Эрозия информации в OSINT: почему важно быстро действовать и как наверстать упущенное
netstalking_overgroundВольный перевод. Оригинал: https://nixintel.info/osint/the-attrition-of-information-in-osint-why-acting-quickly-matters-and-how-to-recover-when-you-dont/

Скорость - это критический фактор в любых расследованиях. Чем дольше информация игнорируется, тем вероятней, что она сотрется, исказится или вообще исчезнет. Так происходит с любыми данными, будь то показания очевидца происшествия, лог сервера, твит, отпечаток или что-то другое, полезное для расследования. Очевидец забывает, серверные логи перезаписываются, твиты удаляются, отпечатки стираются. Что бы вы ни расследовали, умение быстро собирать и сохранять информацию перед тем, как она исчезнет - важный скилл. Далее в статье мы подробнее обсудим эту идею и рассмотрим несколько техник, полезных для восстановления потерянной информации при случае.
Эрозия информации
Для понимания того, что называется эрозией, посмотрите на диаграмму ниже.

Красный прямоугольник отображает ситуацию идеального мира, в котором нам доступен каждый бит информации. Каждый пост на Фейсбуке публичный, каждое изображение расшарено в общий доступ, никто не удаляет твиты, Google индексирует всё что можно. Конечно, этот мир не существует, но при сборе информации через OSINT наша цель - быть как можно ближе к такому идеалу.
Оранжевый прямоугольник отображает информацию, которая реально доступна для исследователя. Мир не идеален, часть данных теряется: время идет, настройки приватности меняются, видео удаляются, сайты блокируют, ваша цель теряется в море результатов поиска, а очевидцы не хотят больше с вами говорить. Вы теряете при этом много информации.
Наконец, желтый прямоугольник - это объем информации, которая осталась в конце и оказалась полезна. Это материалы, позволяющие сделать выводы, написать статью, отчет о пентесте; которые можно приложить к юридическим документам или использовать в документалке. Между оранжевым и желтым прямоугольниками информация теряется по разным причинам: она становится устаревшей и нерелевантной, пропадает флешка, источники теряются, онлайн-инструменты перестают работать, хосты патчатся от уязвимостей и так далее.
Это сокращение доступных при OSINT-е данных между идеальным миром красного прямоугольника и реальной востребованностью желтого прямоугольника называется эрозией информации. Чем лучше вы умеете собирать и сохранять актуальную информацию через OSINT, тем эффективнее будут результаты, которые вы получите в конце. Расследование, которое не учитывает, как собирать и хранить данных, будет выглядеть вот так:

Из-за того, что первоначальный сбор и хранение информации оставляет желать лучшего (оранжевый прямоугольник), много теряется из-за эрозии, и конечные результаты расследования (желтый прямоугольник) намного слабее.
Пример: поиск Фьете Стегерса
Насколько много пятниц в этом году я потратил, отыскивая где Фьете Стегерс, я понимаю только сейчас, когда пишу эти строки. Фьете часто публикует задачки в пятничных челленджах Quiztime, и я собираюсь использовать один из его челленджей, чтобы проиллюстрировать как быстрый сбор информации предотвращает проблему эрозии.
Вы можете прочитать здесь мой изначальный пост, объясняющий как я нашел местоположение Фьете, а здесь я расскажу вкратце. Фьете опубликовал это фото с мероприятия, на котором он присутствовал:

Используя комбинацию лайв-фидов с Твиттера, данных по локации твитов и хэштегов с OneMillionTweetMap, Snapchat Map и Facebook, получилось найти Фьете довольно быстро. Этот метод в значительной степени зависел от недолговечных данных из различных социальных сетей, но благодаря быстрому сбору и сохранению (только скриншотов в этом случае) истощение информации было сведено к минимуму, что и помогло быстро найти решение.
Но на что был бы похож этот челлендж, если бы я попытался пройти его снова сейчас, 4 месяца спустя? Попытки смотреть лайв-фиды в Твиттере были бы бессмысленными, данные на Snapchat Map давно бы исчезли, а изменения в поисковом механизме Facebook привели бы к тому, что выяснить маршрут марша будет гораздо сложнее (если не вообще невозможно).
Мало того, что данные, на которые я первоначально полагался, больше не были бы доступны - были бы другие факторы, которые вызвали бы еще большую эрозию информации. Это был марш в защиту климата, но с момента съемки прошло уже много времени. Что означает появление миллионов результатов поиска, которые выдадут не то, что я искал, а более новые данные; что некоторые учетные записи в Твиттере были удалены и так далее. Пул доступной информации в первые несколько часов после того, как Фьете опубликовал вызов, был достаточным, чтобы найти его, но начать с нуля сейчас серьёзно усложнит задачу. Поэтому действия, быстро предпринимаемые для сбора и сохранения информации OSINT на ранней стадии, имеют значение для окончательного результата. Далее я расскажу, как это делать.
Сбор и сохранение данных OSINT

Необходимость предотвратить потерю доказательств не является чем-то исключительным в случае OSINT. Те же принципы сбора и сохранения информации в кратчайшие сроки можно увидеть на фотографии выше. Жизненно важные доказательства, такие как пятна крови, отпечатки пальцев, образцы волос и следы, имеют важное значение для раскрытия серьезных преступлений. Эти улики очень быстро разлагаются или теряются, поэтому хорошие следователи сохраняют их, чтобы предотвратить потерю. На снимке изображена лента с места преступления, которая предотвращает проникновение людей на место происшествия и загрязнение их судебно-медицинскими материалами из других источников или путем их уничтожения шинами проезжающих автомобилей.
Наиболее чувствительная из всех зона закрыта палаткой. Это не только для того, чтобы не пускать любопытных зрителей. Палатка защищает очень чувствительные улики для судебной экспертизы от дождя, ветра и других факторов, которые могут привести к потере ключевой информации. Если эта информация была утеряна или улики были повреждены с самого начала, дело может быть никогда не раскрыто.
В OSINT применяется тот же принцип. Если вы не соберете и не сохраните что-то в момент события или вскоре после него, то это теряется. В нашем мире "горячих новостей" материалы не только быстро забываются, но могут и искажаться другими, специально вносящими дезинформацию и заглушающими первоисточники. Отличным примером этого является Твиттер с его армиями ботов. Если первоисточники не будут быстро найдены, то они могут легко потеряться, и расследование сорвётся. В оставшейся части статьи мы рассмотрим несколько практически полезных инструментов, которые можно использовать для надежного и быстрого сбора информации из Интернета, а также несколько других инструментов, которые помогут вам вернуть информацию, которую вы могли упустить с самого начала.
Инструменты для хранения информации
Существует много инструментов, которые вы можете использовать для быстрого и эффективного сбора информации. Выбор инструмента для использования зависит от того, что именно вы пытаетесь сохранить. Для примера рассмотрим несколько разных типов.
Скриншот, снимок экрана - существует огромное количество приспособлений для этого. Fireshot работает как расширение браузера, в Windows встроены Ножницы, в Mac OS есть встроенный инструмент Screenshot, а мои любимые инструменты для Linux - это Shutter и Flameshot. В Firefox теперь есть встроенный скриншотер как в Vivaldi.
Сохранение веб-страницы - GIJN опубликовали руководство по различным способам сбора информации из Интернета. В него входит напоминание, что вы можете просто нажать Ctrl+S и сохранить веб-страницу в виде HTML-файла. Конечно, это можно сделать, но большинство современных веб-страниц содержат так много динамического контента, что HTML-страница, сохраненная в автономном режиме, может быть не очень похожа на исходную страницу. HTTrack - гораздо более эффективный способ сохранить веб-страницу, но я еще к этому вернусь.
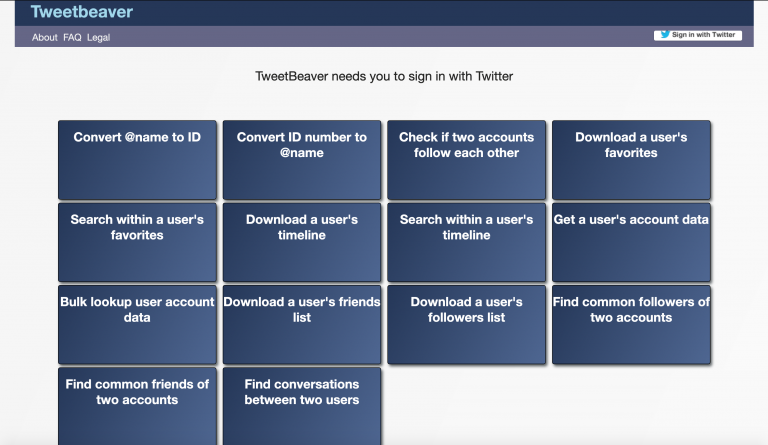
TweetBeaver - содержит несколько инструментов, которые позволяют загружать выбранную информацию из Твиттера и экспортировать ее в формате CSV. Правда, сначала нужно разрешить ему доступ к вашей учетной записи, но это отличный способ выгрузки массовой информации с простым пользовательским интерфейсом.
Twint - мой любимый инструмент для Твиттера. Он не использует API, но реально мощный. У него есть много функций для сбора определенных видов информации, а еще интеграции с распространенными инструментами визуализации. На скриншоте ниже перечислены некоторые из доступных опций:

Кстати, Бенджамин Стрик недавно проделал большую работу в OSINT, чтобы показать, на что способен Twint.
Archive.is - "капсула времени" для веб-страниц. Он не так известен как The Internet Archive и не содержит столько же копий, но можешь помочь быстро сохранить нужное. Просто введите URL-адрес страницы в красном поле, и Archive.is скопирует и сохранит его. Удобный инструмент для оперативных действий.
Прим. пер.: archive.is также полноценный и полезный источник архивных копий, там есть много такого, что не сохранено на web.archive.org.

Pastebin - очень простой инструмент для сохранения текста, когда по какой-то причине неудобно сохранять его локально. Просто скопируйте и вставьте текст, который вы хотите сохранить, и Pastebin создаст уникальный URL, который можно добавить в закладки. Только помните, что сохраненные пасты не закрыты от чужих глаз.

HTTrack - действительно мощный инструмент для сохранения сайтов. Он копирует всю структуру веб-сайта или страницы и сохраняет её в офлайн-виде. Это более эффективно, чем просто сохранить веб-страницу в виде HTML-файла, поскольку выкачиваются все связанные скрипты и таблицы стилей, необходимые для функционирования страницы. Фактически, это позволит вам создать точную копию веб-сайта для просмотра без интернета. Единственный недостаток заключается в том, что захват всего сайта занимает больше времени, когда вы копируете все страницы постранично или делает скриншоты, но результат может того стоить. Программа есть как для Windows, так и для Linux. Хорошое руководство можно найти здесь.
Прим. пер.: если цель действительно в том, чтобы максимально точно выкачать все связанные ресурсы, то стоит посмотреть в сторону wget - незаменимого консольного инструмента для скачивания информации из Сети.
YouTube-dl - это до сих пор мой любимый инструмент для сохранения видеоконтента практически с любой страницы (не только с YouTube, как следует из названия). Я написал здесь базовое руководство, которое показывает, как скачивать видео практически с любого веб-сайта. В этом руководстве я использовал консольную версию утилиты, но здесь также доступна версия с графическим интерфейсом.

Hunchly - лучший инструмент для сбора информации через браузер. Он незаметно сохраняет данные в фоновом режиме, когда вы сёрфите: скачивает веб-страницы, видео, поисковые запросы, делает скриншоты и так далее, создавая воспроизводимый путь расследования, которое вы провели. Это стоит $ 129 за год лицензии, но если вы занимаетесь OSINT профессионально или даже в качестве хобби, за это стоит заплатить. Он также одинаково хорош на Windows, MacOS и Linux.

OSIRT – менее известен, чем Hunchly, но все равно довольно хорош. Он сохраняет данные, которые вы просматриваете, имеет встроенный инструмент записи видео, возможность сохранения веб-страниц, функциональность для Tor, позволяет вам добавлять свои собственные заметки по делу и экспортировать все это в виде PDF. Первоначально он был разработан для правоохранительных органов, но теперь доступен для всех (только для Windows).
Инструменты для восстановления информации
Одно из основных различий между интернет-расследованиями и обычными расследованиями заключается в том, что восстановить потерянную информацию намного проще. Если кто-то случайно сотрёт отпечаток пальца на месте убийства, то он исчезает навсегда, но если кто-то удаляет твит, то может быть способ вернуть его обратно. Вот список нескольких ресурсов, которые могут дать вам возможность восстановить информацию, которую вы упустили.
Google Cache - Google не только индексирует веб-страницы, но и сохраняет их копии в кэше, чтобы затем можно получить кэшированную версию веб-страницы, даже если оригинал был удален. Только вам нужно помнить, что Google не все время кэширует. Чтобы увидеть такую копию веб-страницы, просто добавьте к URL, который вы ищете, префикс cache:. В недавней статье я искал старую статью Джейка Крэпса о Pastebin, на которую я хотел сослаться. Google нашел оригинальный твит...

Но когда я нажал на него, то обнаружил, что Твиттер ограничил аккаунт Джейка, и я не смог просмотреть сообщение:

Однако, добавив к URL-адресу префикс cache: и выполнив поиск в Google:
cache:https://twitter.com/jakecreps/status/1126239101294919685
Google вернул кэшированную версию, хотя исходная версия исчезла:

Вы также можете получить доступ к кэшированным версиям веб-страниц непосредственно из результатов поиска, нажав зеленую стрелку вниз и выбрав «Сохраненная копия» или «Cached».

Если этот параметр отсутствует, к сожалению, страница не была закэширована.
The Wayback Machine - Archive.org - это, пожалуй, самый известный архивный ресурс в Интернете. У него есть копии веб-сайтов на протяжении десятков лет, и я уже потерял счет случаям, когда он меня выручал при попытке найти удаленный контент. К него также есть широкий спектр расширенных параметров поиска старой и неясной информации. Несмотря на то, что это отличный инструмент, он не делает копии регулярно и не очень удобен для сохранения URL-адресов с быстро меняющимся контентом, таким как твиты.
Ceddit и Resavr - эти два инструмента сохраняют удаленные сообщения с Reddit. Ceddit выглядит как сам Reddit, но он при этом архивирует сообщения, которые были удалены из него.

Resavr использует немного другой подход. Он просто сохраняет удаленные комментарии из Reddit. Вы можете получить полный текст комментария, информацию об авторе, когда он был удален, и сколько времени прошло до его удаления.
Прим. пер.: для РУ также актуальны инструменты для сохранения удалённых статей с Хабра. Это сайты savepearlharbor.com, habrparser.blogspot.com и itnan.ru. Бывший некогда удобным sohabr.net уже не работает.
Поиск по временным рамкам - это несколько иной подход к восстановлению потерянной или скрытой информации. Как я упоминал ранее в этой статье, одной из причин эрозии информации в OSINT является то, что искомые данные могут быть засыпаны новыми результатами. Например, если загуглить по «Jeffrey Epstein», то можно получить 70 миллионов результатов.
Недавние сексуальные преступления Джеффри Эпштейна, которые закончились его самоубийством, гарантируют, что результаты, связанные с этим событием, будут доминировать в результатах поиска. Но что если мне было интересно изучить более старую информацию о нем? Расширенные параметры поиска Google позволяют вам находить результаты только за определенный период времени, что может значительно облегчить поиск искомого.
На странице результатов поиска выберите «Инструменты», затем нажмите «За всё время» и выберите «За период...» из выпадающего меню:
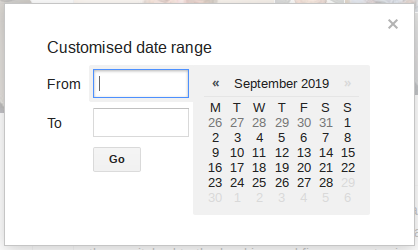
Введите интересующий вас диапазон дат, и Google вернет результаты только за этот период. Это позволяет отфильтровывать много шума в результатах поиска и просто сосредоточиться на интересующем периоде времени. Не забудьте использовать полные годы (ГГГГ), а не только две последние цифры (ГГ); и помните о формате даты США (MM/ДД/ГГГГ).
В качестве примера посмотрим на результаты поиска для Джеффри Эпштейна только за 2009 год:

Это дает много старых результатов поиска без ссылки на недавние скандалы и его смерть:

Если вам нужны точечные результаты, то вы можете установить еще меньшие временные рамки, даже до одного дня. Только имейте в виду, что это может привести к ложным срабатываниям, поскольку на очень старых сайтах появляется относительно свежая информация. Как всегда, всё проверяйте.
Этот список не является полным, но если есть какие-то ресурсы, которые, по вашему мнению, я должен добавить, напишите мне в Твиттер.