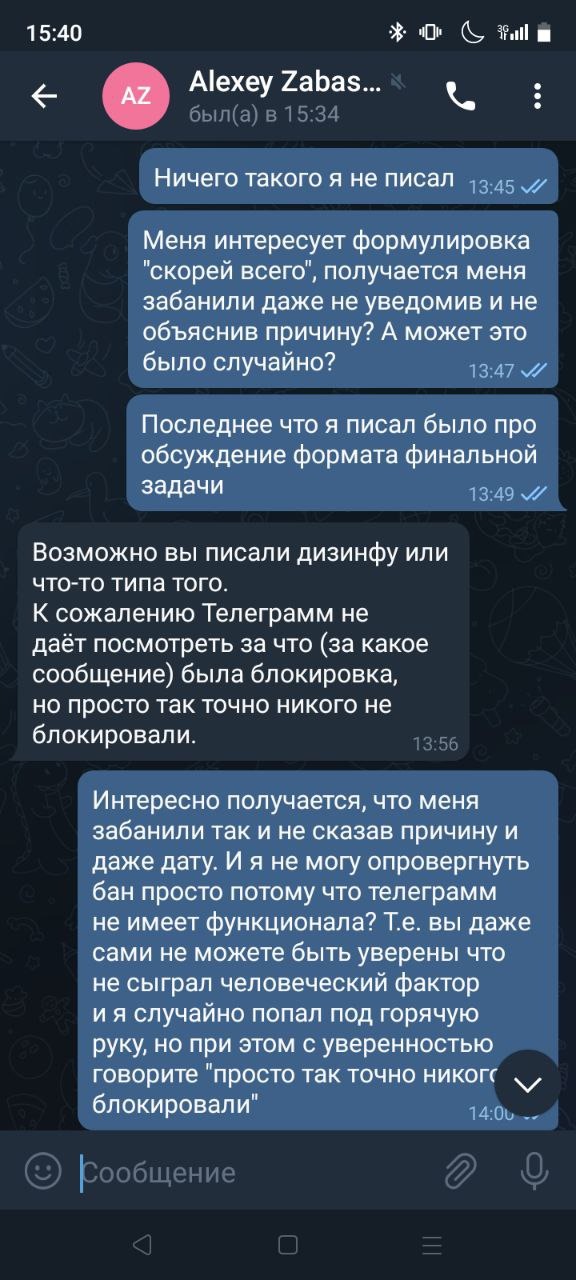
Второй этап прошёл, а репрессии в чате продолжались - еще пара моих знакомых улетели в бан без объяснения причин. При этом на попытку узнать причину бана организаторы отвечали "вы нарушили правила соревнования, мы были вынуждены забанить вас в чате олимпиады" без ссылок на соответствующие пункты официальных документов, регламентирующих данную часть. Самостоятельно мы не смогли найти ни слова про беспричинные баны.
Все уже понимали что ничего хорошего на финале не будет. Так и получилось. Накануне предметного тура организаторы выложили инструкцию как его писать - краткая на 6 страниц и полная на 18 страниц. Организаторы требовали: общение с проктором через zoom, транляцию в zoom и запись экрана через obs и еще несколько системных настроек непонятно для чего. В связи с этим были довольно неприятные требования к ноутбукам, из-за чего немало людей не смогли бы нормально порешать индивидуальный тур. Поэтому я решил сделать в общем чате опрос - сможешь/будешь писать предметный тур (часть людей еще просто не хотели писать, мне было интересно собрать статистику) - в бан я улетел мгновенно. Мои друзья, еще живые в чате стали возмущаться в чате за что меня забанили, но за такие вопросы в бан улетели и они тоже.
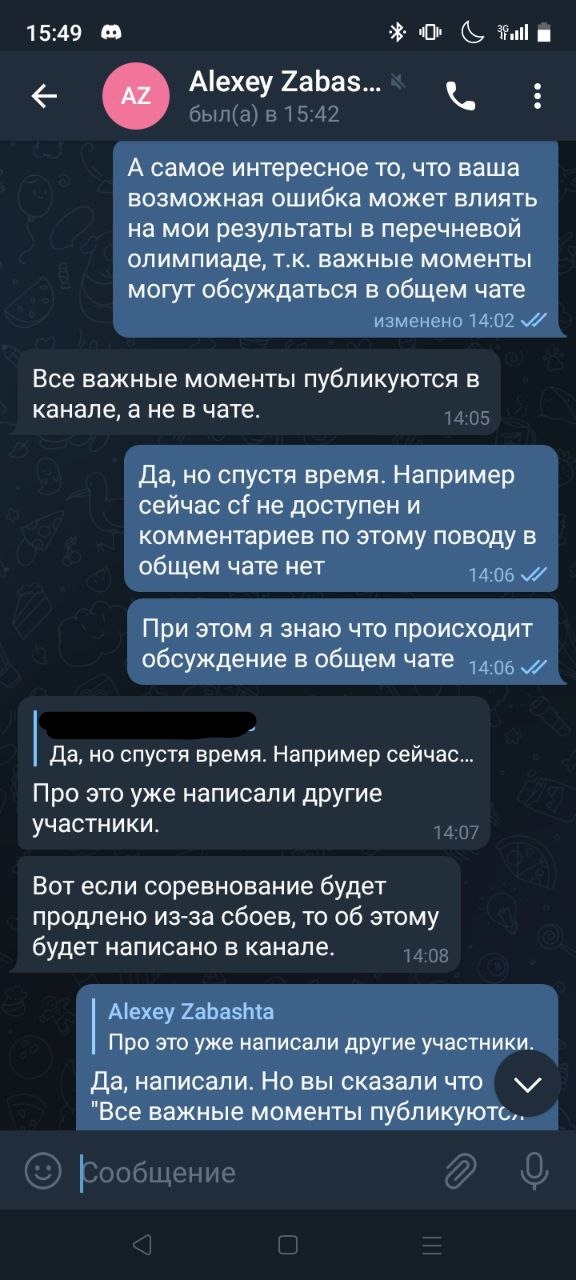
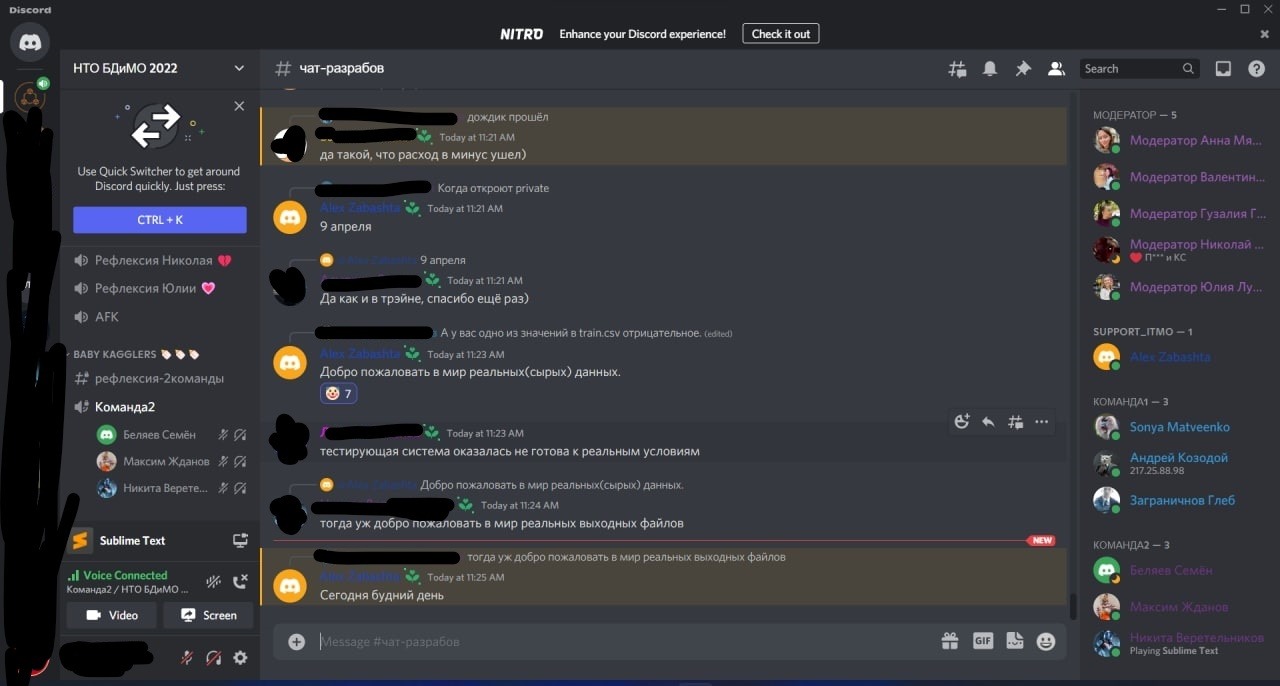
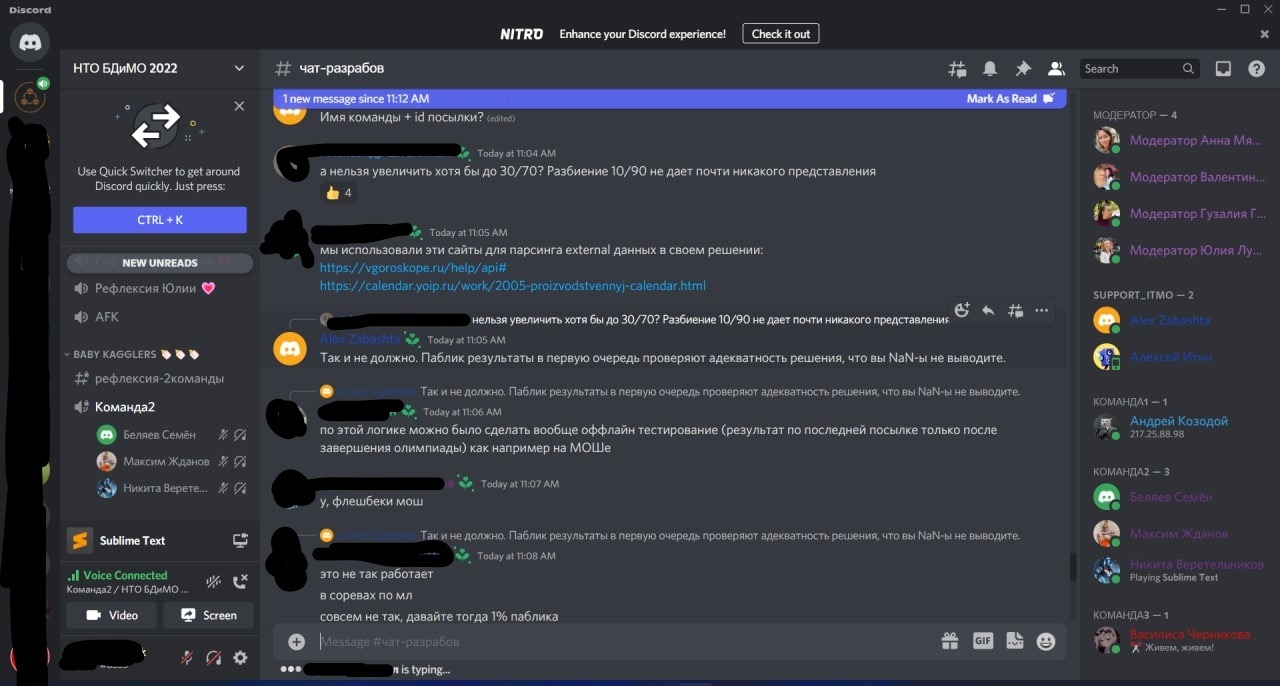
Наступил финал. чата финалистов создано не было (в отличие от других профилей НТО) почему-то и бОльшая часть финалистов лишились средства общения с организаторами (хорошо хоть оставался чат в дискорде). Наступила командная задача - предсказание временных рядов. Учебная выборка 30к, тестовая 4к (это очень мало даже для такой задачи). А теперь самый сок - ground truth бейз (90+%) и ... внимание.... 10 % паблик выборки. Это очень мало для любых соревнований. Ну и также дали 50 попыток на всё соревнование. В связи с этим уже ко второму дню финала стало очевидно, что паблик лидерборд это абсолютный рандом. Из-за этого мы, участники, стали просить организаторов хотя бы немного расширить паблик выборку или хотя бы объяснить почему они решили взять только 10%. И знаете как отрегировали организаторы? Они почистили чат, поставили слоумод на 5 минут и забанили несколько человек. Круто. Вскоре подключились модераторы и сами мягко говоря удивились от происходящего.
Вскоре выяснилось что вся эта чистка произошла по решению одного конкретного организатора (спойлер - именно этот конкретный человек и банил почти всех участников). Вскоре к нашему диалогу подсоединился представитель проектного офиса НТО и нам сказали "нас услышали". Как оказались, нас просто проигнорировали. Организаторам было абсолютно п**ер (уж простите за грубость) на участников. Они ответили якобы это даже "упрощенные условия, на практике только 4-7% данных используются в паблик выборке". На этом моменте я, имея чуть больше полутора лет опыта, более 10 соревнований международного и всероссийского масштаба, другие участники, имея 3/4 и более лет работы, несколько десятков соревнований и побед всероссийского и международного уровня, просто были в шоке от подобной безграмотности и наглости организаторов. Это либо просто отговорка для тупых, либо сам организатор относится к данной категории людей. Некоторые даже стали жаловаться представителю НТО, что нам не просто за участников не считают, что организаторы считают нас за школьников начальных классов, которые впервые в жизни загуглили fit-predict и еще ничего не знают и не понимают. На следующее утро оказалось, что все наши просьбы были тупо проигнорированы. Паблик выборку не изменили, попыток не добавили. Короче ждем жёсткого шейкапа. Далее были споры по поводу релевантности формулы итогового баллы. Процитирую некоторые комментарии по этому поводу:
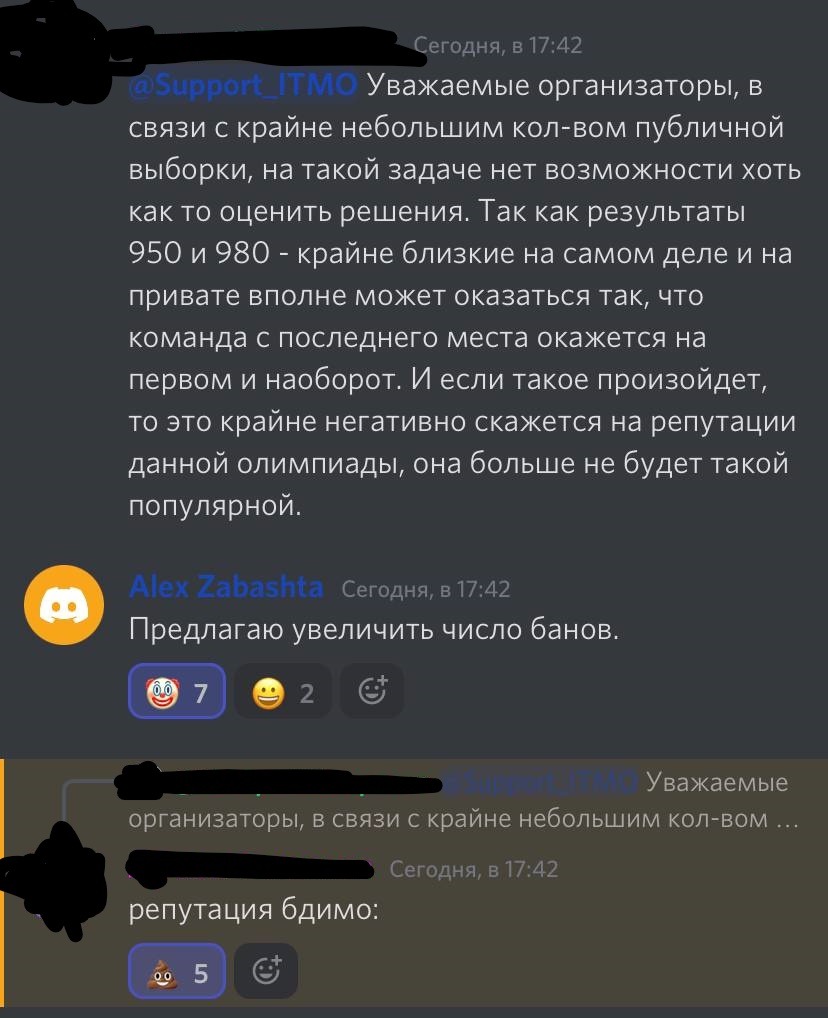
"Уважаемые организаторы, я хотел бы обратиться к вам поводу следующей метрики, которая указана в регламенте соревнования. У нее есть одна проблема, она не подходит для данной задачи. Вы выбрали задачу таким образом, что у всех участников в первой половине лидерборда примерно одинаковый скор. С точки зрения математики это действительно так, но с точки зрения ML - нет. Между 0.980 и 0.985 есть огромная разница. При текущей метрики участник из команды на 9 месте обгоняет участника команды на первом в случае решения на одну задачу больше индивидуальном этапе. Мое предложение: учитывать место команды при подсчете итогового балла, как, например, было в профиле ИИ"
"Чтобы улучшить счет с 0.940 до 0.980 достаточно добавить одну строку в код, а чтобы улучшить еще с 0.980 до 0.985 надо применить множество сложных вещей, метрика это не учитывает. Для этого придумали такие метрики, которые учитывают еще и место команды"
"0.981 и 0.985 это огромная разница в скоре, но с точки зрения формулы, которая не учитывает не то что саму задачу, а хотя бы место на лб, у обеих этих комант почти одинаковый балл будет за командную задачу"
"Забавно, что в профиле ИИ организаторы тоже долго не хотели менять метрику, на все расчеты в лоб говорили, что все это бред, но потом все таки вспомнили, что можно и нужно идти людям на встречу и поменяли метрику, и жизнь стала проще и участники уже такими злыми и навязчивыми казаться перестали и получился по итогу относительно хороший профиль. Такая же ситуация и здесь, из причин оставить старую метрику только одна - лень ее менять, здесь не помогут не оскорбления, не угрозы, достаточно просто быть человеком"
Это произошло из-за того, что метрика не учитывает место команды. Из-за чего топ-9 команд из 23 имеют почти одинаковые результаты. Из-за чего даже 20 баллов за индивидуальный тур могут подвинуть человека на 20-25 мест (9 команд это примерно столько человек), и получается можно было решить командный тур на низкий балл буквально за полчаса, но решить предметный тур хорошо и победить (а олимпиада как бы командная, не индивидуальная).
И знаете что сделали организаторы? Они даже не стали пытаться понять суть дискуссии и просто проигнорировали все просьбы, оправдывая свою метрику словами "ну итоговый же вес командного тура 70%. Значит командный балл важен"
Резюмирую: бд*мо одна из худших, если не худшая, олимпиада рсош в 2021/2022 году, основные причины:
1) беспричинные баны везде со стороны организаторов
2) беспричинная дисквалификация без объяснения причин
3) ужасная паблик выборка (400 строк)
4) малое число попыток
5) нежелание или неспособность слушать участников и исправлять проблемы
6) крайне плохая для соревнования задача (30000 записей на временные ряды, причем никаких фичей - только время и значение - всё. Если кто не понимает почему это плохо - напишите, я распишу)
Прикладываю некоторые скрины с особенно "веселыми" ответами организаторов