До первого исследования: как осознать, поделить и посчитать самых разных пользователей и заодно сплотить команду
Лена БулыгинаГоворят, чтобы успешно двигать стартап, надо любить проблему, в продуктовые команды идут от продуктовой любви, а чтобы заниматься дизайном в консалтинге, надо любить процессы. И хорошо их понимать, не посвящая себя ни продукту, ни проблеме.
Часть UX-процессов в нашем агентстве налажена и обкатана почти безукоризненно — я сама иногда удивляюсь, что мы ведём наших клиентов (а не наоборот), коллаборируемся вместе с первого дня, имеем набор практик на случай внезапного мистера Василия Ивановича с важным мнением через две недели после старта, топим за методологию, еженедельно имеем внутренние практики обмена знаниями и практик. Но некоторые вещи приходится моделировать самостоятельно, наверное так формируется мастерок из приёмов лидерства, не знаю. Знаю только что он у нас у каждого разный.
Как показывает моя практика, сложное препятствие в начале — с чего начать, буквально. Особенно если клиент говорит, что продукт у них «для всех», уже многое известно и они знают, чего хотят. Похожее может быть актуально и для первого рисёчера в стартапе, и для продуктовой команды, потерявшей фокус. Если вы работаете в технологической компании с налаженными продуктовыми процессами и командой хороших дата-сайентистов — тут можете снисходительно улыбнуться, я вам очень завидую в этом вопросе, приходя на новый проект к лидерам индустрий, у которых и сбор данных, и сегментация в зачаточном состоянии. Но всем время от времени полезно посмотреть новым взглядом в свою аудиторию.
Так одна задача на самом деле мутирует в несколько: понять, с чего начать работу, проверить существующие предположения и предыдущую сегментацию, оценить, что есть, а чего не хватает, и создать новые смыслы с командой, заодно узнав чужие политические интересы. Это может проясниться через процесс, где мы сначала заглянем в бездну данных, а потом поработаем зеркалом вместе с командой.
Новый взгляд на существующие данные
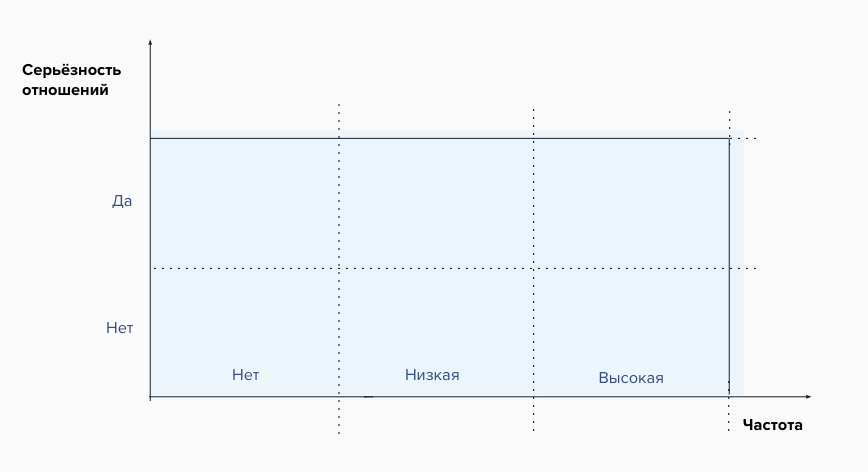
Сначала мне помогает сделать сегментацию по двум осям — выйдет матрица 2х3. Одна из них — частота, вторая — «серьёзность отношений», так я перевожу commitment. Это две метрики текущего поведения, которые напрямую связывают людей и бизнес, но при этом отражают пользовательское поведение. Что они значат для каждого отдельного бизнеса, проекта и сервиса, я выбираю сама и утверждаю с клиентом.
- Частота — может быть транзакция или покупка, а может быть частота логинов, или любое другое важное обращение к сервису за единицу времени. Единица времени тоже выбирает в зависимости от контекста, на каких-то проектах это может быть неделя, а для больших циклов и полгода (например, страховка).
- Серьёзность отношений лучше всего меряется деньгами (как всегда!) — бесплатные и платные пользователи, использование продукта как основного и резервного, но это может быть и наличие карты лояльности или определённого статуса в ней. Или можно подумать о ещё более неортодоксальных сигналах серьёзности — например, для Notion это может быть количество пользователей, которые туда переехали из Evernote.
После того, как сигналы и метрики установлены, хорошо прикинуть, сколько каждой категории в пользователях, составить карту предыдущих исследований и их надёжности, понять, какие сегменты недоизучены, где самые опасные предположения и меньше всего знаний. Так вы не начинаете с чистого листа, а заодно это упражнение поможет понять, какие данные уже есть и собираются, сразу подумать, как можно настроить сбор других данных, возможности для итераций и заложить базу под рекрутинг и опору для всей будущей работы. Результаты пока приберегите, они понадобятся вам после второй части поста.
Сегментация с командой
Дальше я стараюсь собрать большую команду на воркшоп, включая девелоперов и службу поддержки, хотя бы на полчаса обязательно всех, кто будет принимать решения. Заранее пишутся строгие правила участия, присутствия и поведения, а также последствия.
Каждому человеку выдаётся кусок виртуальной доски и задание перечислить как минимум пять пользовательских групп. Например, приложение для рецептов может включать в себя занятых родителей, хардкорных зож-ников и угоревших по выпечке сдобы. Инфрапортал может быть собран из групп «милый мой бухгалтер», «коллеги, которые заходят только по принуждению», «охрана, отмена» и тд.
Одной из проблем таких разношерстных воркшопов часто бывает зажатость и скованность участников. Кто-то боится сказать лишнее и выступить идиотом перед руководством, кто-то чувствует себя не в своей тарелке. Я вижу своей ответственностью убрать эти шероховатости. Вот набор вопросов, которые помогут сдвинуться с места кому угодно:
- Кто «обычный» пользователь продукта? Сколько разных групп?
- А кто их противоположность?
- Насколько разные люди могут использовать наш продукт? Как их потребности и цели отличаются?
- Что мы знаем о разных контекстах использования? На каких надо сконцентрироваться сейчас?
- Есть ли у нас early adopters? Кто использовал продукт до других?
- Есть ли у нас power users? Как мы их опишем или категоризируем?
- Есть ли кто-то, кто использует продукт только по принуждению, не имея альтернативы? (гос услуги, выигранный тендер etc)
- Кому с нашим продуктом сложно?
- Какие пользователи/группы лучше всего соотносятся с бизнес-целями? Почему?
- О ком мы знаем меньше всего?
- К каким пользователям проще всего получить доступ?
- Есть ли группы пользователей, которые сами идут навстречу и готовы говорить?
После удаления дубликатов, разложите вместе ответы по следующей матрице 2х2:
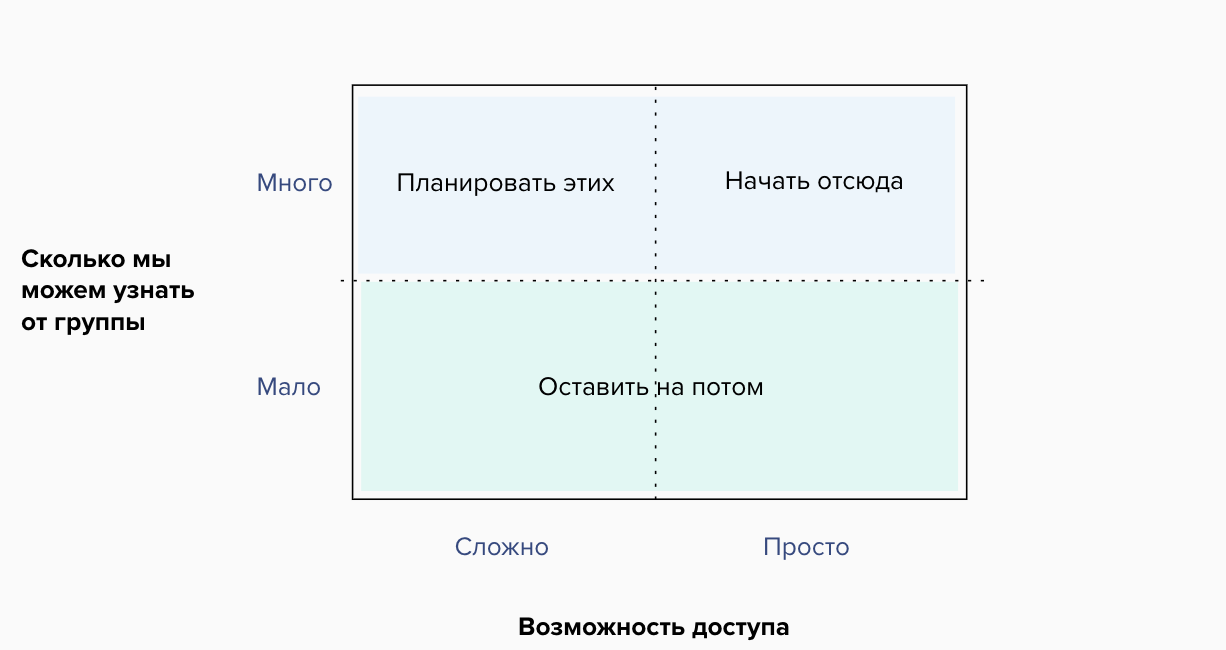
- Вертикальная ось: полезность группы для исследований. Наша цель сейчас — проверить самые большие риски для бизнеса и прояснить предположения, и не все группы пользователей будут одинаково полезны, поэтому их можно разделить на две части.
- Горизонтальная ось делит всё по лёгкости доступа к людям. Часть пользователей могут быть на высоких должностях, а часть — в других часовых поясах, а часть может быть узкоспециализированной и немногочисленной. Мы никого не игнорируем, но надо быть реалистичными в том, что можно сделать здесь и сейчас.
Дальше мы обсуждаем каждый квадрант, где полезные и легкодоступные пользователи становятся приоритетом номер один, полезные, но сложные — следующими за ними. Важно понять, что в этот момент создаётся общий язык и ощущение общей работы. Участники воркшопа вполне могут кого-то пропустить и спорить под влиянием своих когнитивных искажений, цель этого — сделать так, чтобы все почувствовали себя услышанными и понятыми, но финальные выводы и ответственность всё равно за вами.
После того, как все вроде как договорились, самое время достать результат сегментации «по дате» из первой части, и посмотреть вместе на сходства, различия, и возможные упущения. Здесь вам лично станет чуть больше понятно о каждом участнике проекта и, скорее всего, станет проще двигаться дальше.
Эти два вроде как простых упражнения помогают мне пробиться через дебри и шум, сформировать общий язык и подход, игнорировать часть скользких политических моментов и проясняют, с чего начать-то.