Доверяй, но проверяй доверительным интервалом
@just_data_scienceВова и Гена прочитали предыдущую статью и решили провести А/Б-тесты своих интернет-магазинов. Вова тестировал новшество: окошко, не дающее закрыть сайт, пока не сделаешь покупку. Тест Гены был более скучный: зачеркнутая завышенная на 300% цена рядом с настоящей. Ребята пустили 50%/50% на старую/новую версию, и сравнивали, насколько у них выросли покупки.
Уже через день стало ясно, что результаты Вовы просто феноменальны: из 1000 посетителей новой версии 15 сделали покупку, в то время как в старой - 10 покупок. А значит прирост аж 50%! У Гены же за этот день в новой версии покупателей стало даже меньше на 10%, чем в старой. Вова, дружески подтрунивая над Геной, срочно переключил все 100% трафика на новую версию, закупил рекламы по максимальной цене, и тут же укатил отмечать свой успех на Мальдивы.
Вернувшись через неделю, Вова обнаружил следующее. Гена, который всё еще продолжал А/Б тест, получил, что его изменение дало за весь период прирост конверсии +20% по сравнению со старой версией. А вот Вовин магазин разорился: все деньги ушли на рекламу, но из 10000 пришедших по дорогущей рекламе человек - только 100 сделали покупку, вместо ожидаемых 1500.
Ужасная история! В чем же дело?
Вообще-то всё дело в том, что магазин Вовы на следующий же день попал в черные списки антивирусов и файрволов за такой "чернушный" приёмчик. А из поисковиков - наоборот пропал. Поэтому многие посетители, кликнувшие по рекламе, просто не доходили до собственно сайта. Но мы же пишем про датасайнс (а значит - и матстатистику), поэтому забудем про эту версию.
Дело в том, что Вова и Гена прогуливали уроки математической статистики. Через день после начала А/Б теста у них были результаты с крайне низкой точностью, проще говоря - случайные. Количество посетителей, пришедших за это время, было недостаточным, чтобы делать выводы "конверсия изменилась на ...%". Ведь каждая конверсия посетителя в покупку - случайна: из одной 1000 посетителей купит 10 человек, из другой - 20, из третьей - 5 и т.д. И может получиться что 15 или 10 покупок с 1000 - в пределах случайности.
Чтобы понять, достаточно ли точно произведены измерения, используют понятие доверительного интервала.
Что такое доверительный интервал?
Доверительный интервал - это мера оценки точности и надёжности каких-либо случайных измерений. Это такой интервал, что настоящее среднее значение (а не предположенное на основе случайных измерений) попадает в него с высокой вероятностью (коэффициентом доверия).
Обычно точность доверительного интервала берут с коэффициентом доверия 95% (в расчете что "уж в 5% вероятности вряд ли попадём", но случается и такое).
Чем шире доверительный интервал - тем менее точные результаты измерений. Чем он уже - тем больше можно доверять выводам, которые сделаны по результатам замеров.
Но вернемся к Вове!
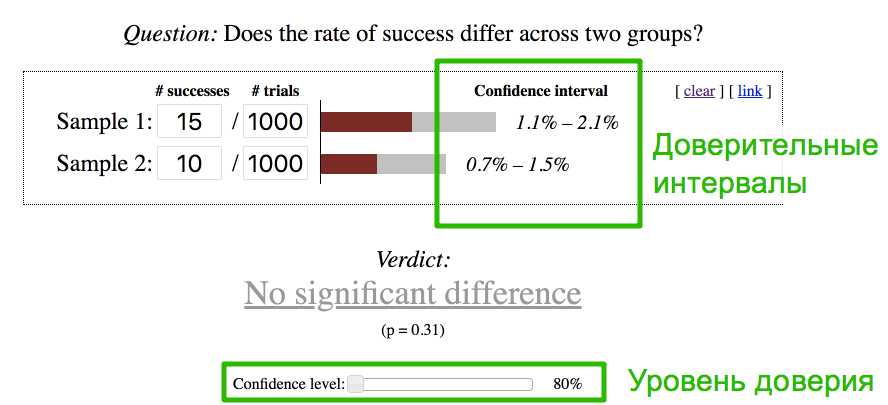
Вернемся к Вове. В формулы погружаться не будем, воспользуемся одним из онлайн-калькуляторов , коих множество. Введем результаты А/Б теста Вовы, поставим уровень доверия да даже 80% (вместо стандартных 95%) и получаем, что нет доверия к результатам его А/Б теста - разница между конверсиями версий статистически незначима. Доверительный интервал старой версии с 10 покупками - пересекается с доверительным интервалом новой с 15 покупками. А значит лучшая конверсия - может быть случайным совпадением, что и оказалось через неделю.
И как же теперь проводить А/Б тесты?
Нужно заранее посчитать количество посетителей, необходимых для теста - на основе имеющейся конверсии. И далее сравнивать результаты только после достижения этого количества. Если разница между версиями статистически значима - значит станет ясно, какая скорее всего лучше, если нет - значит новшество скорее всего ни на что не влияет.
Если уж это считать лень даже через онлайн-калькуляторы, то можно поступить как Гена - тестировать подольше. Главное - не прерывать тестирование сразу же, как только разница между версиями стала статистически значимой! Держите эксперимент дальше, чтобы убедиться, что существенная разница между версиями не случайность, а стабильность.
Вместо послесловия
В прошлой статье упоминалось, что наиболее качественный способ проводить А/Б тесты - разделять трафик на 3 части: две равные группы и одна небольшая контрольная. Обычно делят 45/45/10 между старой/новой/старой версией. И тестировать нужно на таком количестве трафика, чтобы результатам контрольной группы можно было доверять.
Тогда результатам основных групп можно доверять с очень высокой долей вероятности, но только при условии, что результаты контрольной и основной старой групп - перескаются доверительными интервалами. То есть - результаты этих двух групп близки друг к другу. Если же нет - значит эксперимент проводился или измерялся некорректно, погрешность оказалась выше предполагаемый, и принимать решения на его основе нельзя ¯\_(ツ)_/¯