Engineering the Semantic Layer: Why LLMs Need “Data Shape,” Not Just “Data Schema
Data&AI Insights📖 Источник: medium.com
Краткое содержание статьи
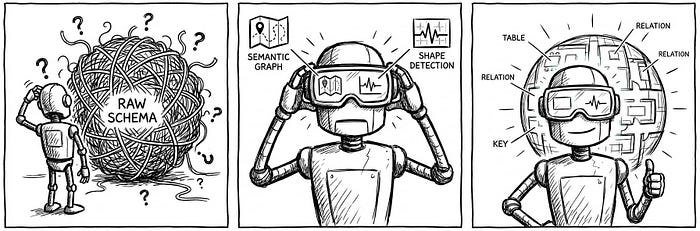
Статья Шреяша Шуклы, опубликованная 31 января 2026 года на платформе Medium в издании Towards Data Engineering, посвящена проблемам и решениям при создании семантического слоя для больших языковых моделей (LLM) в корпоративной аналитике. Автор аргументирует, что для повышения точности и предотвращения галлюцинаций LLM недостаточно иметь только схему данных (Data Schema), необходима также информация о «форме данных» (Data Shape) — статистических характеристиках и семантической логике. В статье подробно рассматриваются два ключевых компонента: Enterprise Semantic Graph и Statistical Shape Detection, которые вместе позволяют перейти от вероятностной генерации SQL-запросов к детерминированному их формированию.
Проблема «Экономики окна контекста» и ограничения Retrieval-Augmented Generation (RAG)
В современных LLM внимание — это ограниченный ресурс, и несмотря на расширение окон контекста, сохраняется проблема «Lost in the Middle» (потеря в середине). Исследование Стэнфордского университета [Lost in the Middle: How Language Models Use Long Contexts] показывает, что с ростом объема контекста способность модели точно извлекать конкретные ограничения ухудшается. В корпоративной аналитике это приводит к проблемам с точностью SQL-запросов.
Стандартный подход Retrieval-Augmented Generation (RAG) предполагает загрузку в запрос сотен DDL-операторов CREATE TABLE, что приводит к «Context Rot» — модель теряет фокус из-за избыточной информации о несущественных колонках и внешних ключах. Кроме того, возникает «Raw Schema Fallacy» — DDL описывает структуру данных, но не их содержимое. Например, колонка status может содержать разные значения: «Active/Inactive», «Open/Closed» или «1/0», но модель этого не знает и вынуждена «галлюцинировать» фильтры, что приводит к синтаксически корректным, но семантически неверным SQL-запросам.
По данным DataCamp [State of Data & AI Literacy 2024], отсутствие семантического контекста является основной причиной 20-40% ошибок в системах преобразования текста в SQL. Для решения проблемы автор предлагает отказаться от «Passive RAG» в пользу архитектуры «Just-in-Time», которая предоставляет контекст только по нужным таблицам.
Источник изображения: Google Gemini
Первый столп — Enterprise Semantic Graph (Корпоративный семантический граф)
Основой точности является Enterprise Semantic Graph. Статичные документации и вики быстро устаревают, поэтому источником истины становятся сами SQL ETL-скрипты, создающие таблицы. Парсинг этих скриптов позволяет формировать структурированную JSON-карту данных, переходя от плоского списка таблиц к семантическому слою. Databricks подчеркивает важность семантического слоя для ИИ, так как он «переводит сырые данные в бизнес-концепции» [The Importance of a Semantic Layer for AI].
Этот слой позволяет агенту понимать не только наличие таблиц, но и их происхождение (Data Lineage) — какие таблицы являются источниками, а какие потребителями данных. Ключевым элементом является Verified Logic — проверенная логика вычислений. Например, вместо угадывания формулы «Churn» агент читает simplified_sql_logic из метаданных, что гарантирует совпадение с официальной отчетностью.
Пример Knowledge Object:
💻 Код (json):
{
"table_name": "revenue_daily_snapshot",
"lineage": {
"upstream_tables": [
{ "table_name": "raw_bookings" },
{ "table_name": "currency_conversion_rates" }
]
},
"metrics": [
{
"name": "Net_Revenue_Retention",
"definition": "Revenue from existing customers excluding new sales.",
"simplified_sql_logic": "SUM(renewal_revenue) + SUM(upsell_revenue) - SUM(churn_revenue)",
"key_filters_and_conditions": ["is_active_contract = TRUE", "region != 'TEST'"]
}
]
}
Источник изображения: Google Gemini
Второй столп — Statistical Shape Detection (Статистическое определение формы данных)
Второй ключевой компонент — Statistical Shape Detection, который дополняет карту данных (Semantic Graph) информацией о «рельефе» — статистических характеристиках колонок. Для корректного формирования SQL-запросов агент должен знать статистическую сигнатуру данных.
Без этого возникает «Cardinality Trap» — например, запрос «Группировать клиентов по типу» может привести к ошибке, если колонка customer_type содержит уникальные идентификаторы (высокая кардинальность), а не категории (низкая кардинальность). В этом случае GROUP BY может вызвать сбой базы данных.
Gartner прогнозирует, что внедрение «активного метаданных» позволит сократить время доставки новых данных на 70% [Harnessing Active Metadata for Data Management].
Архитектура предусматривает предварительное вычисление «Shape Definition» для каждой критической колонки, которую агент использует «Just-in-Time» для проверки логики:
- DISTINCT VALUE COUNT — определяет, можно ли использовать колонку в
GROUP BY(низкая кардинальность) или она является идентификатором (высокая кардинальность). - FREQUENT VALUES OCCURRENCES — предотвращает «галлюцинации значений». Например, если пользователь запрашивает данные по «United States», агент проверяет, как именно страна записана в базе:
'USA','US'или'United States'. - QUANTILES и MIN/MAX VALUE — позволяют выявлять выбросы. Значение выручки за пределами 99-го перцентиля может быть отмечено как аномалия.
- ROW COUNT — служит для проверки «здоровья» данных. Если количество строк упало на 50% по сравнению с предыдущим днем, это сигнал о сбое в пайплайне.
IDC отмечает, что организации с развитой системой управления метаданными достигают в 3 раза лучших бизнес-результатов [IDC Snapshot: Data Intelligence Maturity Drives Three Times Better Business Outcomes].
Источник изображения: Google Gemini
Итог — переход от вероятностной генерации к детерминированной сборке SQL
Объединение Enterprise Semantic Graph и Statistical Shape Detection позволяет перейти от вероятностного угадывания SQL-запросов к детерминированной их сборке. В стандартном LLM-подходе модель генерирует запрос на основе шаблонов, изученных во время обучения, что приводит к ошибкам. В предложенной архитектуре агент действует как компилятор, собирая запрос на основе проверенных ограничений:
- Выбор (Карта): Semantic Graph однозначно определяет нужную таблицу, например,
my_company_data.revenueдля понятия «Продажи», исключая похожие, но нерелевантные таблицы. - Фильтрация (Рельеф): Shape Detector подтверждает, что в колонке
regionсодержится'NA', а не'North America', что гарантирует корректныйWHERE-фильтр. - Логика (Правила): Knowledge Object предоставляет точную формулу для метрики «Net Revenue», исключая произвольные вычисления.
Автор сравнивает этот подход с развитием автономных автомобилей, которые используют высокоточные карты (семантический слой) и данные с датчиков в реальном времени (определение формы) для безопасной навигации. Databricks утверждает, что переход к составным AI-системам, где модели управляются внешними валидными данными и инструментами, является единственным путем к достижению передовой точности в корпоративных приложениях [The Shift to Compound AI Systems].

Источник изображения: Google Gemini
От генерации к рассуждению: инженерный подход к семантическому слою
Эпоха «просто пообщаться с данными» заканчивается. Для создания агента, которому доверит данные даже CEO, необходимо рассматривать prompt не как магию, а как инженерную задачу. Семантический слой с «Just-in-Time» контекстом и слой определения формы, предоставляющий статистическую реальность, переводят LLM из состояния, когда модель должна «помнить» данные, в состояние, когда она «наблюдает» за ними.
Таким образом, агент перестает просто генерировать текст, а начинает рассуждать о данных на основе проверенных фактов и логики. В следующей статье серии «Cognitive Agent Architecture» будет рассмотрена архитектура оркестрации — Tool-Driven Backbone, которая позволяет агенту использовать эти инструменты в реальном времени.
Заключение и инсайты
Статья Шреяша Шуклы раскрывает фундаментальные ограничения современных LLM в корпоративной аналитике, связанные с недостатком семантического и статистического контекста. Предложенная архитектура, основанная на Enterprise Semantic Graph и Statistical Shape Detection, позволяет значительно снизить уровень ошибок (20-40% в text-to-SQL системах) и перейти к детерминированной генерации SQL-запросов.
Ключевые инсайты:
- Простое предоставление схемы данных (DDL) недостаточно для точного понимания данных LLM.
- Семантический слой, основанный на парсинге SQL ETL-скриптов, обеспечивает проверенную бизнес-логику и понимание происхождения данных.
- Статистическое определение формы данных предотвращает ошибки, связанные с неправильной интерпретацией колонок и значений.
- Архитектура «Just-in-Time» контекстного предоставления информации решает проблему «Context Rot» и «Raw Schema Fallacy».
- Такой подход обеспечивает трехкратное улучшение бизнес-результатов по данным IDC и сокращение времени доставки новых данных на 70% по прогнозам Gartner.
- Переход от генерации к рассуждению — ключ к созданию надежных и доверенных AI-агентов для бизнеса.
Данная статья является частью серии «Cognitive Agent Architecture», направленной на создание детерминированных, безопасных и эффективных корпоративных консультантов на базе AI. Полный роадмап и другие материалы доступны по ссылке: The Cognitive Agent Architecture: From Chatbot to Enterprise Consultant.

Автор статьи — Шреяш Шукла, Data Engineer в крупной технологической компании, эксперт в области инженерии данных и AI.
📢 Информация предоставлена телеграм-каналом: Data&AI Insights
🤖 Data&AI Insights - Ваш источник инсайтов о данных и ИИ