Фаервол: iptables, модуль ядра netfilter и eBPF (XDP)
Исходный код использованный в статье:
git clone https://github.com/seantywork/linuxyz.git -b 2503-01
Грустная правда жизни: просто отключить фаервол на серверах не получится. Это настоящая головная боль, особенно когда вы настраиваете или разворачиваете проект, в котором задействовано несколько хостов с Linux (например, Kubernetes). Как только вы разберётесь с кучей портов, которые нужно открыть, и настроите фаервол VPC (если вы в облаке) или правила на маршрутизаторе (если на физической инфраструктуре), откуда-то из-за угла прилетает подзатыльник от коварного SELinux — особенно если вам, как и мне, «посчастливилось» работать преимущественно с дистрибутивами на базе Red Hat.
Но, как и во многих других вещах, копнуть глубже в то, как работает фаервол — гораздо интереснее, чем просто его настроить.
Независимо от того, какой инструмент вы используете для управления фаерволом — будь то ufw на Ubuntu или firewall-cmd на RHEL — в итоге все они делают одно и то же: настраивают правила для iptables (если вы работаете в Linux-среде). А дальше уже правила iptables проверяет модуль ядра netfilter, как только пакет входит в систему или выходит из процесса. Судьба пакета решается именно здесь: netfilter определяет, подходит ли он под какое-либо правило и можно ли пропустить его дальше. Этот модуль также может изменить пакет, если правило это предусматривает — но чтобы не усложнять, в этой статье мы в такие детали углубляться не будем.
Кроме того, если вы работаете на Linux, можно воспользоваться мощью eBPF, а точнее — XDP (eXpress Data Path), чтобы принимать решение по пакету ещё быстрее. XDP начинает работать буквально в момент, когда пакет «входит в интерфейс». Я специально взял это в кавычки, потому что точный момент зависит от режима работы вашей XDP-программы, но в контексте этой статьи речь идёт о native-режиме, где драйвер сетевого интерфейса поддерживает запуск XDP прямо в ядре.
Главное преимущество XDP не только в том, что он работает быстрее, но и в том, что правила фильтрации можно эффективнее отслеживать и обновлять из пользовательского пространства. Правда, за производительность приходится платить: гибкости у XDP поменьше — он почти никак не помогает с исходящими пакетами (хотя пересылка между интерфейсами всё ещё возможна).
Ниже — краткая схема, показывающая взаимосвязь между инструментами управления фаерволом, iptables, netfilter и XDP.
process (user, program...)
| |
| |
| |
V |
------------------------|---------
| firewall | |
| managment | |
| tool | |
------------------------|---------
| |
| |
| |
V |
------------------------|---------
| iptables | |
| command | |
------------------------|---------
| |
| |
------------------------|-------- below is kernel
| |
| |
V |
------------------------|---------
| netfilter | |
------------------------|---------
|
V
-----------------------------------
| eBPF(XDP) |
-----------------------------------
(я очень надеюсь, что в мобильной версии это будет выглядеть смотрибельно, но не очень в это верю)
Более подробная схема ниже. Если вы не понимаете большую часть — не переживайте, я и сам тоже не всё понимаю.
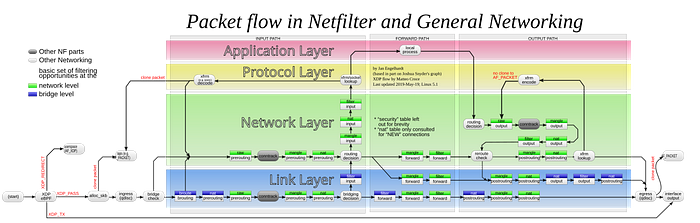
Вступление
Ну что ж, теперь начнём по порядку разбираться в том, как одна и та же функциональность может быть реализована в системе тремя разными способами.
Для начала настроим тестовое окружение. Выполните команды ниже — они имитируют ситуацию, когда два сетевых интерфейса соединены через обычный LAN-кабель:
sudo ip netns add vnet0 sudo ip link add dev veth01 type veth peer name veth02 netns vnet0 sudo ip link set up veth01 sudo ip netns exec vnet0 ip link set up veth02 sudo ip addr add 10.168.0.1/24 dev veth01 sudo ip netns exec vnet0 ip addr add 10.168.0.2/24 dev veth02
Это эквивалентно следующей топологии:
---------------------------
| |
| HOST |
| |
| veth01 |
| (10.168.0.1/24) |
-----------|---------------
|
|
|
|
-----------|-----------------
| | NET NAMESPACE|
| | vnet0 |
| | |
| veth02 |
| (10.168.0.2/24) |
| |
-----------------------------
Будем считать, что veth02 — это интерфейс, смотрящий наружу, а NET NAMESPACE vnet0 — это наш условный хост, который мы собираемся защищать с помощью фаервола.
Почему не просто на хосте? Да потому что не хочется портить уже существующие правила iptables на основной машине.
Пока внутри vnet0 нет никаких правил, вы вполне можете протестировать соединение следующими командами:
# terminal 1 sudo ip netns exec vnet0 nc -l 11.168.0.2 9999 # terminal 2 nc 11.168.0.2 9999
Теперь введите что-нибудь и нажмите Enter во втором терминале — сообщение должно появиться в первом. Значит соединение установлено.
Теперь давайте настроим с помощью команды ufw простой фаервол, который будет блокировать TCP-соединения на порт 9999.
Не переживайте — эта команда не испортит ваши ценные уже настроенные правила. Пространства имён сети в Linux (netns) работают как песочницы: всё, что вы делаете внутри, изолировано от основной системы.
Эта изоляция особенно хорошо видна, если ufw у вас вообще не активирован на основной системе.
# проверим статус ufw на хосте sudo ufw status Status: inactive # теперь тоже самое внутри пространства имён sudo ip netns exec vnet0 ufw status Status: inactive # а теперь включим ufw внутри namespace sudo ip netns exec vnet0 ufw enable Firewall is active and enabled on system startup # снова проверим статус внутри sudo ip netns exec vnet0 ufw status Status: active # снова глянем на хосте (должно быть неактивно) sudo ufw status Status: inactive
Вот так с помощью netns можно изолировать настройки фаервола, не боясь задеть конфигурации основной системы.
iptables
А вот теперь давайте посмотрим, какой ужас скрывает от вас ufw — ведь под капотом он на самом деле просто управляет iptables. Выполните следующую команду:
sudo ip netns exec vnet0 iptables -L
Если снова запустить nc, как вы делали раньше, то теперь соединение уже не устанавливается — фаервол работает.
Теперь давайте разрешим TCP-соединения на порт 9999 напрямую через ufw:
sudo ip netns exec vnet0 ufw allow proto tcp from any to any port 9999
Если вы не поленитесь и сравните правила iptables до и после выполнения этой команды, вы увидите, что ufw добавил для вас примерно такую строку:
# diff first.txt second.txt # both outputs were captured using iptables -L > *.txt before and after the ufw ACCEPT tcp -- anywhere anywhere tcp dpt:9999
Сейчас мы не будем глубоко нырять в дебри цепочек и всех правил — я и сам не настолько силён в этом. Вместо этого давайте просто немного «поиграем» с этой конкретной строкой, уже напрямую через iptables.
Для начала выключим ufw в нашем namespace:
sudo ip netns exec vnet0 ufw disable
Теперь nc снова сможет установить соединение. То есть логика простая: с включённым ufw хост по умолчанию отбрасывает все непрошенные пакеты, а без него — разрешает.
Теперь мы вручную добавим одно правило в iptables, чтобы блокировать трафик на порту 9999. Помните, у нас «открытый» хост (vnet0), и мы хотим на нём руками отрубить доступ.
sudo ip netns exec vnet0 iptables -A INPUT -p tcp --dport 9999 -j DROP
Проверьте, работает ли nc. Не должно — соединение должно блокироваться.
Если всё сработало, можно очистить правила, и двигаться дальше:
sudo ip netns exec vnet0 iptables -F
Модуль ядра Netfilter
Теперь давайте посмотрим вглубь — буквально в код, который оживляет эту странную строчку:
INPUT -p tcp --dport 9999 -j DROP
Для этого нам понадобятся зависимости, ведь мы собираемся скомпилировать и загрузить модуль ядра Linux.
sudo apt-get update sudo apt-get install build-essential make linux-headers-$(uname -r)
Эти команды установят компилятор, систему сборки Make и заголовки ядра на вашу машину.
В клонированном репозитории linuxxyz, перейдите в нужную папку и соберите миниатюрный netfilter-модуль:
cd firewall/netfilter make # ниже приведён успешный вывод сборки make -C /lib/modules/6.8.0-53-generic/build M=/home/seantywork/hack/linux/linuxyz/firewall/netfilter modules make[1]: Entering directory '/usr/src/linux-headers-6.8.0-53-generic' warning: the compiler differs from the one used to build the kernel The kernel was built by: x86_64-linux-gnu-gcc-13 (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 You are using: gcc-13 (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 CC [M] /home/seantywork/hack/linux/linuxyz/firewall/netfilter/mynetfilter.o MODPOST /home/seantywork/hack/linux/linuxyz/firewall/netfilter/Module.symvers CC [M] /home/seantywork/hack/linux/linuxyz/firewall/netfilter/mynetfilter.mod.o LD [M] /home/seantywork/hack/linux/linuxyz/firewall/netfilter/mynetfilter.ko BTF [M] /home/seantywork/hack/linux/linuxyz/firewall/netfilter/mynetfilter.ko Skipping BTF generation for /home/seantywork/hack/linux/linuxyz/firewall/netfilter/mynetfilter.ko due to unavailability of vmlinux make[1]: Leaving directory '/usr/src/linux-headers-6.8.0-53-generic'
В этой директории нас дальше интересует файл mynetfilter.ko — именно его мы будем загружать в ядро.
Для этого используется специальная команда (только вы её пока не запускайте):
sudo insmod mynetfilter.ko
Перед выполнением, стоить внимательно посмотреть исходники и проанализировать, что же после выполнения будет выполняться. Я конечно проверял это у себя локально, и у меня работало, но гарантий что сработает у вас, и не положит систему дать не могу (хотя должно работать). Так что будьте внимательны.
Кроме того, одной команды insmod недостаточно. Сначала нужно узнать ID пространства имён vnet0. Для этого:
ip netns list
Если у вас нет запущенных контейнеров или вы только начали играться с netns, ID, скорее всего, будет 0. Но лучше всё-таки проверить.
После этого, модуль можно загружать с параметром vnet0id. Пример:
#terminal 1 sudo dmesg -wH #terminal 2 sudo insmod vnet0id=$YOUR_NAMESPACE_ID
Если всё прошло хорошо, в первом терминале вы увидите сообщения вроде:
[ 140.984494] mynetfilter: loading out-of-tree module taints kernel. [ 140.984504] mynetfilter: module verification failed: signature and/or required key missing - tainting kernel [ 140.985272] init mynetfilter: block port
Если теперь снова попробовать nc, соединение уже не установится — как и ожидалось.
Если вы оставили dmesg открытым, то увидите, что ядро само отбрасывает пакеты, как и должно быть.
Когда захотите всё откатить, просто выгрузите модуль:
sudo rmmod mynetfilter
eBPF
Чтобы дойти до этой части, нам понадобится ещё один набор зависимостей — на этот раз для компиляции, загрузки и управления eBPF-программой.
В теории, вы можете пропустить всю возню с руками, но лично я считаю, что по-настоящему разобраться можно только через практику.
К счастью, в директории firewall/ebpf-xdp уже есть готовый скрипт установки - setup.sh.
Он не такой уж и длинный, но всё как и в предыдущем разделе советую внимательно прочитать, что он делает, чтобы выработать полезную привычку — понимать, а не просто запускать.
В коде, с которым мы будем работать в этой части, стоит быть особенно внимательными — строк больше, структура посложнее, и если раньше вы не сталкивались с eBPF, то многое покажется странным.
Хорошая новость в том, что eBPF-программы обычно не могут повалить ядро, потому что встроенный верификатор ядра сам отбраковывает подозрительный код — например, при некорректной работе с указателями. А даже если что-то и пойдёт не так — максимум пострадает конкретный eBPF-экземпляр, не вся система.
Итак, если зависимости установлены, в каталоге firewall/ebpf-xdp можно просто собрать проект:
make
После сборки запускаем программу:
# terminal 1 sudo ip netns exec vnet0 ./user.out
Если всё сработало, вы увидите примерно такой вывод:
# terminal 1 … … … updating map: dropping packets with tcp dest port 9999 verdict retrieved: 0
Идея этой демонстрационной программы простая: пользовательский процесс может динамически изменять правила фильтрации трафика, не вызывая iptables и не загружая/выгружая модуль ядра. Всё меняется «на лету».
В eBPF-программе firewall/ebpf-xdp/prog/firewall.c определена вот такая структура:
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, __u16);
__type(value, __u16);
__uint(map_flags, BPF_F_NO_PREALLOC);
__uint(max_entries, 65536);
} port_verdict SEC(".maps");
Ключ — номер порта, значение — «вердикт»: 1 — разрешить, 0 — отбросить.
После загрузки eBPF-программы в интерфейс, пользовательский процесс может получить дескриптор этой map и обновлять её динамически. Пример — строки 87–136 в firewall/ebpf-xdp/user.c.
Некоторые параметры, как порт, интерфейс и имя eBPF-программы, для простоты захардкожены. Но вердикт вы можете менять прямо во время работы — без пересборки.
(Хотя, если только ради этого — проще использовать параметр модуля ядра Netfilter. Но сейчас не об этом.)
# terminal 1 (где запущен user.out) Enter 'r' to reverse rule, or 'q' to exit:
Теперь откройте ещё три терминала.
# terminal 2
sudo ip netns exec vnet0 nc -l 11.168.0.2 9998
# terminal 3 (соединение должно пройти)
nc 11.168.0.2 9998
# terminal 4 (тут чекаем трассировку)
sudo cat /sys/kernel/tracing/trace
nc-6441 [003] ..s2. 3920.799014: bpf_trace_printk: proto ip
nc-6441 [003] ..s2. 3920.799015: bpf_trace_printk: proto tcp: checking
nc-6441 [003] ..s2. 3920.799017: bpf_trace_printk: port verdict not stored, default pass for port: 9998
# теперь попробуем с портом 9999
# terminal 2
sudo ip netns exec vnet0 nc -l 11.168.0.2 9999
# terminal 3 (а вот теперь соединение не должно пройти)
nc 11.168.0.2 9999
# terminal 4
nc-6489 [006] ..s2. 3947.609558: bpf_trace_printk: proto ip
nc-6489 [006] ..s2. 3947.609560: bpf_trace_printk: proto tcp: checking
nc-6489 [006] ..s2. 3947.609564: bpf_trace_printk: port: 9999
: verdict: 0
<idle>-0 [006] ..s2. 3948.635676: bpf_trace_printk: proto ip
<idle>-0 [006] ..s2. 3948.635681: bpf_trace_printk: proto tcp: checking
<idle>-0 [006] ..s2. 3948.635688: bpf_trace_printk: port: 9999
: verdict: 0
# terminal 1, жмём 'r' чтобы поменять правило
Enter 'r' to reverse rule, or 'q' to exit: r
verdict retrieved: 1
# пробуем снова порт 9999
# terminal 2
sudo ip netns exec vnet0 nc -l 11.168.0.2 9999
# terminal 3 (а теперь соединение должно пройти)
nc 11.168.0.2 9999
# terminal 4
nc-6610 [005] ..s2. 3993.666684: bpf_trace_printk: proto ip
nc-6610 [005] ..s2. 3993.666685: bpf_trace_printk: proto tcp: checking
nc-6610 [005] ..s2. 3993.666687: bpf_trace_printk: port: 9999
: verdict: 1
<idle>-0 [005] ..s2. 3997.630073: bpf_trace_printk: proto ip
<idle>-0 [005] ..s2. 3997.630081: bpf_trace_printk: proto tcp: checking
<idle>-0 [005] ..s2. 3997.630085: bpf_trace_printk: port: 9999
: verdict: 1
Нажмите q — и eBPF-программа завершит работу и выгрузится.
Используя такой подход, можно не просто «играться», а писать высокопроизводительные сетевые приложения — именно так работает, например, Cilium, который активно применяет eBPF.
Завершение
Вот мы и рассмотрели три ключевых компонента фаервола в Linux: iptables, netfilter и eBPF. Каждый из них имеет свои сильные и слабые стороны, и все они продолжают развиваться.
Например, nftables — это формальный наследник iptables, который предлагает более современный API для взаимодействия с ядром. Хотя не всё в нём является прямой заменой старым механизмам.
Но самое главное — глубокое понимание и практика. Только так можно по-настоящему использовать возможности системы и создавать решения, которые действительно работают эффективно и стабильно.