Этап "Группировка действий"
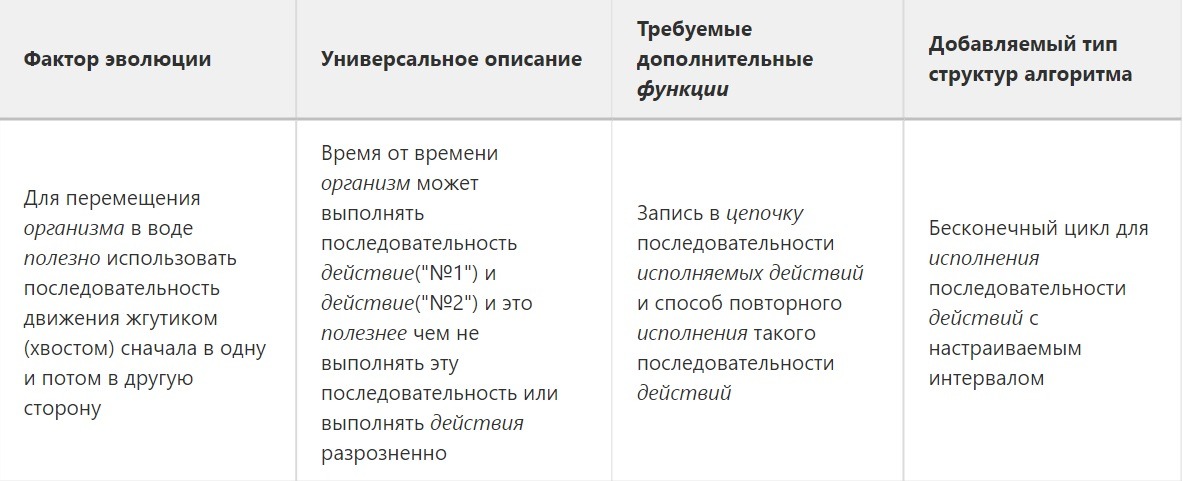
sergey shishkinИ если значение свойства Повторимости является дискуссионным в биологическом распознавании зрительных образов, то его использование для группировки действий сомнения почти не вызывает (хорошими примерами этого являются, например, способы заучивания человеком стихотворения или пьесы на фортепиано, последнее было рассмотрено в статье "Синтез алгоритма запоминанием"). Основа способа синтеза алгоритма, использующего последовательность действий, — это повтор эвольвером требуемой последовательности действий. Ранее у эвольвера мы рассматривали лишь одно действие, и он учился им пользоваться с пользой для себя. Такое ограничение было использовано намеренно (в угоду простоты описания вышеизложенных шагов развития). Давайте пожалеем эвольвер и снимем это ограничение.
И на этот раз нам снова нужен фактор эволюции, потребовавший от эвольвера группировки действий. Этим фактором стало наличие ситуаций, в которых большей полезностью обладает последовательность действий по сравнению с их одиночным исполнением.

Схема, конечно, красивая. Но есть сложности. Давайте разберем их по порядку.
Каким способом эвольвер подбирает действия к обнаруженной новой ситуации в среде?
Ответ на этот вопрос достаточно прост. Таким способом является то, что биологи называют игровой активностью. Справедливости ради стоит сказать, что не все аспекты игровой активности выделимы на рассматриваемом этапе развития эвольвера. Многие её важные компоненты необходимо рассмотреть отдельно (что запланировано сделать в главах, посвященных формированию коммуникации). Но основа игровой активности уже видна — это автоактивация эвольвером своих действий (обусловленная признаками и накоплением внутреннего потенциала) и выявление Повторимости сопровождающих признаков или получение результирующего подкрепления полезности(вредности).
После спонтанного выполнения действия у эвольвера есть два способа проверить полезность этого действия в пережитой ситуации. Первый способ привычный нам и хорошо проработанный научно — подкрепление от среды (или от учителя). Но есть и способ другой. И для его реализации нам снова на выручку приходит Повторимость. Этот способ помогает эвольверу определить, что исходная ситуация, описанная признаками, после воздействия исполненных действий трансформировалась в новую ситуацию. И признаки исходной ситуации, сопровожденные такими действиями, каждый раз приводят к признакам ситуации конечной. Выделив такой закон Повторимости развития ситуации, "игривый" эвольвер сохраняет цепочку-алгоритм даже не получив подкрепления пользой. И снова переходит в режим спонтанного поиска-синтеза новых алгоритмов поведения.
Где эвольвер хранит оценку полезности (вредности) запомненных действий?
В ответ на второй вопрос можно сделать несколько предположений о реализации способов запоминать уровни полезности от исполнения цепочки. Конкретный способ не сильно принципиален на текущем этапе работы. Видимо, самым легким решением является хранение этой оценки на стыке детектора признака исходной ситуации и макро-актора, обеспечивающего последовательность действий реакции. То есть во входном признаковом узле акторной области. Активация этого узла будет тормозиться, в случае если поведение запомненное эвольвером вредно, и тем самым обеспечит торможение последующих действий цепочки.
Каким образом эвольвер синтезирует цепочку последовательности действий?
Этот вопрос — самый простой из поставленных. Потому что мы на него уже почти ответили на этапе "Группировки признаков". Цепочку из последовательности действий эвольвер синтезирует в акторной области памяти.
Акторная область — локаль памяти, в которой запоминается последовательность активации узлов-акторов, отвечающих за старт исполнения действий, например, автоактивируемых эвольвером в игровом поведении.
Единственным (и не ключевым) отличием от группировки цепочки в детекторной области является связь рассматриваемых на этом этапе внутренних акторных узлов акторной области с инициализацией действий эвольвера.