Fake User Agent Python

🛑 ALL INFORMATION CLICK HERE 👈🏻👈🏻👈🏻
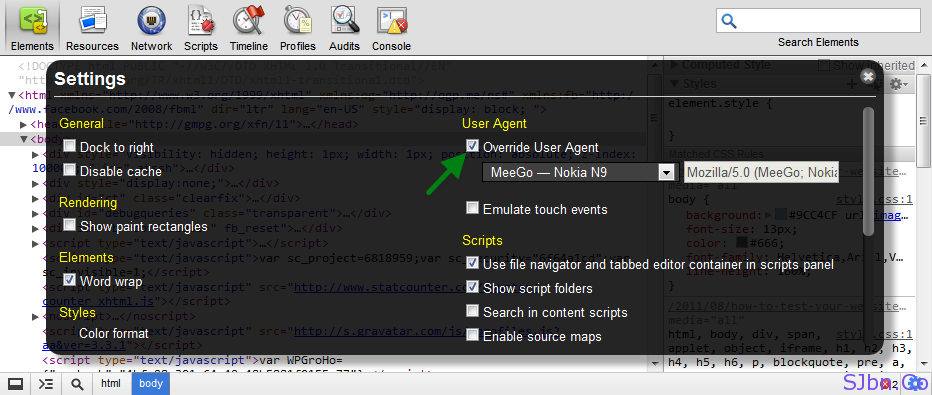
Fake User Agent Python
How to fake and rotate User Agents using Python 3
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware' : None ,
'scrapy_useragents.downloadermiddlewares.useragents.UserAgentsMiddleware' : 500 ,
}
USER_AGENTS = [
( 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.110 '
'Safari/537.36' ), # chrome
( 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 '
'Safari/537.36' ), # chrome
( 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:55.0) '
'Gecko/20100101 '
'Firefox/55.0' ), # firefox
( 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.91 '
'Safari/537.36' ), # chrome
( 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/62.0.3202.89 '
'Safari/537.36' ), # chrome
( 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.108 '
'Safari/537.36' ), # chrome
]
Please DO NOT contact us for any help with our Tutorials and Code using this form or by calling us, instead please add a comment to the bottom of the tutorial page for help
Turn the Internet into meaningful, structured and usable data
To rotate user agents in Python here is what you need to do
There are different methods to do it depending on the level of blocking you encounter.
A user agent is a string that a browser or application sends to each website you visit. A typical user agent string contains details like – the application type, operating system, software vendor, or software version of the requesting software user agent. Web servers use this data to assess the capabilities of your computer, optimizing a page’s performance and display. User-Agents are sent as a request header called “User-Agent”.
User-Agent: Mozilla/ () ()
Below is the User-Agent string for Chrome 83 on Mac Os 10.15
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36
Before we look into rotating user agents, let’s see how to fake or spoof a user agent in a request.
Most websites block requests that come in without a valid browser as a User-Agent. For example here are the User-Agent and other headers sent for a simple python request by default while making a request.
Ignore the X-Amzn-Trace-Id as it is not sent by Python Requests, instead generated by Amazon Load Balancer used by HTTPBin.
Any website could tell that this came from Python Requests, and may already have measures in place to block such user agents . User-agent spoofing is when you replace the user agent string your browser sends as an HTTP header with another character string. Major browsers have extensions that allow users to change their User-agent.
We can fake the user agent by changing the User-Agent header of the request and bypass such User-Agent based blocking scripts used by websites.
To change the User-Agent using Python Requests, we can pass a dict with a key ‘User-Agent’ with the value as the User-Agent string of a real browser,
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36
As before lets ignore the headers that start with X- as they are generated by Amazon Load Balancer used by HTTPBin, and not from what we sent to the server
But, websites that use more sophisticated anti-scraping tools can tell this request did not come from Chrome.
Although we had set a user agent, the other headers that we sent are different from what the real chrome browser would have sent.
Here is what real Chrome would have sent
It is missing these headers chrome would sent when downloading an HTML Page or has the wrong values for it
Anti Scraping Tools can easily detect this request as a bot a so just sending a User-Agent wouldn’t be good enough to get past the latest anti-scraping tools and services.
Let’s add these missing headers and make the request look like it came from a real chrome browser
Now, this request looks more like it came from Chrome 83, and should get you past most anti scraping tools – if you are not flooding the website with requests.
If you are making a large number of requests for web scraping a website, it is a good idea to randomize. You can make each request you send look random, by changing the exit IP address of the request using rotating proxies and sending a different set of HTTP headers to make it look like the request is coming from different computers from different browsers
If you are just rotating user agents. The process is very simple.
To rotate user agents in Scrapy, you need an additional middleware. There are a few Scrapy middlewares that let you rotate user agents like:
Our example is based on Scrapy-UserAgents.
Add in settings file of Scrapy add the following lines
Most of the techniques above just rotates the User-Agent header, but we already saw that it is easier for bot detection tools to block you when you are not sending the other correct headers for the user agent you are using.
To get better results and less blocking, we should rotate a full set of headers associated with each User-Agent we use. We can prepare a list like that by taking a few browsers and going to https://httpbin.org/headers and copy the set headers used by each User-Agent. ( Remember to remove the headers that start with X- in HTTPBin )
Browsers may behave differently to different websites based on the features and compression methods each website supports. A better way is
In order to make your requests from web scrapers look as if they came from a real browser:
Having said that, let’s get to the final piece of code
You cannot see the order in which the requests were sent in HTTPBin, as it orders them alphabetically.
There you go! We just made these requests look like they came from real browsers.
Rotating user agents can help you from getting blocked by websites that use intermediate levels of bot detection, but advanced anti-scraping services has a large array of tools and data at their disposal and can see past your user agents and IP address.
Turn the Internet into meaningful, structured and usable data
Anti scraping tools lead to scrapers performing web scraping blocked. We provided web scraping best practices to bypass anti scraping
When scraping many pages from a website, using the same IP addresses will lead to getting blocked. A way to avoid this is by rotating IP addresses that can prevent your scrapers from being disrupted.…
Here are the high-level steps involved in this process and we will go through each of these in detail - Building scrapers, Running web scrapers at scale, Getting past anti-scraping techniques, Data Validation and Quality…
There is a python lib called “fake-useragent” which helps getting a list of common UA.
Great find. We had used fake user agent before, but at times we feel like the user agent lists are outdated.
I have to import “urllib.request” instead of “requests”, otherwise it does not work.
agreed, same for me. I think that was a typo.
requests is different package, it should be installed separately, with “pip install requests”. But urllib.request is a system library always included in your Python installation
requests use urllib3 packages, you need install requests with pip install.
Hi there, thanks for the great tutorials!
Just wondering; if I’m randomly rotating both ips and user agents is there a danger in trying to visit the same URL or website multiple times from the same ip address but with a different user agent and that looking suspicious?
Nick,
There is no definite answer to these things – they all vary from site to site and time to time.
There is a library whose name is shadow-useragent wich provides updated User Agents per use of the commmunity : no more outdated UserAgent! https://github.com/lobstrio/shadow-useragent
There is a website front to a review database which to access with Python will require both faking a User Agent and a supplying a login session to access certain data. Won’t this mean that if I rotate user agents and IP addresses under the same login session it will essentially tell the database I am scraping? Is there any way around this?
………………..
ordered_headers_list = []
for headers in headers_list:
h = OrderedDict()
for header,value in headers.items():
h[header]=value
ordered_headers_list.append(h)
for i in range(1,4):
#Pick a random browser headers
headers = random.choice(headers_list)
#Create a request session
r = requests.Session()
r.headers = headers
# Download the page using requests
print(“Downloading %s”%url)
r = r.get(url, headers=i,headers[‘User-Agent’])
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if “To discuss automated access to Amazon data please contact” in r.text:
print(“Page %s was blocked by Amazon. Please try using better proxies\n”%url)
else:
print(“Page %s must have been blocked by Amazon as the status code was %d”%(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
# product_data = []
with open(“asin.txt”,’r’) as urllist, open(‘hasil-GRAB.txt’,’w’) as outfile:
for url in urllist.read().splitlines():
data = scrape(url)
if data:
json.dump(data,outfile)
outfile.write(“\n”)
# sleep(5)
can anyone help me to combine this random user agent with the amazon.py script that is in the amazon product scrapping tutorial in this tutorial —-> https://www.scrapehero.com/tutorial-how-to-scrape-amazon-product-details-using-python-and-selectorlib/
Is there any library like fakeuseragent that will give you list of headers in correct order including user agent to avoid manual spoofing like in the example code.
@melmefolti We haven’t found anything so far. A lot of effort would be needed to check each Browser Version, Operating System combination and keep these values updated.
Very useful article with that single component clearly missing. I have come across pycurl and uncurl packages for python which return the same thing as the website, but in alphabetical order. Perhaps the only option is the create a quick little scraper for the cURL website, to then feed the main scraper of whatever other website you’re looking at
You can try curl with the -I option
ie curl -I https://www.example.com and see if that helps
why exactly do we need to open the network tab?
‘Open an incognito or a private tab in a browser, go to the Network tab of each browsers developer tools, and visit the link you are trying to scrape directly in the browser.
Copy the curl command to that request –
curl ‘https://www.amazon.com/’ -H ‘User-Agent:…’
does the navigator have something to do with the curl command?
The curl command is copied from that window – so it is needed.
In the line “Accept-Encoding”: “gzip, deflate,br”,
the headers having Br is not working it is printing gibberish when i try to use beautiful soup with that request .
You can safely remove the br and it will still work
Your email address will not be published. Required fields are marked *
Legal Disclaimer: ScrapeHero is an equal opportunity data service provider, a conduit, just like
an ISP. We just gather data for our customers responsibly and sensibly. We do not store or resell data.
We only provide the technologies and data pipes to scrape publicly available data. The mention of any
company names, trademarks or data sets on our site does not imply we can or will scrape them. They are
listed only as an illustration of the types of requests we get. Any code provided in our tutorials is
for learning only, we are not responsible for how it is used.
web scraping - How to use Python requests to fake ... - Stack Overflow
How to fake and rotate User Agents using Python 3
GitHub - hellysmile/ fake - useragent : up to date simple useragent faker...
Python Examples of fake _ useragent . UserAgent
fake user agent python library Code Example
hellysmile
/
fake-useragent
hellysmile
Disable email notifications.
from fake_useragent import UserAgent
ua = UserAgent ()
ua . ie
# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua . msie
# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
ua [ 'Internet Explorer' ]
# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
ua . opera
# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
ua . chrome
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua . google
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua [ 'google chrome' ]
# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua . firefox
# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua . ff
# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua . safari
# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25
# and the best one, random via real world browser usage statistic
ua . random
from fake_useragent import UserAgent
ua = UserAgent ()
ua . update ()
from fake_useragent import UserAgent
ua = UserAgent ( cache = False )
from fake_useragent import UserAgent
ua = UserAgent ( use_cache_server = False )
from fake_useragent import UserAgent
ua = UserAgent ()
# Traceback (most recent call last):
# ...
# fake_useragent.errors.FakeUserAgentError
# You can catch it via
from fake_useragent import FakeUserAgentError
try :
ua = UserAgent ()
except FakeUserAgentError :
pass
from fake_useragent import UserAgent
ua = UserAgent ()
ua . best_browser
# Traceback (most recent call last):
# ...
# fake_useragent.errors.FakeUserAgentError
import fake_useragent
ua = fake_useragent . UserAgent ( fallback = 'Your favorite Browser' )
# in case if something went wrong, one more time it is REALLY!!! rare case
ua . random == 'Your favorite Browser'
import fake_useragent
# I am STRONGLY!!! recommend to use version suffix
location = '/home/user/fake_useragent%s.json' % fake_useragent . VERSION
ua = fake_useragent . UserAgent ( path = location )
ua . random
import fake_useragent
ua = fake_useragent . UserAgent ( safe_attrs = ( '__injections__' ,))
import fake_useragent
print ( fake_useragent . VERSION )
pypi.python.org/pypi/fake-useragent
© 2021 GitHub, Inc.
Terms
Privacy
Security
Status
Docs
Contact GitHub
Pricing
API
Training
Blog
About
fake-useragent store collected data at your os temp dir, like /tmp
If You want to update saved database just:
If You don't want cache database or no writable file system:
Sometimes, useragentstring.com or w3schools.com changes their html, or down, in such case
fake-useragent uses heroku fallback
If You don't want to use hosted cache server (version 0.1.5 added)
In very rare case, if hosted cache server and sources will be
unavailable fake-useragent wont be able to download data: (version 0.1.3 added)
If You will try to get unknown browser: (version 0.1.3 changed)
You can completely disable ANY annoying exception with adding fallback : (version 0.1.4 added)
Want to control location of data file? (version 0.1.4 added)
If you need to safe some attributes from overriding them in UserAgent by __getattr__ method
use safe_attrs you can pass there attributes names.
At least this will prevent you from raising FakeUserAgentError when attribute not found.
For example, when using fake_useragent with injections you need to:
Please, do not use if you don't understand why you need this.
This is magic for rarely extreme case.
Make sure that You using latest version!!!
Check version via python console: (version 0.1.4 added)
And You are always welcome to post issues
Please do not forget mention version that You are using
up to date simple useragent faker with real world database
Up to date simple useragent faker with real world database
Britney Young Interracial Xxx
Motherless Young Porno Models Pics
Cute Young Hot Sexy
Young First Time Anal Full Hd 1080
3d Incest Comics Sons



















 f_auto/p/629325a2-9b5f-11e6-bb5a-00163ec9f5fa/3491759788/user-agent-switcher-screenshot.png" width="550" alt="Fake User Agent Python" title="Fake User Agent Python">
f_auto/p/629325a2-9b5f-11e6-bb5a-00163ec9f5fa/3491759788/user-agent-switcher-screenshot.png" width="550" alt="Fake User Agent Python" title="Fake User Agent Python">